LinkedList
Posted 秋天de枫叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinkedList相关的知识,希望对你有一定的参考价值。
LinkedList是基于双向循环链表实现的,所以要对linkedList有全面的了解和认识,必须知道链表是如何实现的。
链表
什么是链表呢?
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。如图:
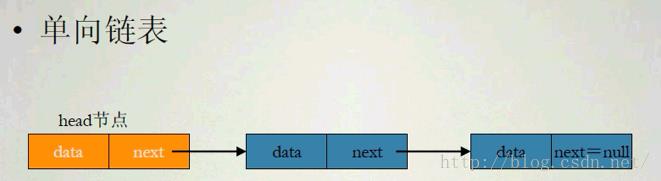
简单代码实现方式:
public class Node
String data;//存放节点数据本身
Node next;//存放下一个节点的引用
public Node(String data)
this.data=data;
public static void main(String[] args)
Node node1=new Node("node1");
Node node2=new Node("node2");
Node node3=new Node("node3");
node1.next=node2;
node2.next=node3;
System.out.println(node1.next.next.data);
输出结果是node3.
下面在介绍一下双向循环链表,图:
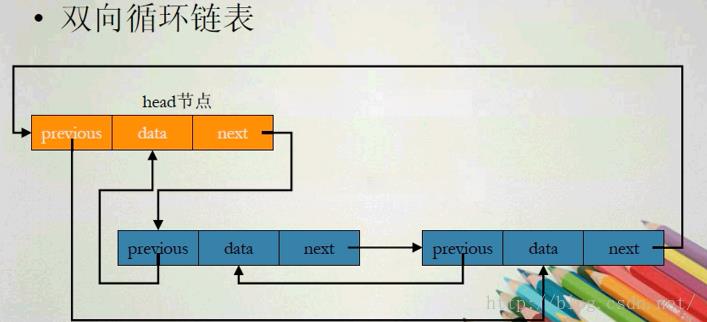
简单代码实现方式:
public class Node2
Node2 previous;
String data;
Node2 next;
public Node2(String data)
this.data=data;
public static void main(String[] args)
Node2 node1=new Node2("node1");
Node2 node2=new Node2("node2");
Node2 node3=new Node2("node3");
node1.next=node2;
node2.previous=node1;
node2.next=node3;
node3.previous=node2;
node3.next=node1;
node1.previous=node3;
System.out.println(node1.next.next.data);
System.out.println(node1.previous.previous.data);
通过对链表的学习,明白了链表的实现方式。所以对LinkedList的基本实现原理应该有大致了解了吧。
LinkeList集合结构
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable<span style="color:#00cccc;">
</span>LinkedList继承了AbstractSequentialList,并实现了List接口,即具有了添加,删除,修改,遍历等功能。
LinkedList是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList实现 Deque接口,即能将LinkedList当作双端队列使用。
LinkedList实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
私有属性
在LinkedList底层实现类中,定义了2个私有的属性,如下:
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;//size是双向链表中节点实例的个数。Header在定义时new了一个Entry对象,那Entry对象里有是什么呢?
我们通过下面的源码可以看出Entry对象中包含成员变量:previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
private static class Entry<E>
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous)
this.element = element;
this.next = next;
this.previous = previous;
public void addFirst(E paramE)
addBefore(paramE, this.header.next);//队首
public void addLast(E paramE)
addBefore(paramE, this.header);//队尾
构造方法

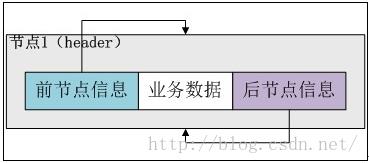
public LinkedList()
header.next = header.previous = header;
public LinkedList(Collection<? extends E> c)
this();
addAll(c);
执行完构造函数后,header实例自身形成一个闭环,如下图所示:
第二个构造方法接收一个Collection参数c,调用第一个构造方法构造一个空的链表,之后通过addAll将c中的元素全部添加到链表中。
代码如下:
public boolean addAll(Collection<? extends E> c)
return addAll(size, c);
// index参数指定collection中插入的第一个元素的位置
public boolean addAll(int index, Collection<? extends E> c)
// 插入位置超过了链表的长度或小于0,报IndexOutOfBoundsException异常
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Object[] a = c.toArray();
int numNew = a.length;
// 若需要插入的节点个数为0则返回false,表示没有插入元素
if (numNew==0)
return false;
modCount++;//否则,插入对象,链表修改次数加1
// 保存index处的节点。插入位置如果是size,则在头结点前面插入,否则在获取index处的节点插入
Entry<E> successor = (index==size ? header : entry(index));
// 获取前一个节点,插入时需要修改这个节点的next引用
Entry<E> predecessor = successor.previous;
// 按顺序将a数组中的第一个元素插入到index处,将之后的元素插在这个元素后面
for (int i=0; i<numNew; i++)
// 结合Entry的构造方法,这条语句是插入操作,相当于C语言中链表中插入节点并修改指针
Entry<E> e = new Entry<E>((E)a[i], successor, predecessor);
// 插入节点后将前一节点的next指向当前节点,相当于修改前一节点的next指针
predecessor.next = e;
// 相当于C语言中成功插入元素后将指针向后移动一个位置以实现循环的功能
predecessor = e;
// 插入元素前index处的元素链接到插入的Collection的最后一个节点
successor.previous = predecessor;
// 修改size
size += numNew;
return true;
加入第一个节点后 LinkedList示意图
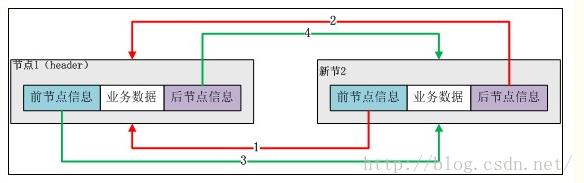
添加第二个元素后:
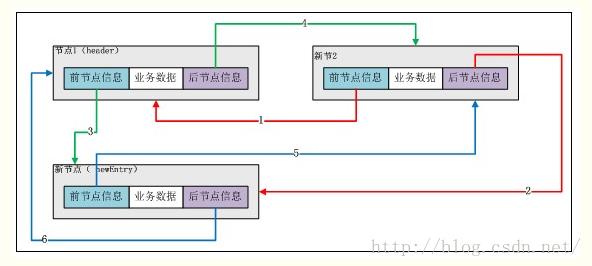
总结
LinkedList是通过节点直接彼此连接来实现的。每一个节点都包含前一个节点的引用,后一个节点的引用和节点存储的值。当一个新节点插入时,只需要修改其中保持先后关系的节点的引用即可,当删除记录时也一样。
所以说LinkedList适用于查询需求不大,但是增加和删除特别频繁的功能。
但是LinkedList不能随即访问虽然存在get()方法,但是这个方法是通过遍历接点来定位的所以速度慢。
以上是关于LinkedList的主要内容,如果未能解决你的问题,请参考以下文章