Foundations of streaming SQL
Posted vinoYang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Foundations of streaming SQL相关的知识,希望对你有一定的参考价值。



借助于流表二象性来理解流与表的相对性:
streams -> tables:一个关于变更的数据流随着时间聚集产生了一个数据表;
tables->streams:对一个表的变更的观察,伴随着时间的变化产生了一个数据流(observation这一过程,体现了离散的概念);

非相对论的流&表定义:
表是静态的数据
流是动态的数据


Beam的模型:抽象出数据处理的四个核心问题(要素);
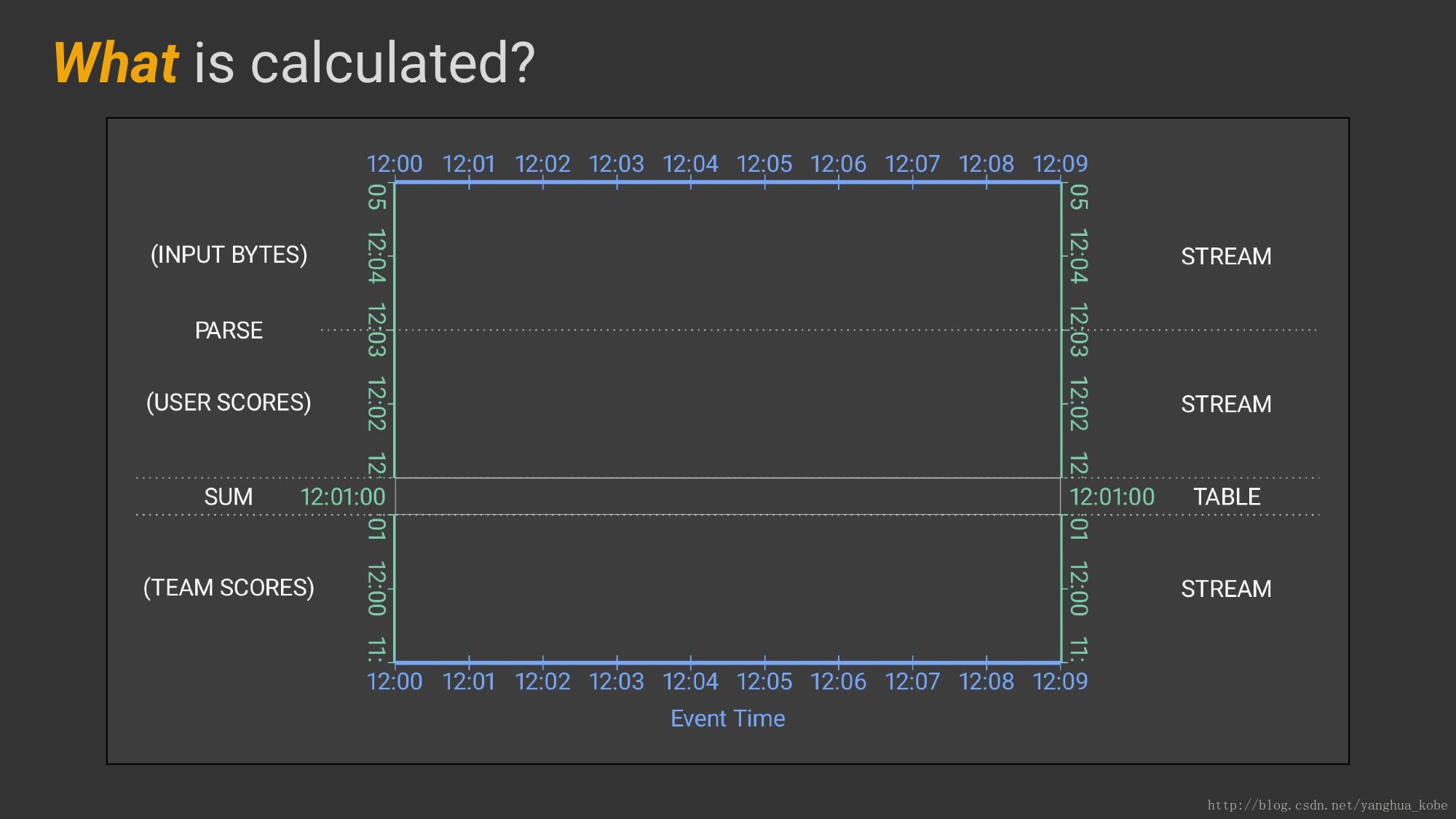
what: 计算得到什么结果?选择算子和思考算子计算逻辑的过程;
where: 对于事件时间而言,在哪里进行计算?窗口
when: 什么时候触发结果输出?触发计算,输出结果
how: 如何细化结果相关性?提前累加/计算

在Beam模型中,使得流和表如何变得更协调:
批处理如何适配所有的这些语义/概念;
流跟有界的和无界的数据集是什么关系;
上页的四个问题如何映射到流/表的体系中?

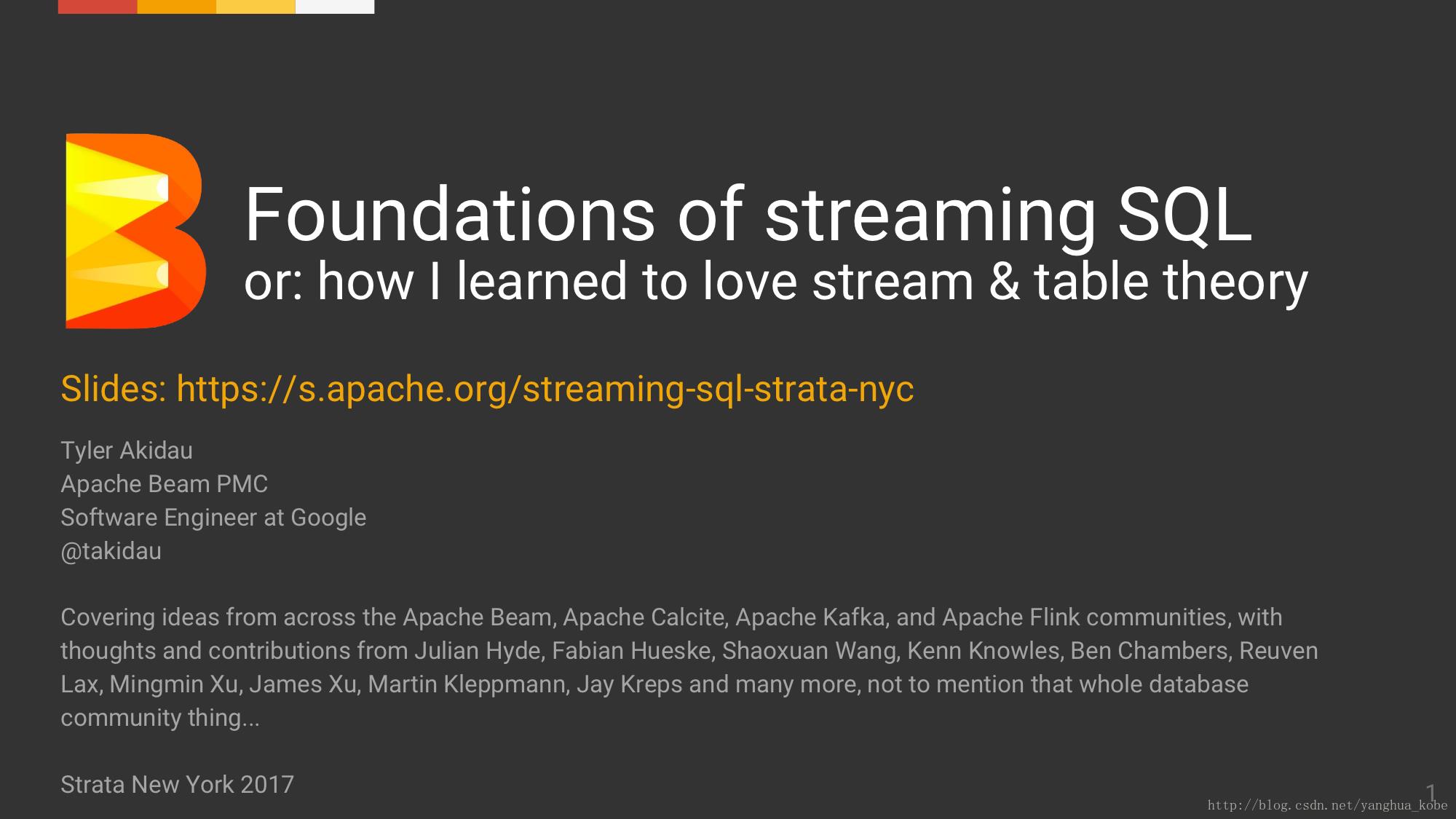
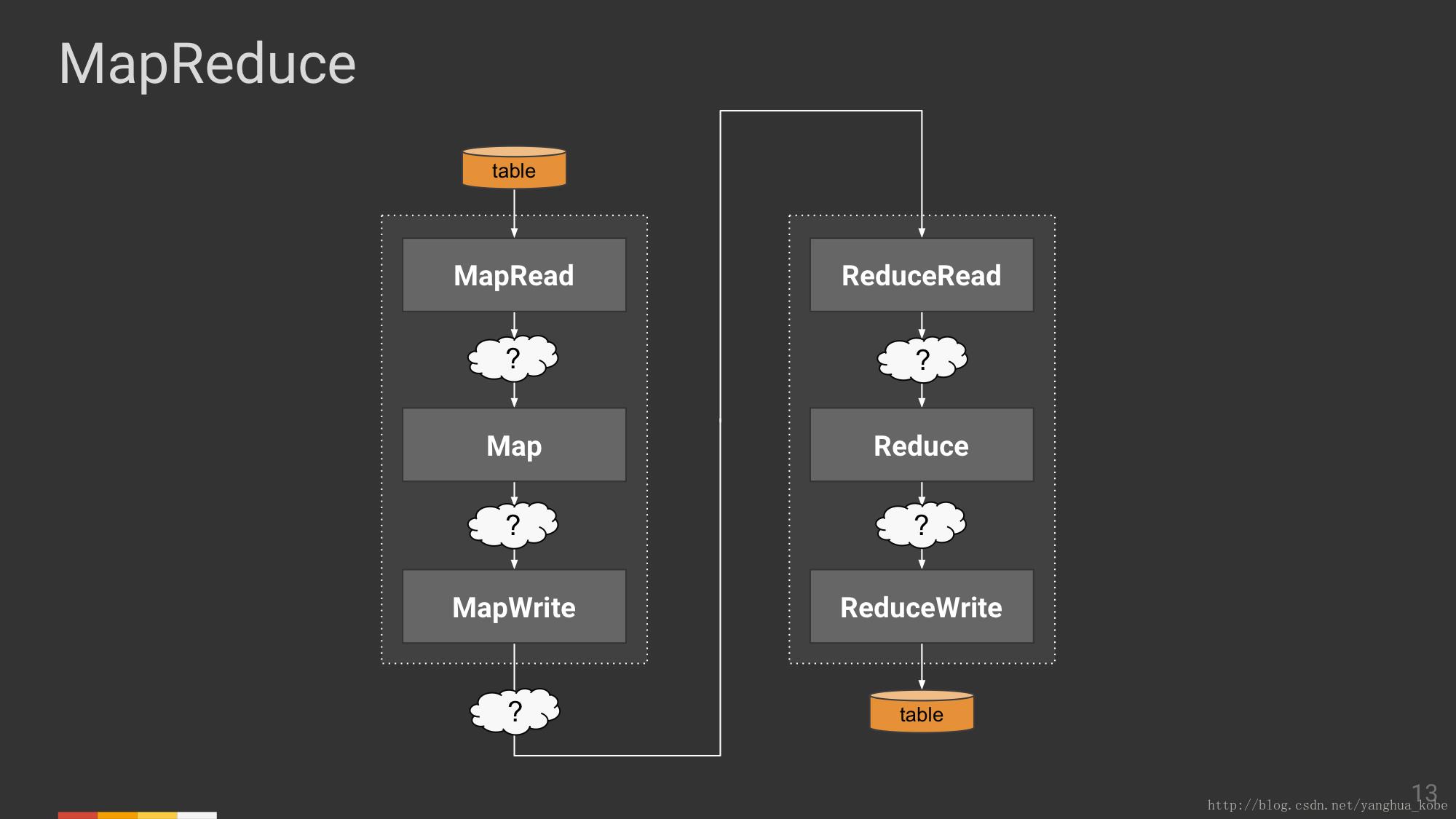
从MapReduce入手,抽象来看,是一个从输入->Map运算->Reduce运算->输出的过程;
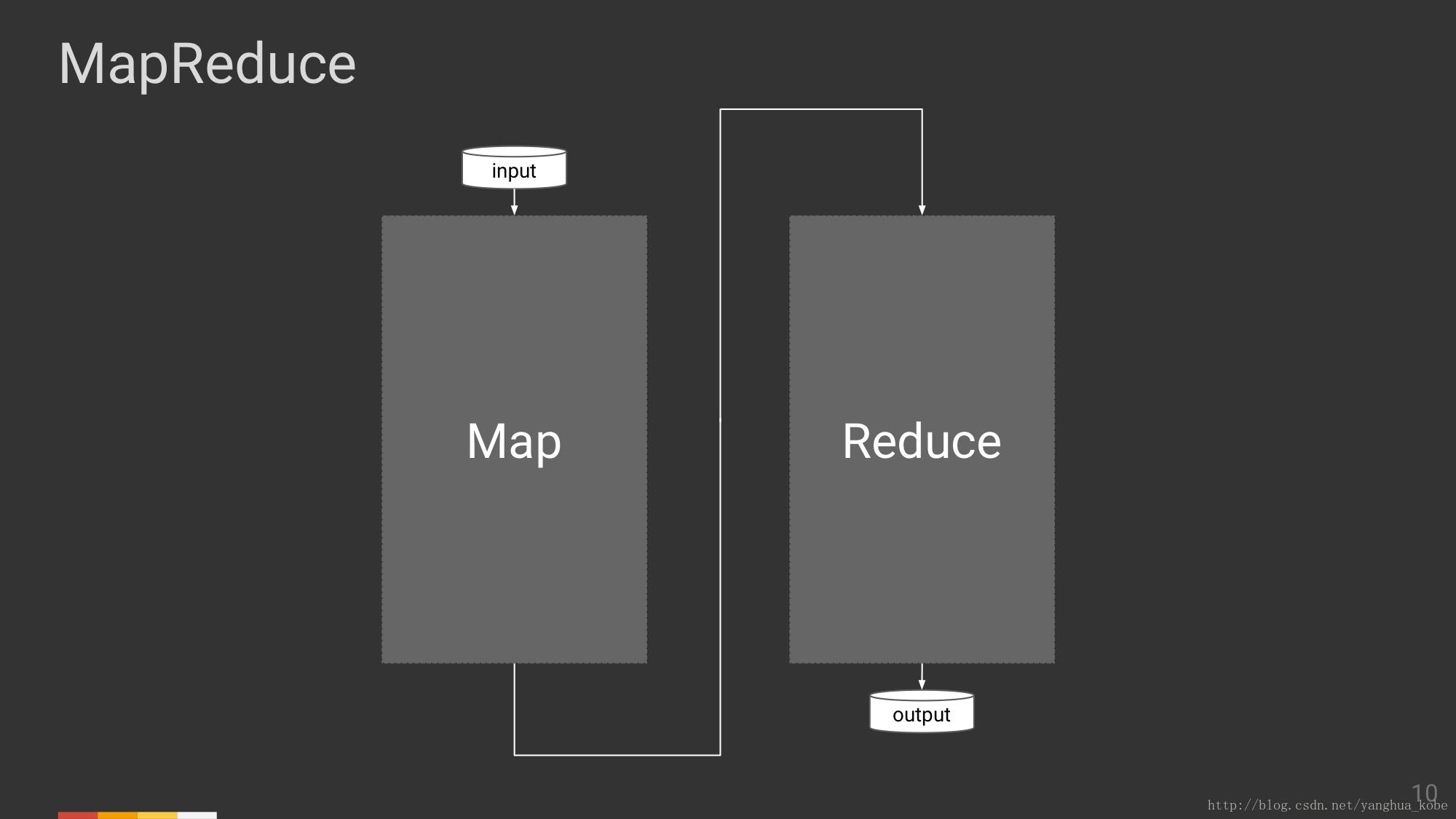
Map/Reduce两个算子,细分一下每一个都会经历:读->计算->写的过程,图中的箭头,其实也不是一个具体的东西,它只是代表了数据的流向或者数据交换。下一页我们将会看到~
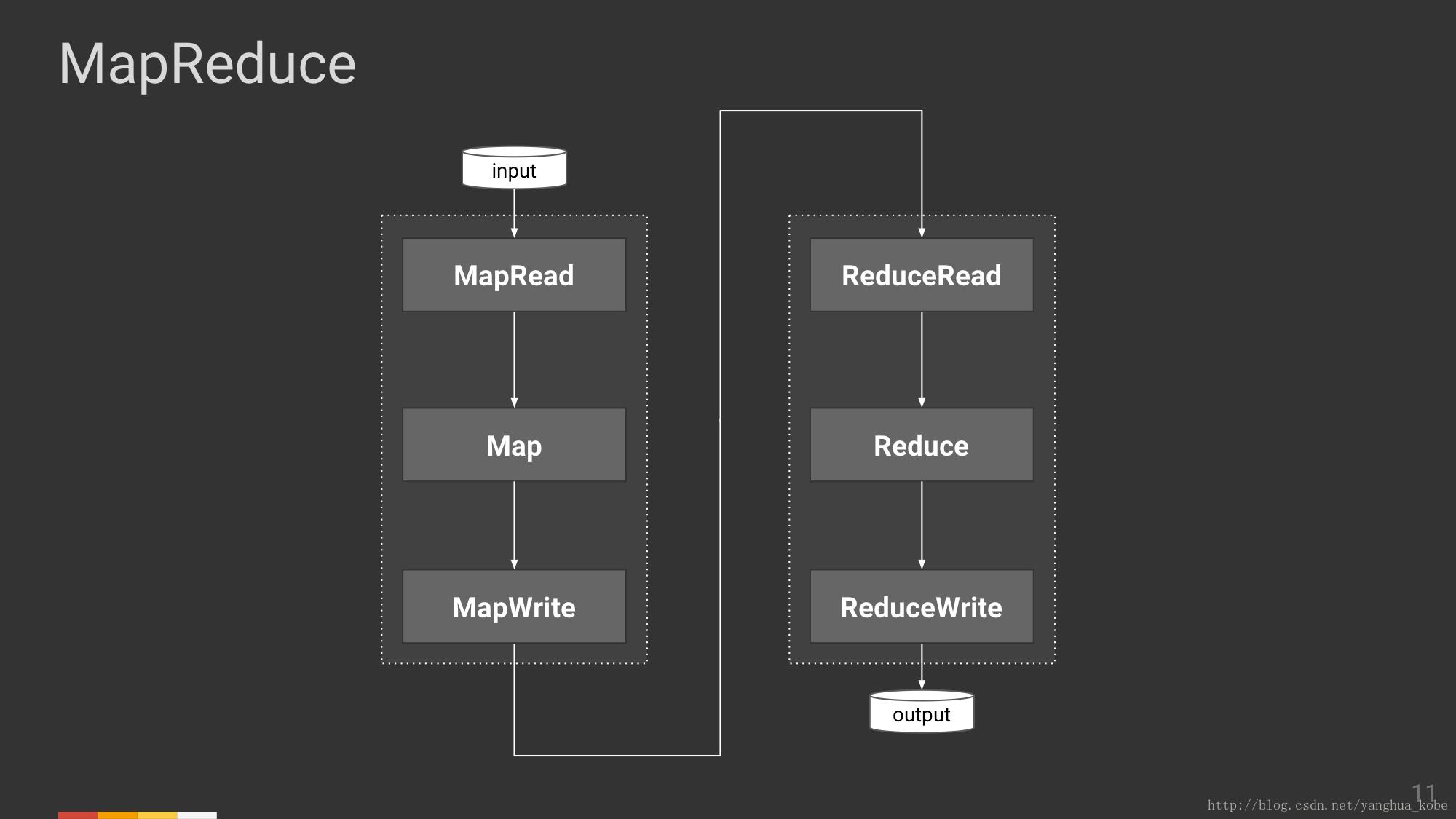
数据的流动、交换也是一种抽象,接下来将会经历一个具体化的过程。
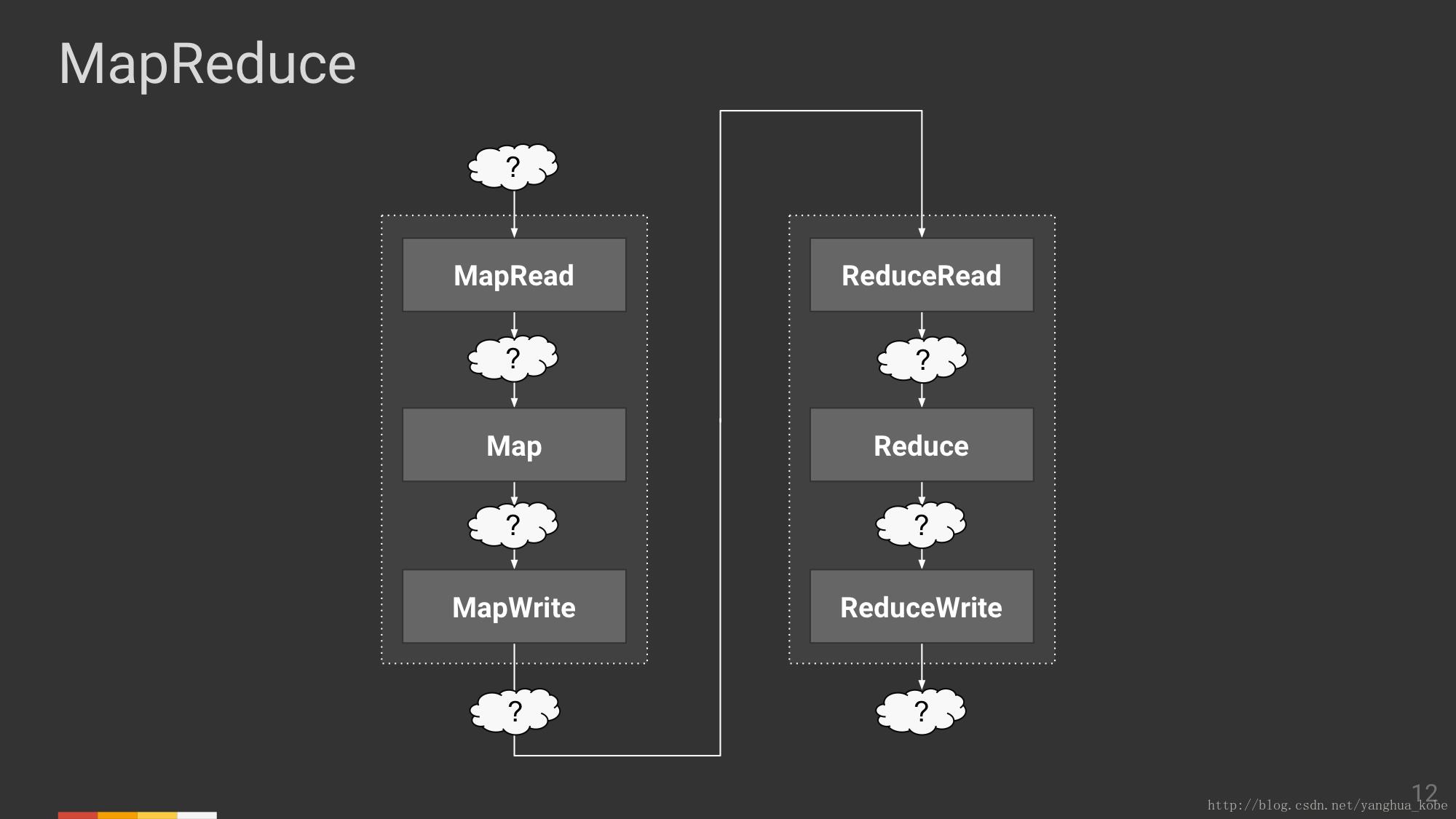
先确定计算模型整体的输入和输出,按照之前对流/表的定义,其可以被先被确定为表(表是静态的数据)
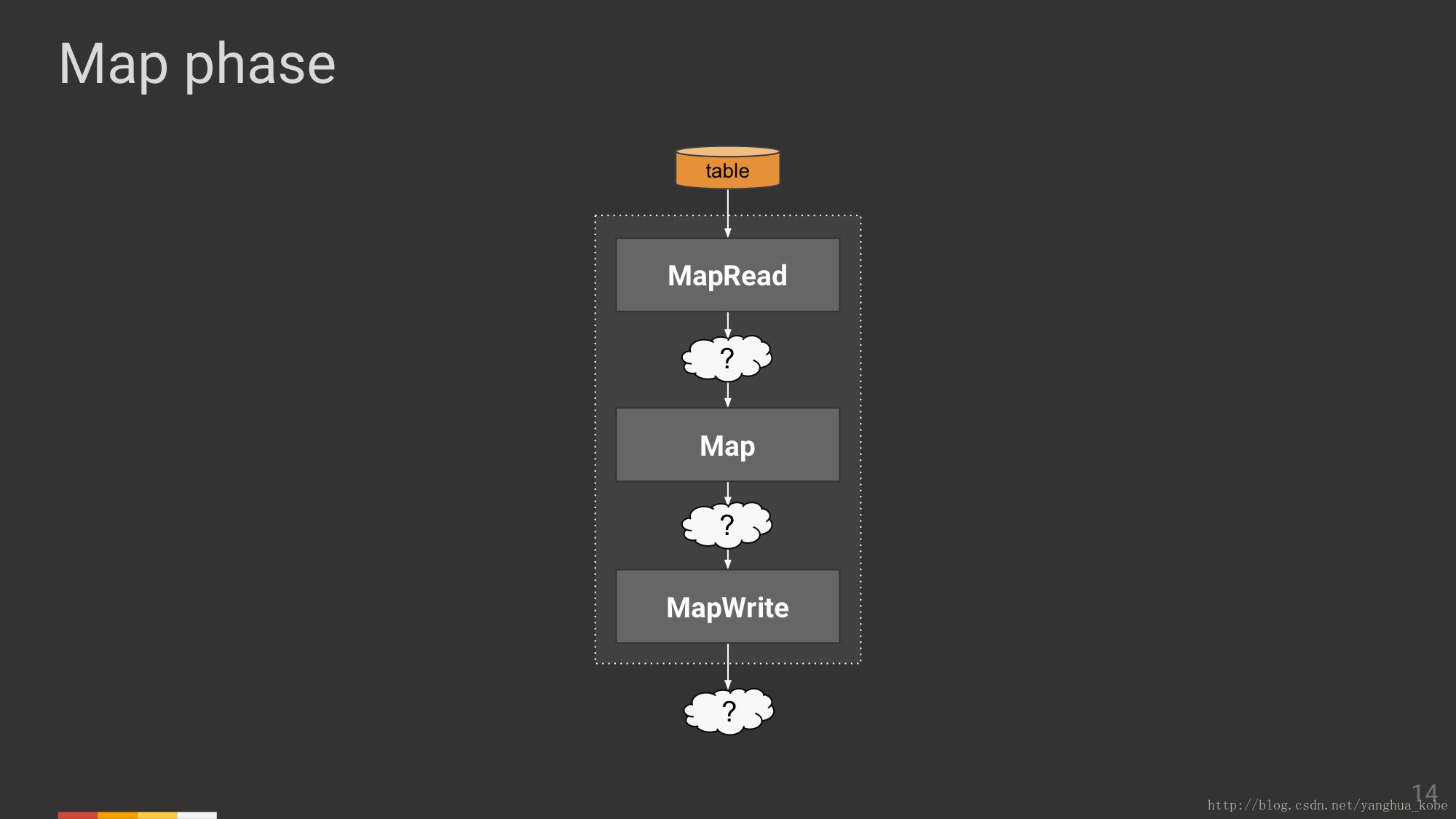
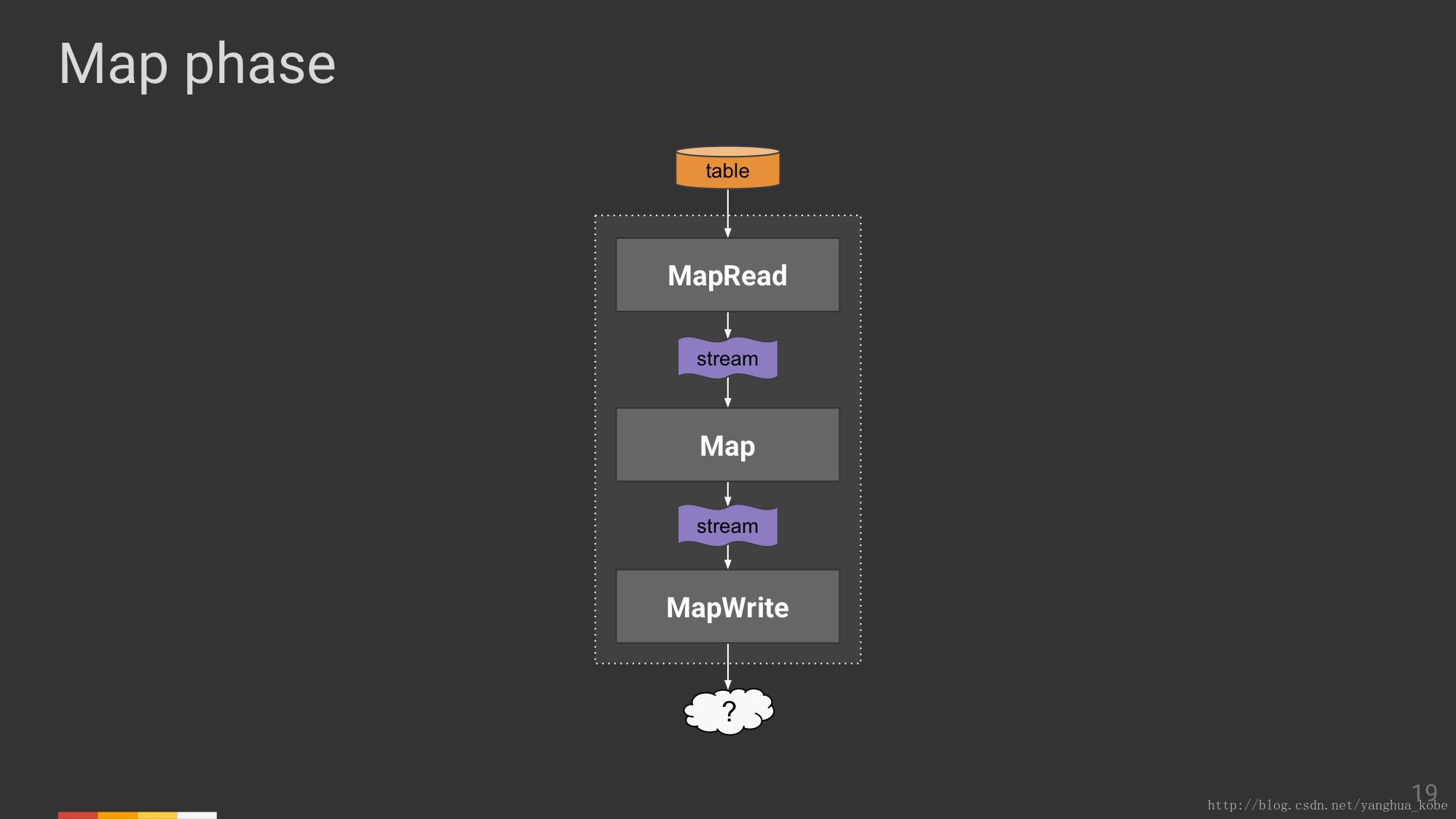
接下来,把Map/Reduce阶段拆开来看,先看Map阶段。
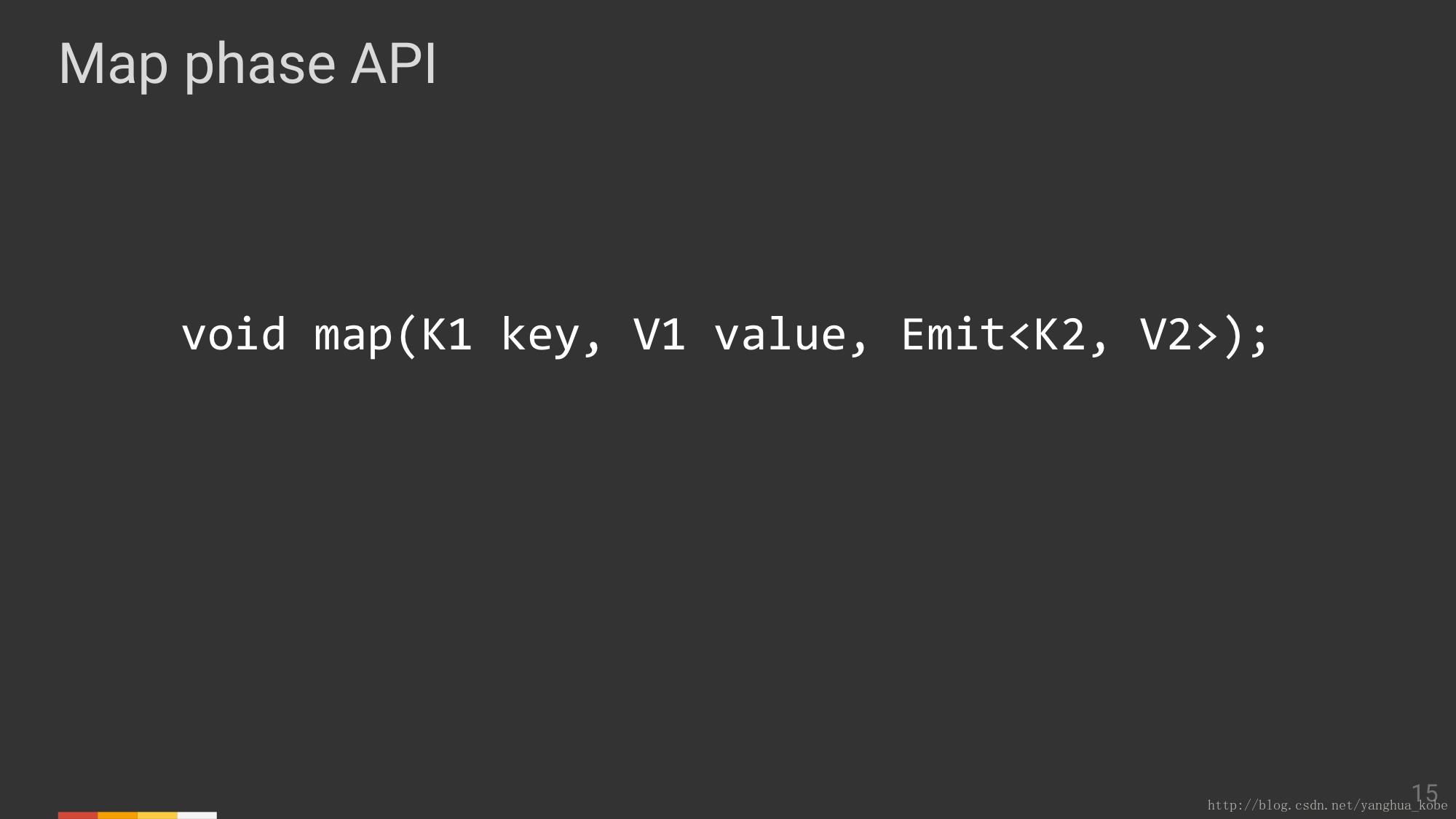
以下是一个map算子提供的接口,UDF需要实现它,它可以被拆分为两个部分。
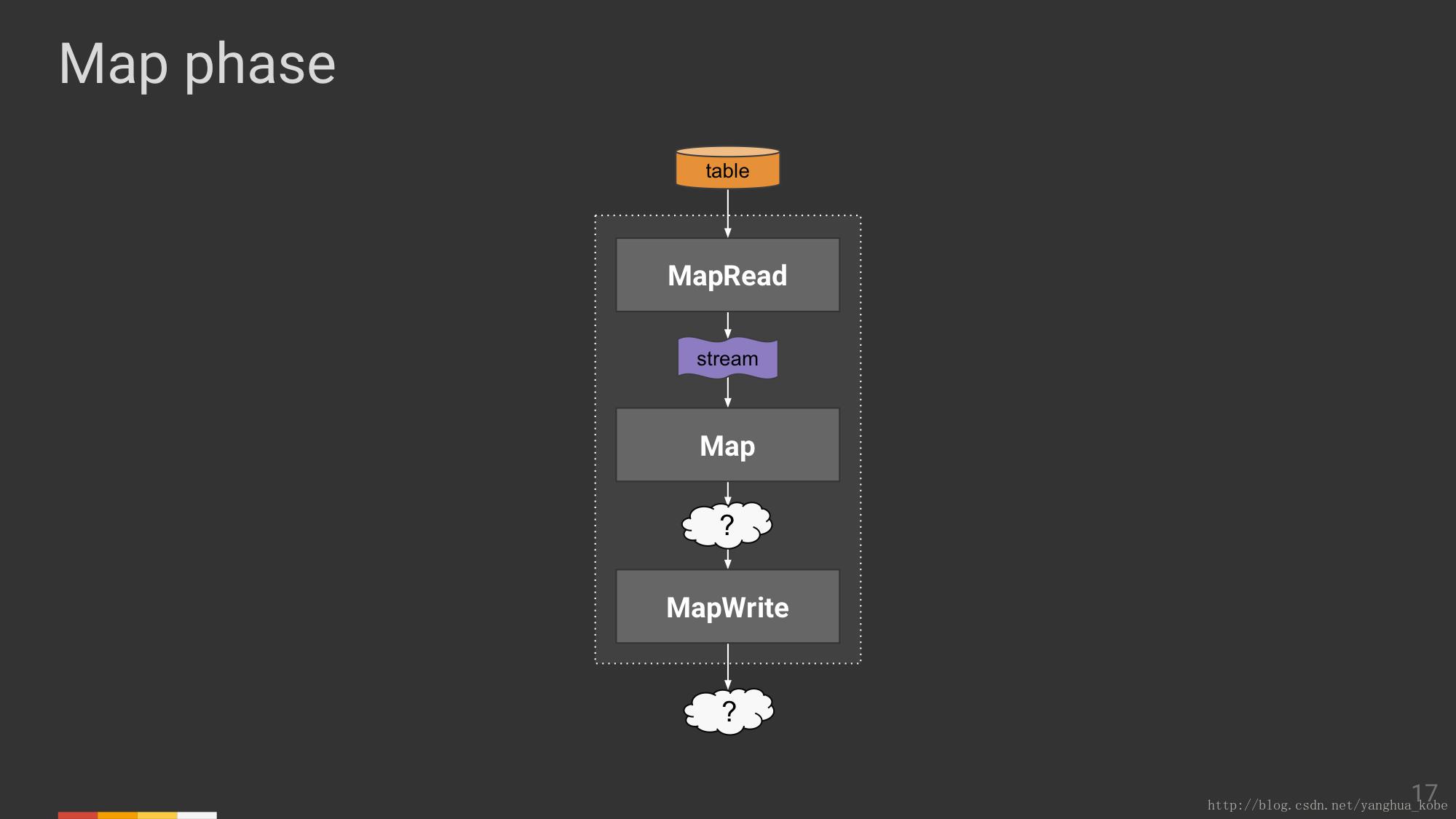
下图中高亮为黄色的两个参数,体现了MapRead输出数据的方式,它是一条条离散的记录,因此视为流(见下图)。

而经过了Map运算之后,将会输出一个新的键值对:K2,V2,它输出给MapWrite的方式仍然是独立的数据记录,因此仍然可视为流(见下图)

由于ReduceReduce的输入来自于MapWrite的输出,因此这里也存在着数据交换
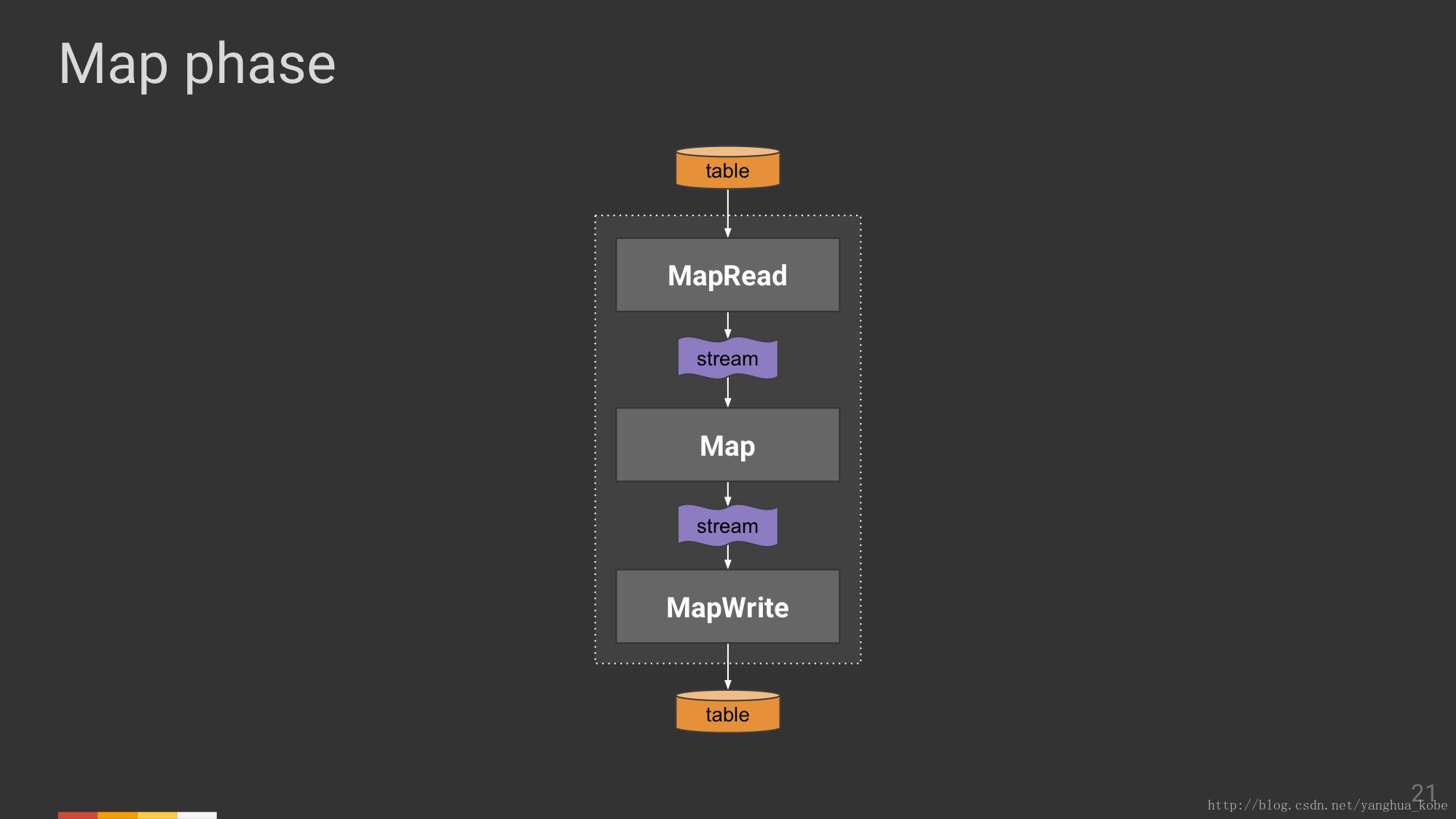
从两者的API可以看到,map的输出是流,而reduce的输入,其值对应的是一个集合,那么这里便存在着一个聚集(汇聚)的过程,因此Map阶段的整体输出可视为一个表(见下图)。

整个MapReduce计算模型中,Map阶段都已确定,下面来确定一下Reduce阶段。
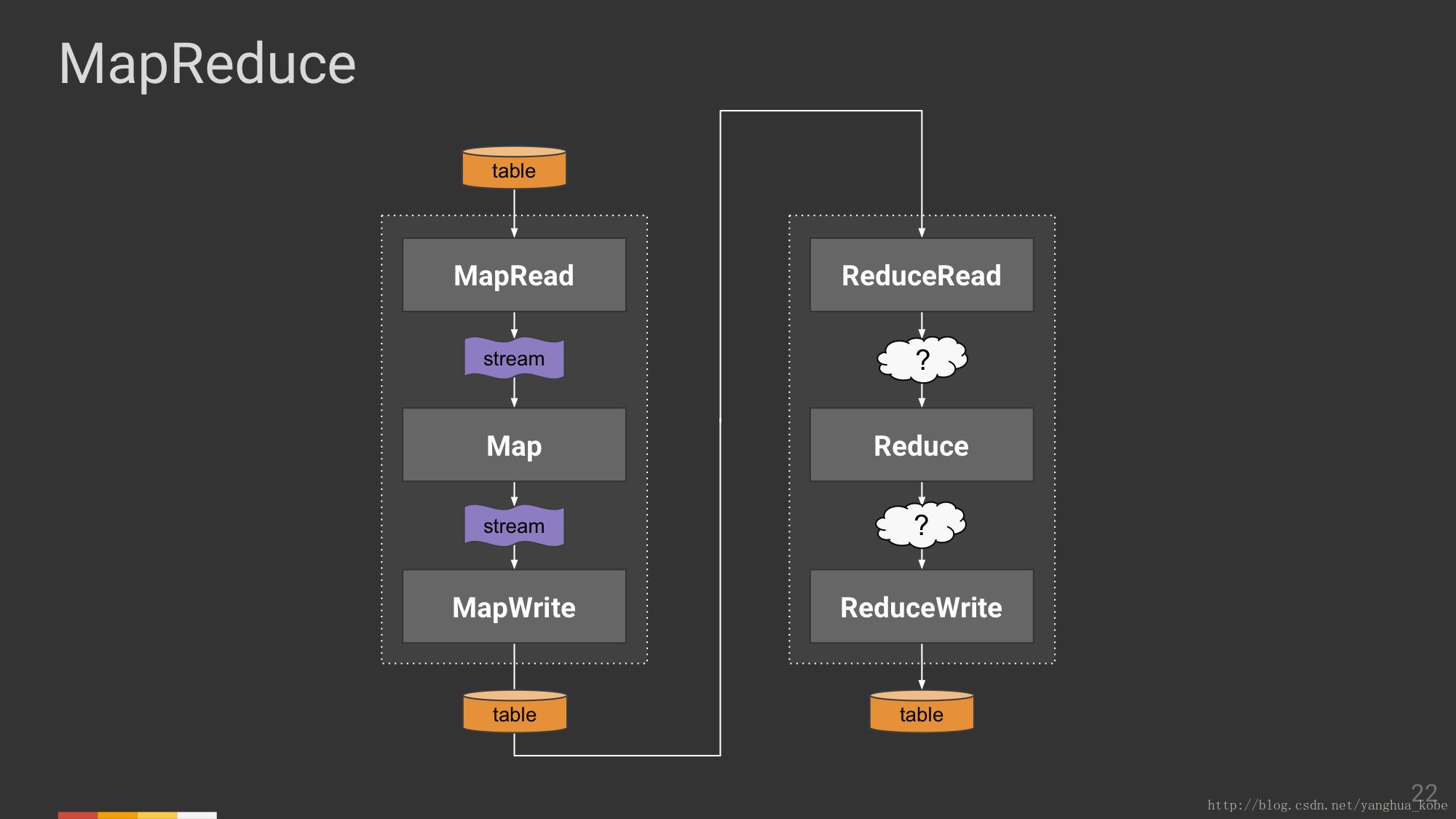
ReduceRead读取的是一个具体的键,及其对应的值集合,然后传递给Reduce算子进行运算,最终输出一个单值的结果,这中间伴随着数据的流动,可视为流。


到此,整个MapReduce计算各个部分的数据交换形式如下图:
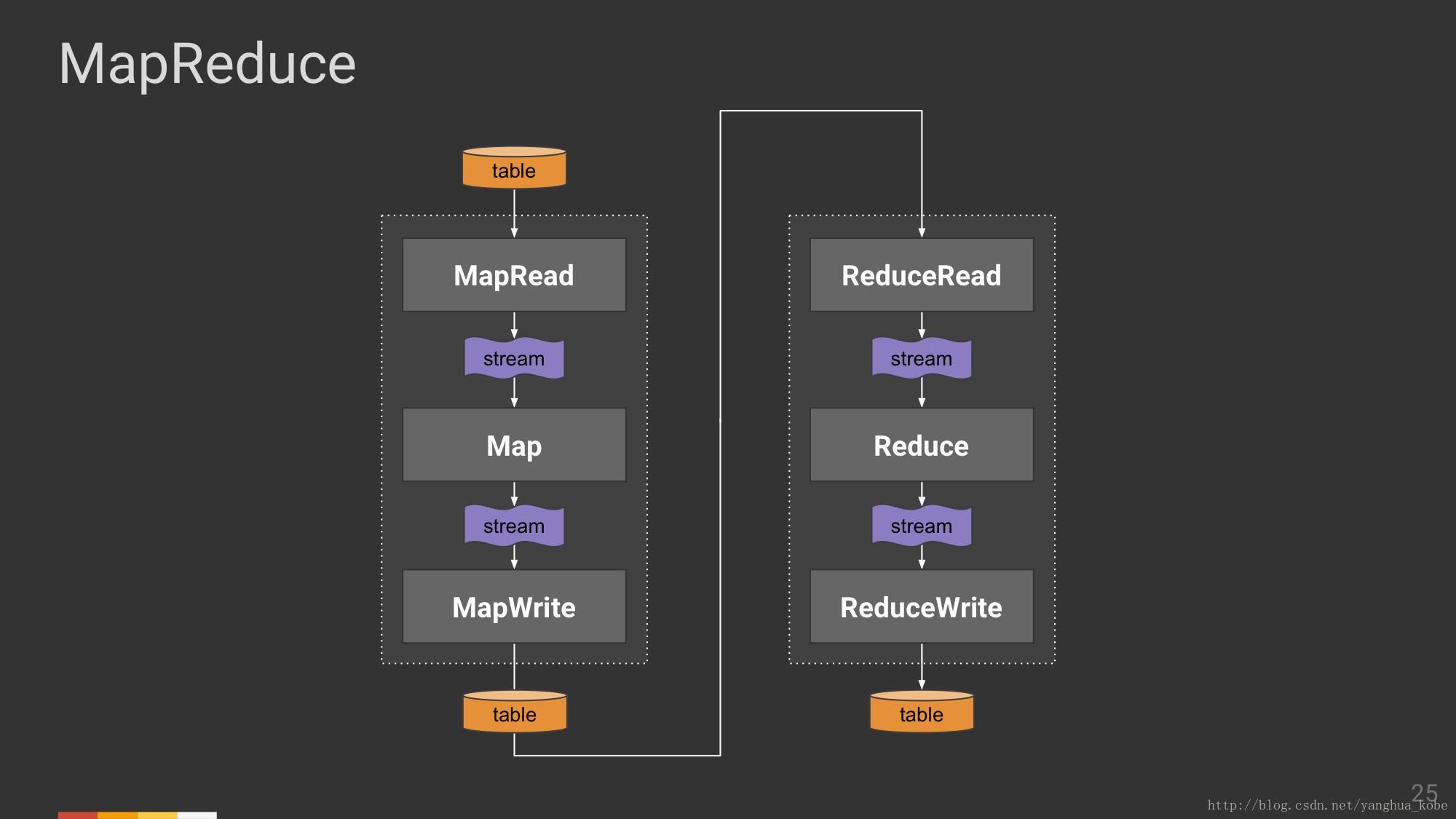
接下来,我们来回答在Beam模型中,流/表如何融合的问题,第一个问题是批处理如何适配这些概念:
表中的数据被读取,形成数据的流动,也就形成了数据流;
流被处理(各种算子)形成新的流,直到发生了一个分组运算(分组运算的属性就是聚集)
分组会将离散的数据汇聚起来,从而使其变成了静态数据,变成了表
接着就是1-3步的重复,直到计算完成

回答第二个问题:关于流跟有界数据集和无界数据集的关系:
流是数据的一种动态的形式,对有界和无界数据集都是如此。
这里注意跟以前的一些既有观念进行区分:之前的很多观念人为,流处理的是无界数据集,而批处理主要应用于有界数据集;

如何映射这四个问题?



想得到怎样的计算结果来选择算子,并填充算子的计算逻辑

这个图其实是个动画,建议去web页面上看一下,更能理解这一点。
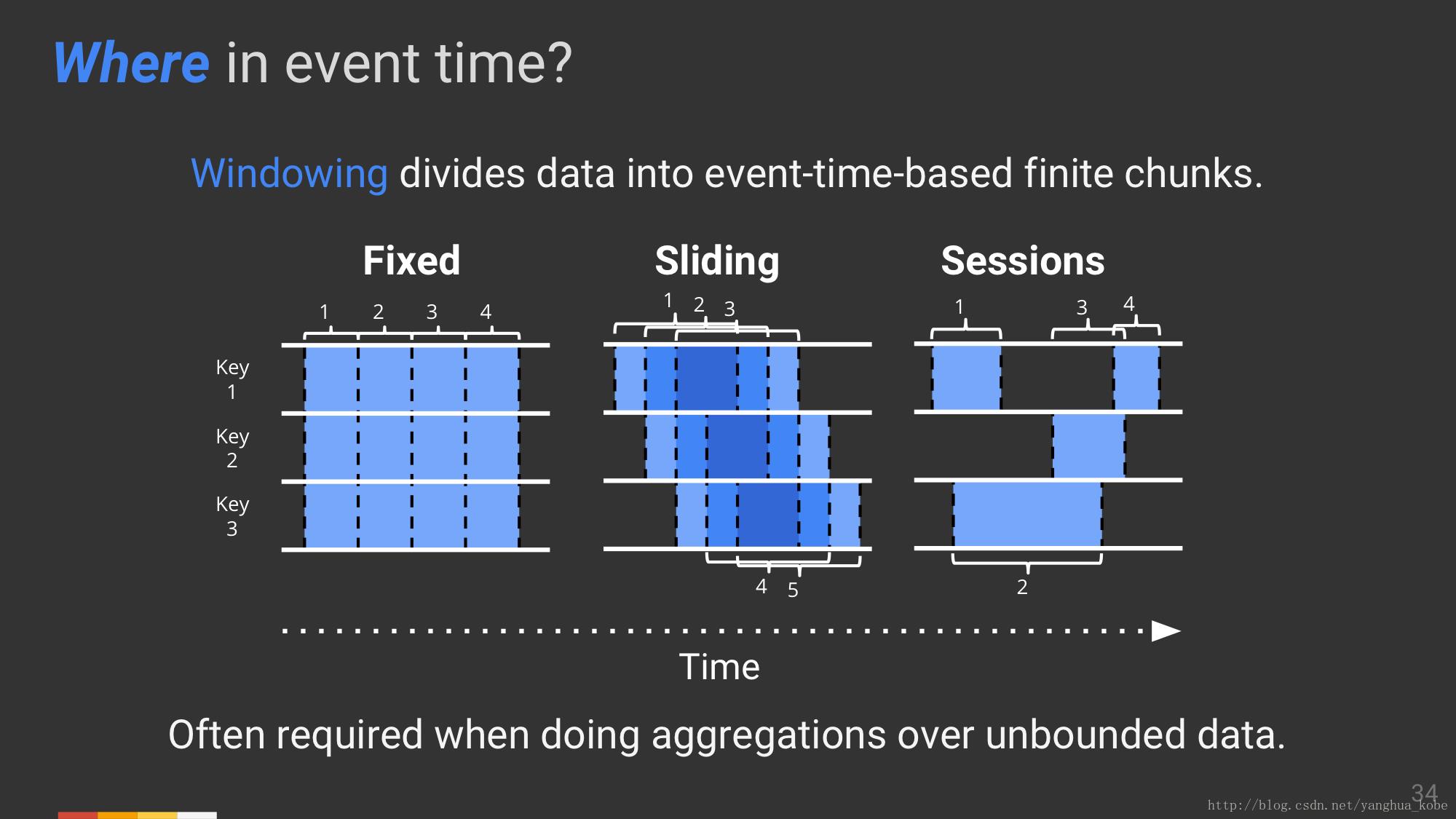
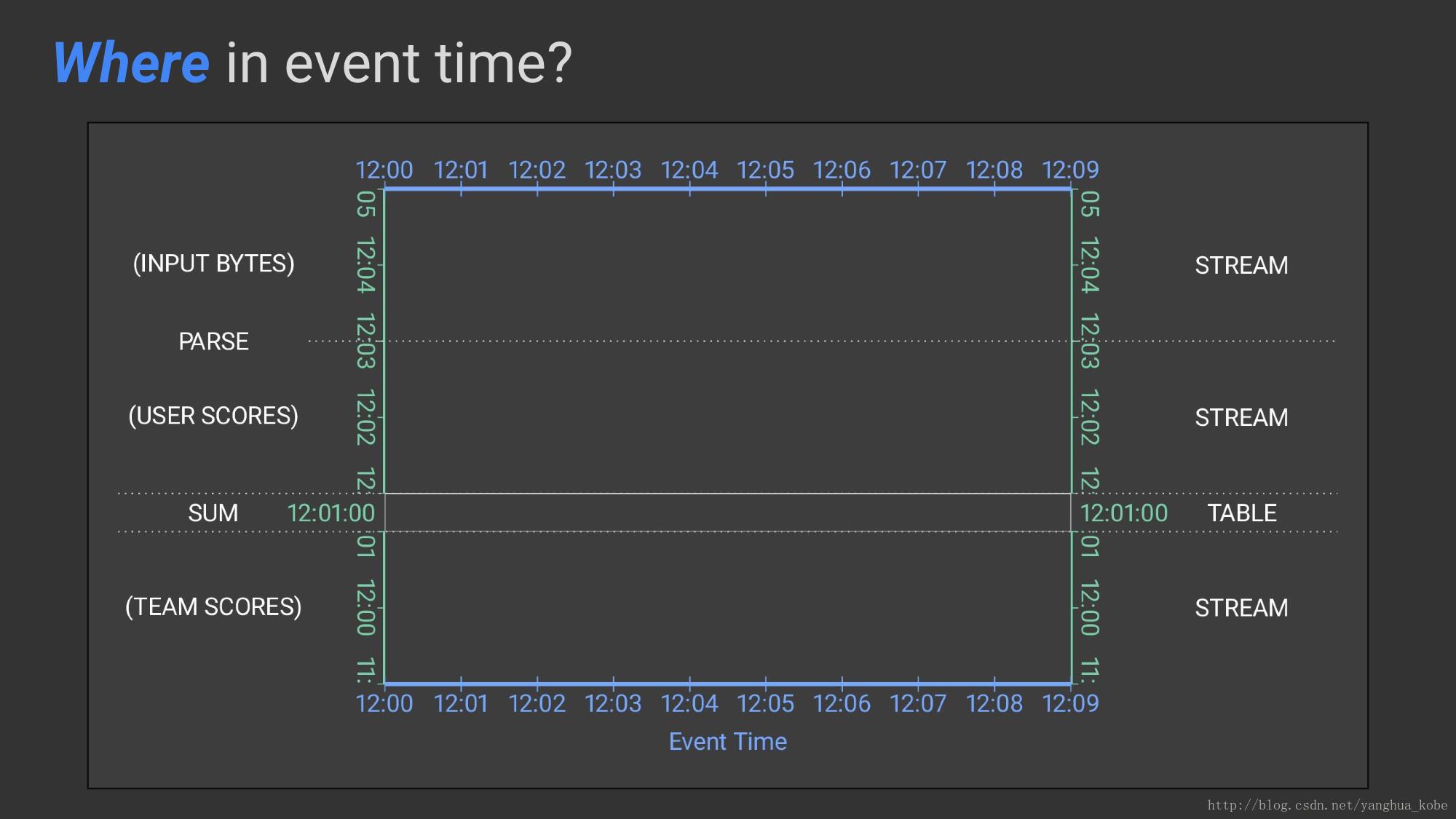
对于事件时间而言,在哪里进行计算以得到结果,这了如果是进行聚合计算,则通常需要引入窗口。
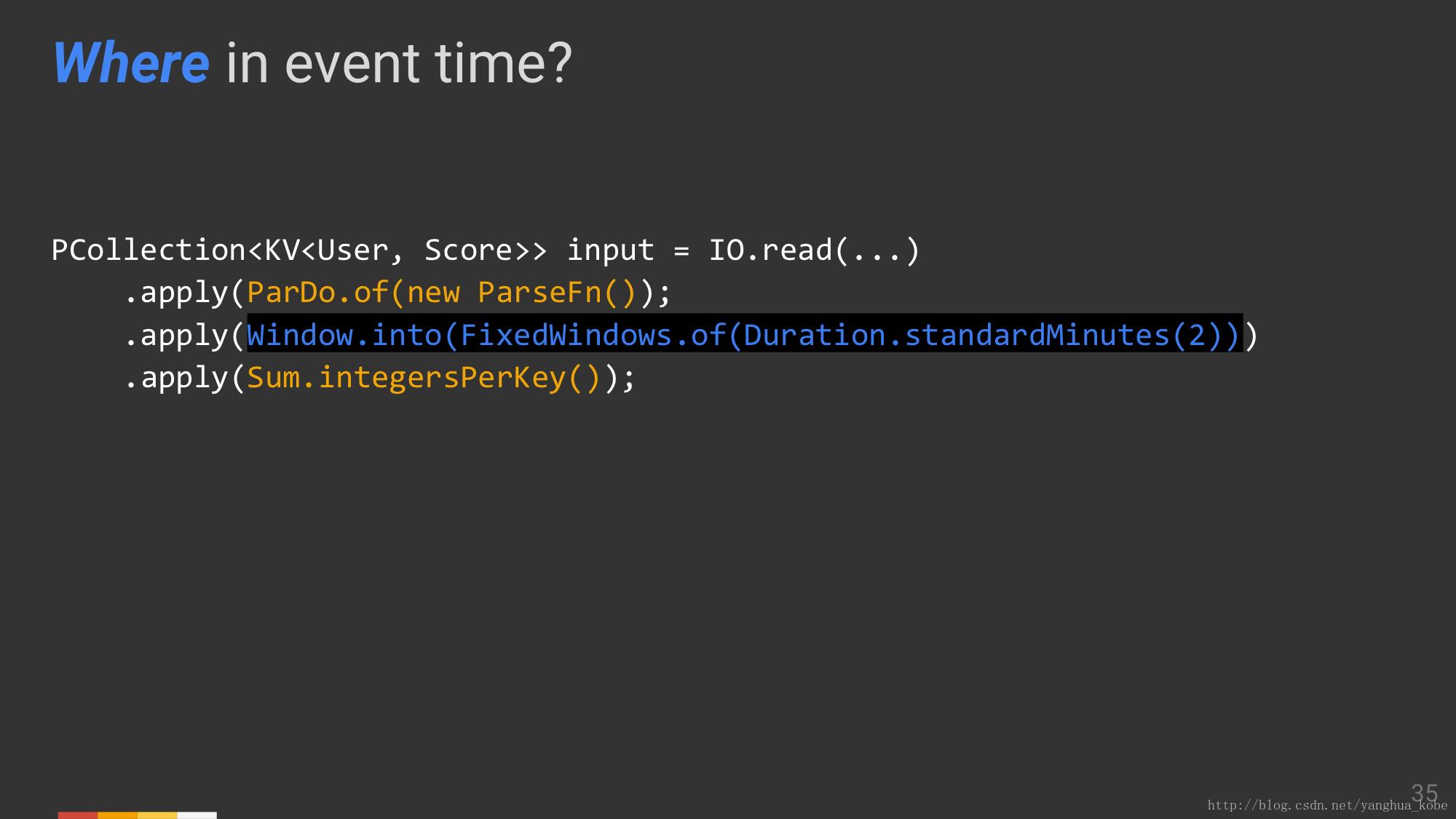
定义了一个2分钟的翻滚窗口,这就是where
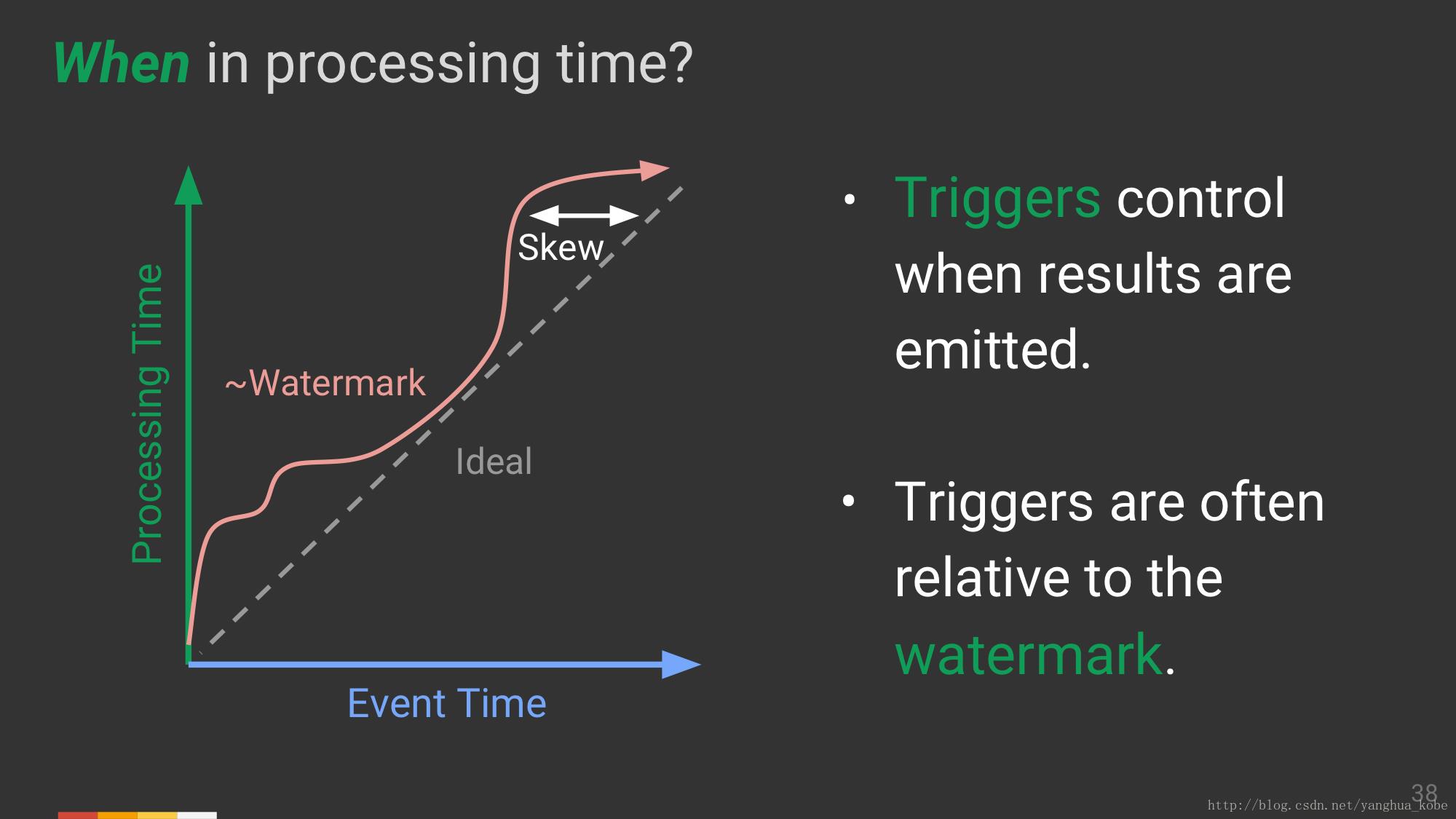
在处理时间中,什么时候进行(触发)计算,因为计算依赖于计算框架,所以其触发的时间参考是处理时间。什么时候,涉及到触发器控制结果的输出,对于事件时间还关联到Watermark
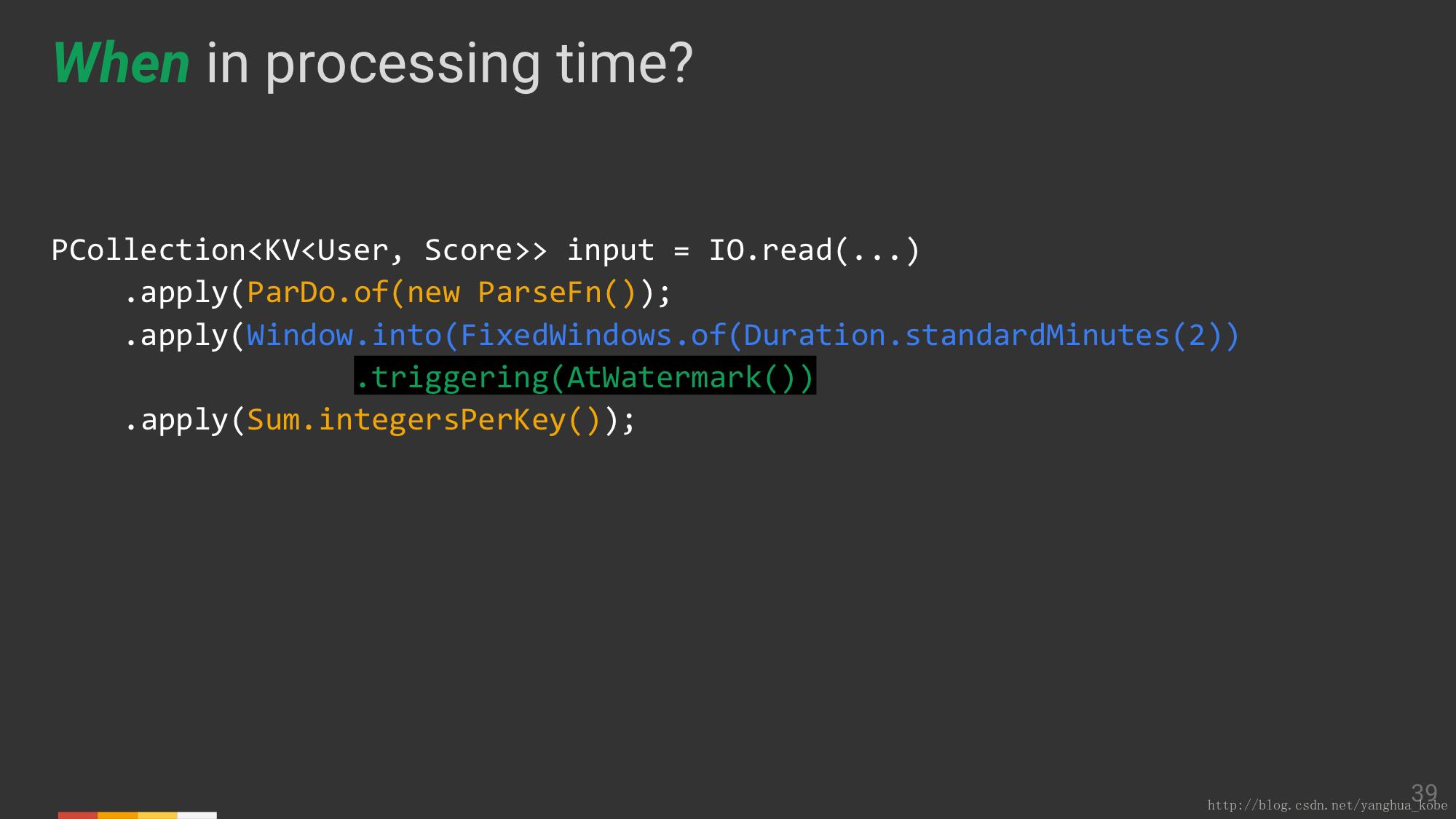
在框架中指定when语义
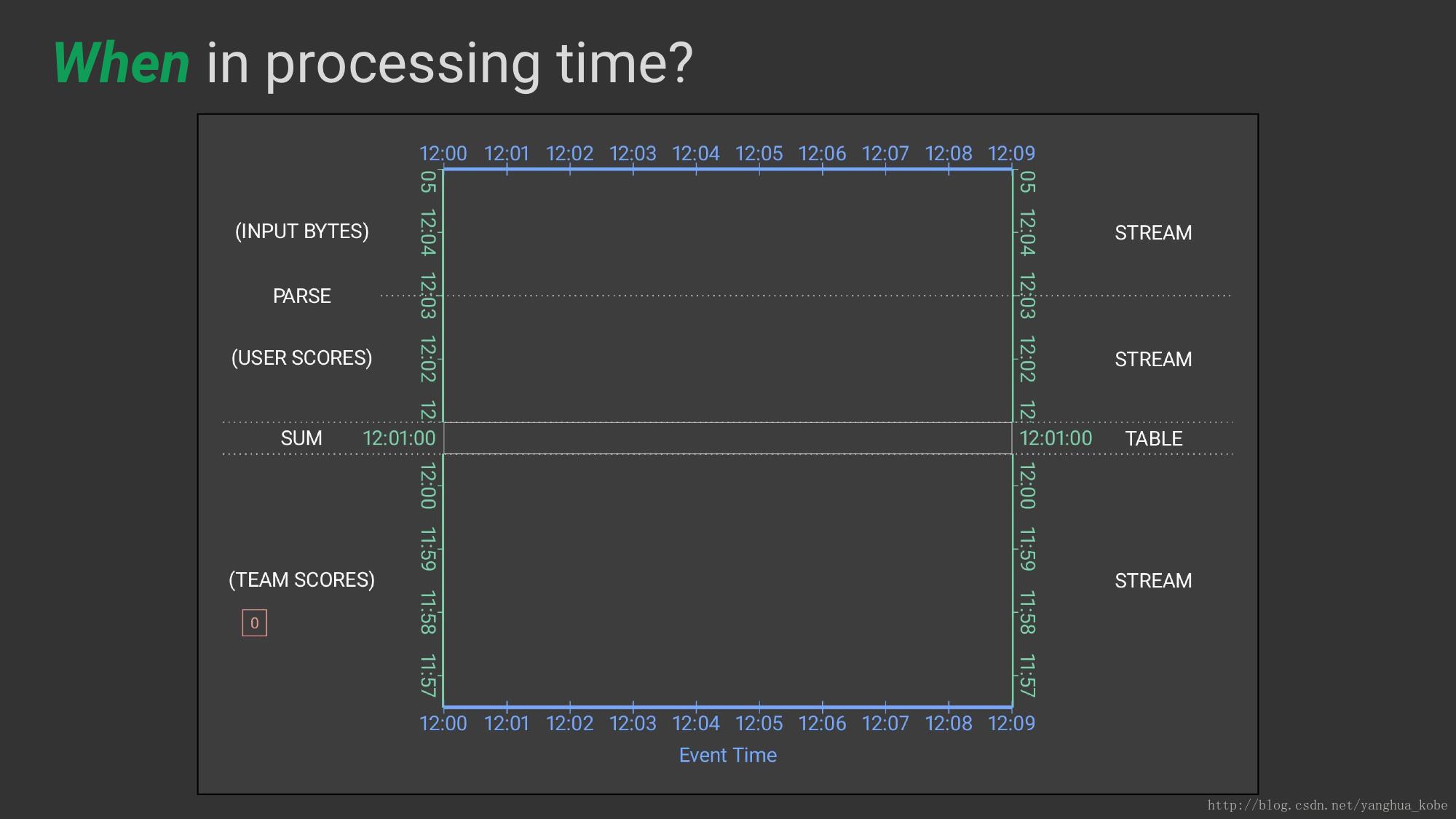

如何细化结果相关?注意这里为了演示,对when的API调用进行了调整,这里的how产生的结果就是提早聚集触发~

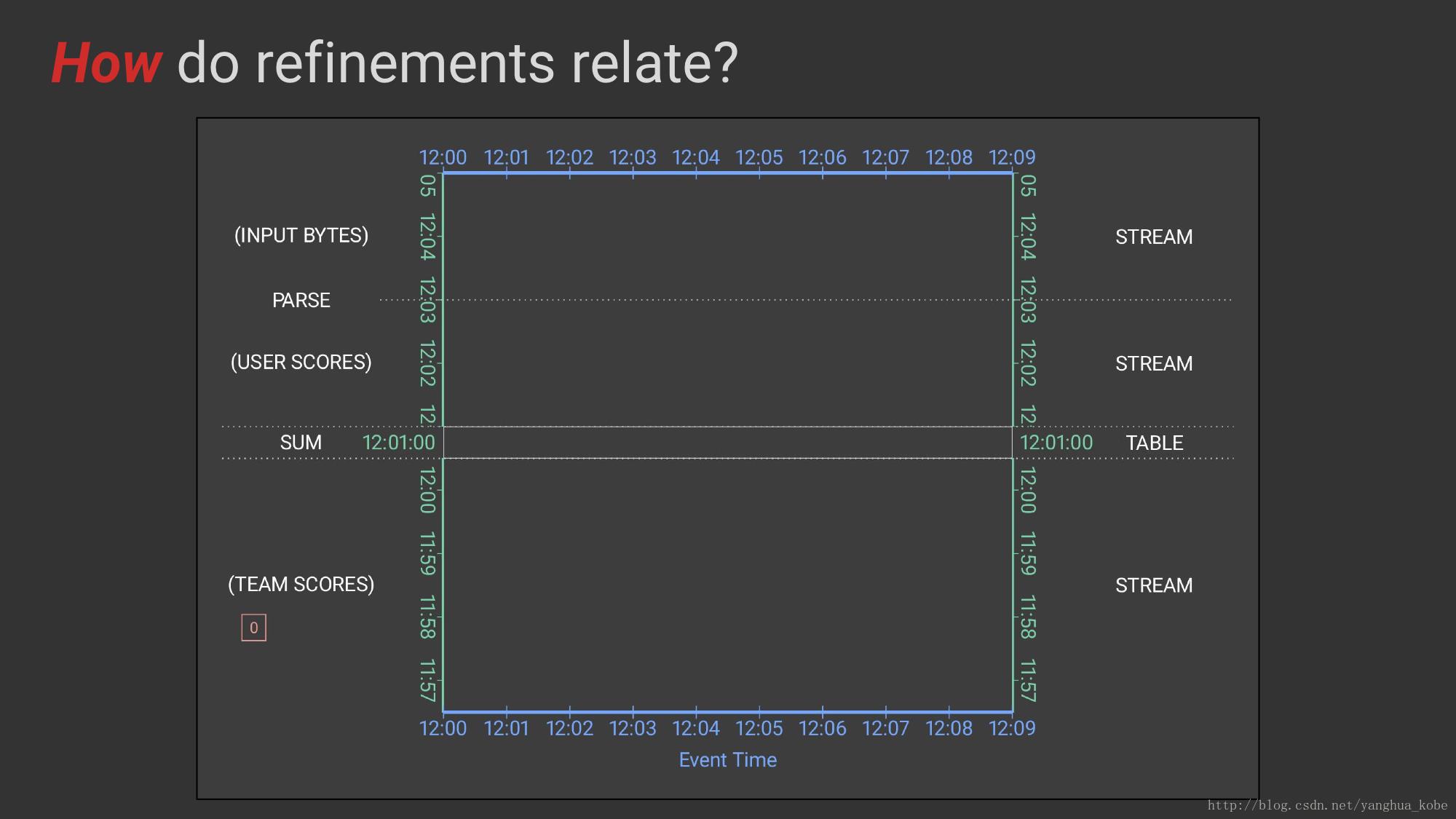
这四个问题,其实体现了计算模型的演讲过程。


关于流/表相关性的通用原理:
管道:表+流+运算
表:静态的数据
流:动态的数据
运算:(流|表)->(流|表)的转换
流->流:非分组的(元素级别)的运算;
流->表:分组运算,使得流动的数据变成静态的,从而产生一个表,窗口是一种时间维度上的分组;
表->流:去分组(触发计算)式的运算,将表数据转化为移动的数据,从而产生一个数据流;
表->表:不可能发生,因为从静态数据到静态数据的转变不可能没有数据的动态移动;

Streaming SQL

关系代数
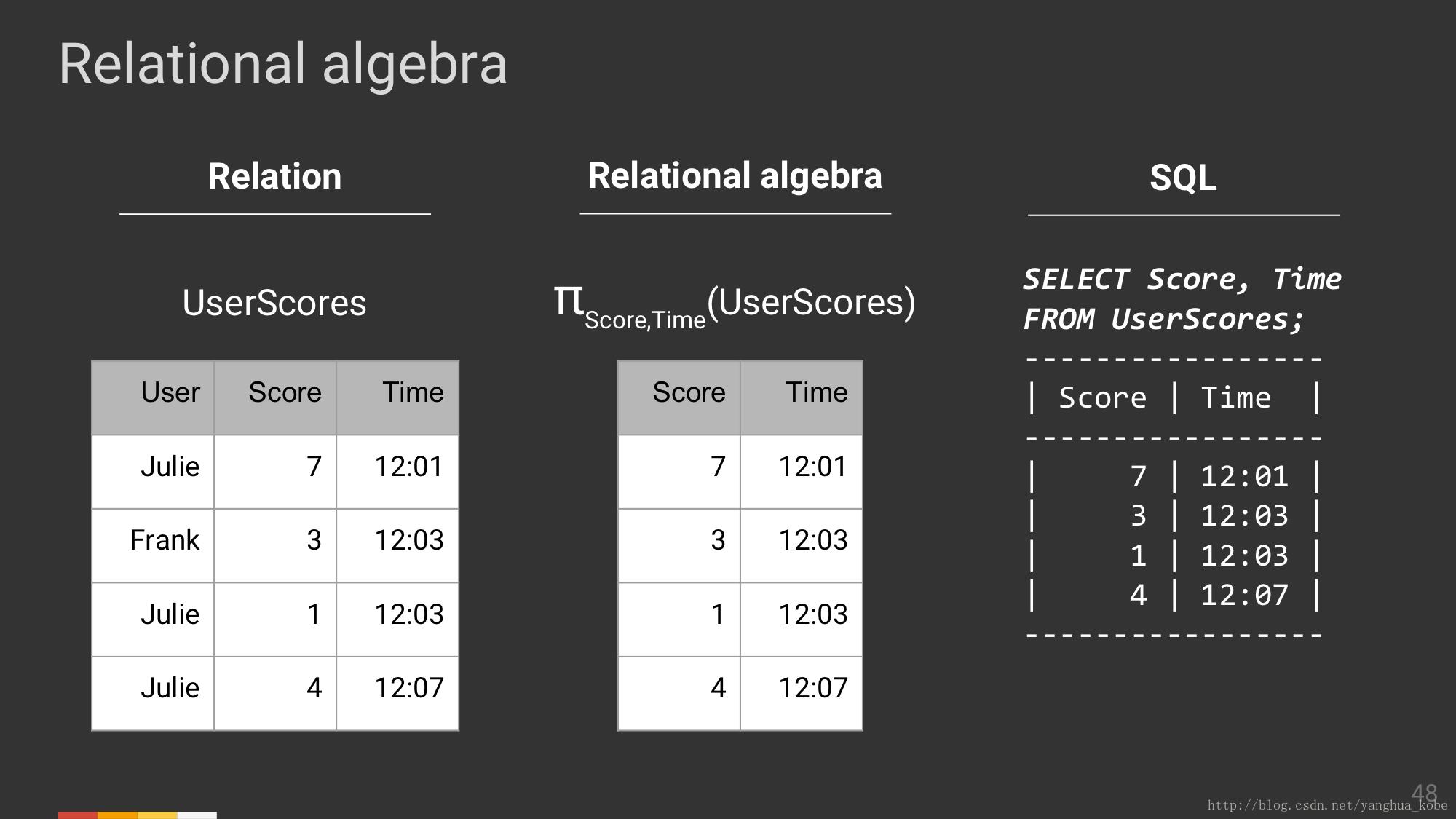
关系随着时间的演进

传统的SQL VS 流式SQL


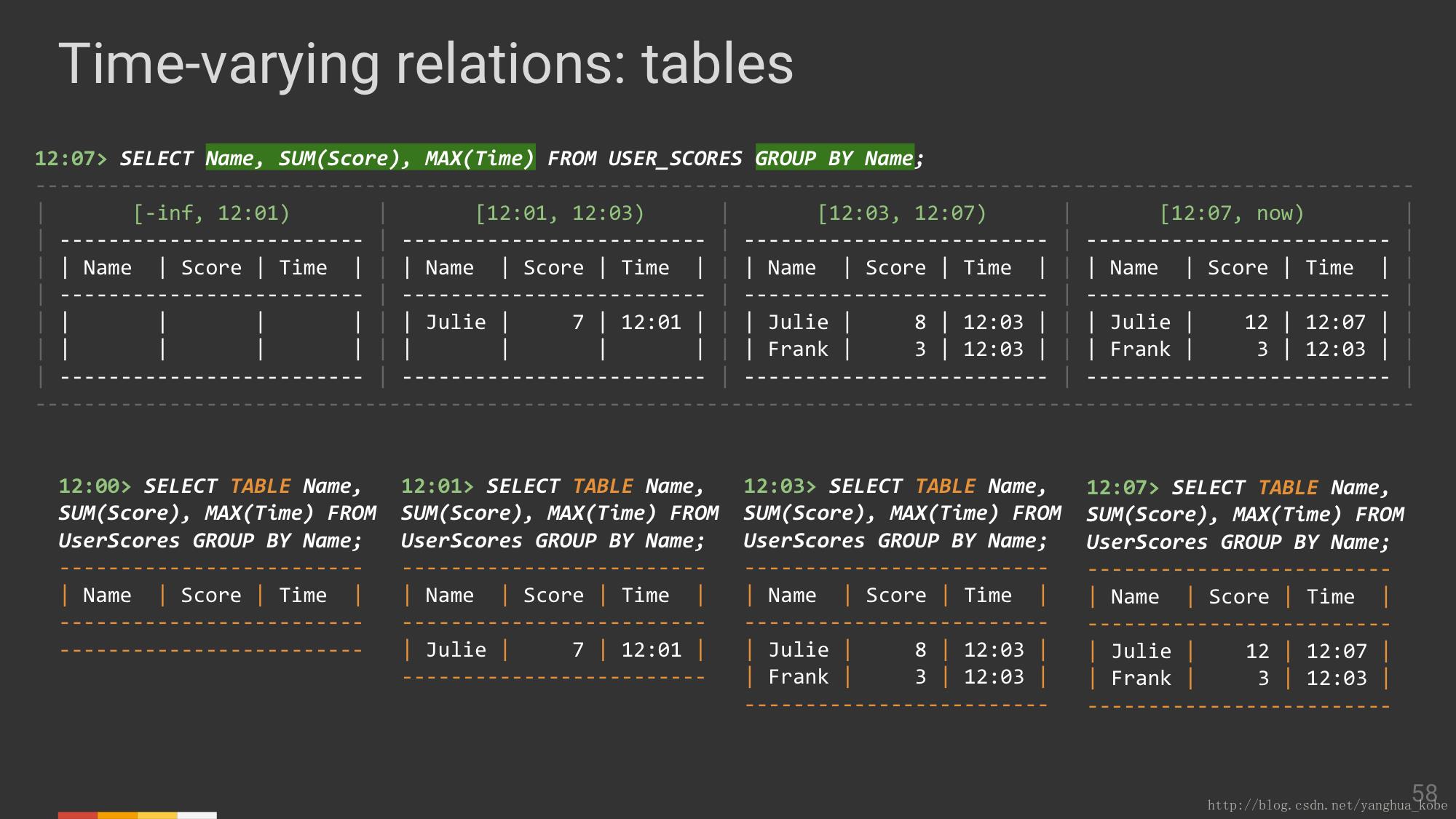
注意这里两者的区别,传统的观点是一个时间点的查询,而流式SQL中是一个时间区间的演进;

关系代数的封闭性保留了完整的基于时间演进的关系。


带添加name筛选条件,在之前的每个时间区间中,名为”Frank”的记录都被移除了。

分组聚合操作,在每个时间段中,结果集的变化

接下来将展示基于时间演进的SQL跟流与表的关系;

普通的查询并没有什么特别的
但是下图中,当指定了AS OF SYSTEM TIME‘’时,则可以查询之前时间段的内容,这体现了时间演进的过程(它得到的是一个点的结果,但是能查询之前某个时间点的结果,体现了时间演进时每个点结果得以保存的过程),而不是传统SQL中只保留当前时间点截止所演进的结果。

这依然是一个动画的展示,展示了12:00发起的一个流式SQL(SELECT后面跟了STREAM关键字),查询结果演进的过程;







表:捕获的是关系随着时间演进过程中某个时间点的快照(结果)
流:捕获的是关系随着时间演进过程中的进化(过程)


什么时候你需要SQL基于流式的扩展呢?
作为一个表:SQL的扩展几乎不需要,因为它代表着静态的数据;
作为一个流:SQL扩展有时需要

什么时候需要?
显式的表/流查询;
默认的表/流查询(任何输入时流,那么输出也是一个流,此时会需要)
时间戳和窗口(事件时间相关的列)
一些触发器的SQL形式的表达



以上是关于Foundations of streaming SQL的主要内容,如果未能解决你的问题,请参考以下文章