spark.mllib源码阅读-优化算法1-Gradient
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-优化算法1-Gradient相关的知识,希望对你有一定的参考价值。
Spark中定义的损失函数及梯度,在看源码之前,先回顾一下机器学习中定义了哪些损失函数,毕竟梯度求解是为优化求解损失函数服务的。
监督学习问题是在假设空间F中选取模型f作为决策函数,对于给定的输入X,由f(X)给出相应的输出Y,这个输出的预测值f(X)与真实值Y可能一致也可能不一致,用一个损失函数(lossfunction)或代价函数(cost function)来度量预测错误的程度。损失函数是f(X)和Y的非负实值函数,记作L(Y, f(X)).
统计学习中常用的损失函数有以下几种:
(1) 0-1损失函数(0-1 loss function):

(2) 平方损失函数(quadraticloss function)
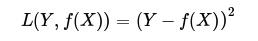
(3) 绝对损失函数(absolute lossfunction)
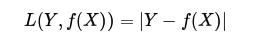
(4) 对数损失函数(logarithmicloss function) 或对数似然损失函数(log-likelihood loss function)

(5)间隔损失函数(hinge loss)

在不考虑过拟合的情况下,损失函数越小,模型就越好。
Spark中定义梯度和损失函数求解的类包括一个Gradient基类及其三个实现类:
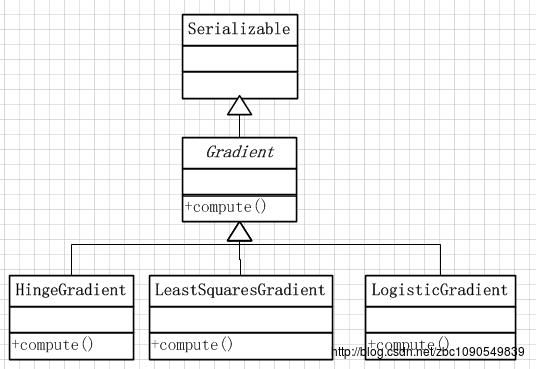
Gradient
梯度计算的抽象类,定义了计算梯度值和损失函数值的compute函数:
def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) =
val gradient = Vectors.zeros(weights.size)
val loss = compute(data, label, weights, gradient)
(gradient, loss)
后面的梯度计算类都继承子Gradient类并实现compute函数。
LeastSquaresGradient
实现了最小二乘法进行线性回归的梯度计算方法。
其对compute函数进行的覆写
override def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) =
val diff = dot(data, weights) - label
val loss = diff * diff / 2.0
val gradient = data.copy
scal(diff, gradient)//常数乘以向量 更新后的gradient即为梯度 gradient=(y - lable)* x
(gradient, loss)
使用场景:
1、 参数估计的方法是最小化误差的平方和,其它估计方法不适合用此梯度算子。
2、 Spark实现的是线性回归的梯度计算,非线性回归的梯度计算不适合使用此算子。
HingeGradient
实现了最大化分类间距的hinge loss进行参数估计的梯度下降方法,对compute函数进行的覆写:
class HingeGradient extends Gradient
override def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) =
val dotProduct = dot(data, weights)
// Our loss function with 0, 1 labels is max(0, 1 - (2y - 1) (f_w(x)))
// Therefore the gradient is -(2y - 1)*x
val labelScaled = 2 * label - 1.0
if (1.0 > labelScaled * dotProduct)
val gradient = data.copy
scal(-labelScaled, gradient)
(gradient, 1.0 - labelScaled * dotProduct)
else
(Vectors.sparse(weights.size, Array.empty, Array.empty), 0.0)
使用场景:
适用于利用最大化分类间隔思想来构建分类器,典型的使用如SVM。
LogisticGradient
使用对数似然损失函数对Logistic分类/回归进行参数估计的梯度下降方法。实现的代码比较长,在此就不贴了,在内部分了2分类和多分类两种情况进行计算。
以上是关于spark.mllib源码阅读-优化算法1-Gradient的主要内容,如果未能解决你的问题,请参考以下文章