4-3《Java中所有集合》——链表和二叉树CollectionListSetMapIterator迭代器集合在JDK9中的新特性
Posted 美少女降临人世间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4-3《Java中所有集合》——链表和二叉树CollectionListSetMapIterator迭代器集合在JDK9中的新特性相关的知识,希望对你有一定的参考价值。
此文包含Java中所有集合知识点:使用方式和代码,还有各种注意事项
集合
一、类集概述
集合是数据的容器。 java 对数据结构成熟的实现。
Collection和Map是同一级的,一个是单值存储,一个是双值存储,接下来的内容中会重点学习。

链表和二叉树都属于数据结构。
前期Java程序员不需要过于关注数据结构,因为Java内置了一套成熟的数据结构
二、链表和二叉树
1、链表
链表节点
class Node
Object data;
Node next;
链表,linked list:按特定的顺序链接在一起的抽象数据类型。
-
数组的优点
- 存取速度快
-
数组的缺点:
- 事先必须知道数组的长度
- 插入删除元素很慢
- 空间通常是有限制的
- 需要大块连续的内存块
- 插入删除元素的效率很低
-
链表的优点
- 空间没有限制
- 插入删除元素很快
-
链表的缺点
- 存取速度很慢
-
可以通过练习编写链表的增删遍历代码对链表进行深入了解。
2、二叉树

链表只有下一个,二叉树有左下一个和右下一个。
二叉树节点
class Node
Object data;
Node left;
Node right;
通常二叉树都是有序的,根节点向下分叉,存储的数据与根节点作比较,比根节点小存到左下,反之存到右下。之后每存储一个数据就按照这个存储顺序依次向下分叉。
-
二叉树的遍历方式
-
先序遍历
先访问根节点,然后访问左节点,最后访问右节点,顺序:中左右
-
中序遍历
先访问左节点,然后访问根节点,最后访问右节点,顺序:左中右
-
后序遍历
先访问左节点,然后访问右节点,最后访问根节点,顺序:左右中
-
-
可以通过练习编写二叉树的遍历代码对二叉树进行深入了解。
三、常见数据结构
数据存储常用结构有:栈、队列、数组、链表和红黑树。
1、栈
stack,又称堆栈,是一种限定存储的结构。限定仅在整个结构的尾部进行添加、删除操作的线性表。
特点:
- 先进后出:例如将子弹压入弹夹之中,先压进去的子弹在下面,后压进去的子弹在上面,开枪时先弹出上面的子弹,后弹出下面的子弹。
- 栈的入口和出口都是栈的顶端位置
此处有两个名词:
-
压栈:存元素
-
弹栈:取元素
栈在Java类集中用得不多。
2、队列
queue,就像排队,先排的先走。队列是一种特殊的线性表,只允许在表的一端插入,另一端删除。
特点:
- 先进先出:例如火车过山洞,车头先进去、车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。有单端队列和双端队列。
3、数组
Array,有序的元素序列。
特点:
- 查找元素通过索引找,特别快。
- 增删元素慢:需要创建新的数组,根据下标进行增加和删除,进行数据的移动
4、链表
linked list,由一系列节点node组成,每一个节点除了要存储数据,还要存储下一个节点的位置,像一个链链接起来。分为单向、双向链表和单向、双向循环链表。
特点:
- 查找元素慢:依次查找
- 增删元素快:只需要修改连接下个元素的地址
5、红黑树
二叉树:binary tree,每个节点不超过2的有序树。红黑树又称平衡二叉树。
特点:
-
尽量保持平衡,不会将数据只存在一端
-
速度特别快,趋近于平衡,查找叶子元素最少和最多次数不多于二倍
四、Collection接口(重点)
单值存储从此处开始。
在整个 Java 类集中保存单值的最大操作父接口,里面每次操作的时候都只能保存一个对象的数据。此接口定义在 java.util 包中。单值存储。用得最多的是List和Set接口。
Collection接口的常用方法:
| No. | 方法名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | public booleanadd(Ee) | 普通 | 向集合中插入一个元素 |
| 2 | public boolean addAll(Collection<?extends E> c) | 普通 | 向集合中插入一组元素 |
| 3 | public void clear() | 普通 | 清空集合中的元素 |
| 4 | public boolean contains(Object o) | 普通 | 查找一个元素是否存在 |
| 5 | public boolean containsAll(Collection<?> c) | 普通 | 查找一组元素是否存在 |
| 6 | public boolean isEmpty() | 普通 | 判断集合是否为空 |
| 7 | public Iterator<E> iterator() | 普通 | 为 Iterator 接口实例化 |
| 8 | public boolean remove(Object o) | 普通 | 从集合中删除一个对象 |
| 9 | boolean removeAll(Collection<?> c) | 普通 | 从集合中删除一组对象 |
| 10 | boolean retainAll(Collection<?> c) | 普通 | 判断是否没有指定的集合 |
| 11 | public intsize() | 普通 | 求出集合中元素的个数 |
| 12 | public Object[] toArray() | 普通 | 以对象数组的形式返回集合中的全部内容 |
| 13 | <T>T[]toArray(T[] a) | 普通 | 指定操作的泛型类型,并把内容返回 |
| 14 | public boolean equals(Object o) | 普通 | 从 Object 类中覆写而来 |
| 15 | public int hashCode() | 普通 | 从 Object 类中覆写而来 |
-
为什么要学习集合?
因为集合是Java中成熟的数据结构的实现,使用集合可以更合理地存储数据。便于对数据更好地进行管理。
1、List接口(重点)
List中所有的内容都允许重复。
对接口Collection的扩充方法:
| No. | 方法名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | public void add(int index,E element) | 普通 | 在指定位置处增加元素 |
| 2 | boolean addAll(int index,Collection<?extends E>c) | 普通 | 在指定位置处增加一组元素 |
| 3 | public E get(int index) | 普通 | 根据索引位置取出每一个元素 |
| 4 | public int indexOf(Object o) | 普通 | 根据对象查找指定的位置,找不到返回-1 |
| 5 | public int lastIndexOf(Object o) | 普通 | 从后面向前查找位置,找不到返回-1 |
| 6 | public List Iterator<E> list Iterator() | 普通 | 返回 List Iterator |
| 7 | public List Iterator<E> listIterator(int index) | 普通 | 返回从指定位置的 ListIterator 接口的实例 |
| 8 | public E remove(int index) | 普通 | 删除指定位置的内容 |
| 9 | public E set(int index,E element) | 普通 | 修改指定位置的内容 |
| 10 | List<E> subList(int fromIndex,int toIndex) | 普通 | 返回子集合 |
-
List中有许多实现类:ArrayList、Vector和LinkedList(双向链表)。
Vector是ArrayList早期实现,ArrayList线程不安全,Vector线程安全。(线程后续学习)
1.ArrayList集合(重点)
ArrayList是List接口的子类:有序、可重复。使用数组结构,增删慢、查找快。
创建数组:
ArrayList<Integer> data = new ArrayList<>();
接下来查看ArrayList的源码,我们看到ArrayList创建的数组,初始值为一个常量。
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList()
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
再点进去这个常量,我们看到它是一个长度为0的数组。
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = ;
**添加数据:**用上面的data调用add方法
data.add(100);
- 存储时需要存储Integer类型数据,传入的int型会自动装箱为Integer类型数据。此时数组长度为0,若想存储数据,需要进行扩容,而add就对数据进行扩容操作。
点开add源码,结果return的是true。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return @code true (as specified by @link Collection#add)
*/
public boolean add(E e)
modCount++;
add(e, elementData, size);
return true;
- 只要调用add方法,永远返回true。
再点开add中传入3个参数的add方法:
/**
* This helper method split out from add(E) to keep method
* bytecode size under 35 (the -XX:MaxInlineSize default value),
* which helps when add(E) is called in a C1-compiled loop.
*/
private void add(E e, Object[] elementData, int s)
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
- 如果目前寸的数据和数组长度一致,说明存满了,此时用grow方法对其进行扩容,重新赋值给elementData。
最后点开grow方法,看到底是如何对数组进行扩容的。
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private Object[] grow(int minCapacity)
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
private Object[] grow()
return grow(size + 1);
- 如果数组满了,最少给数组长度+1。定义一个新的数组长度,再使用Arrays.copyOf将旧数组的值,通过新的数组长度,赋值给旧数组。
查看newCapacity方法,用来计算新的长度:
/**
* Returns a capacity at least as large as the given minimum capacity.
* Returns the current capacity increased by 50% if that suffices.
* Will not return a capacity greater than MAX_ARRAY_SIZE unless
* the given minimum capacity is greater than MAX_ARRAY_SIZE.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private int newCapacity(int minCapacity)
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0)
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
private static int hugeCapacity(int minCapacity)
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE)
? Integer.MAX_VALUE
: MAX_ARRAY_SIZE;
-
新数组长度为: oldCapacity + oldCapacity >> 1
>> 1指二进制右移一位,相当于除2,0.5倍。
-
这里的默认长度DEFAULT_CAPACITY为10:
/** * Default initial capacity. */ private static final int DEFAULT_CAPACITY = 10;
获取集合中的数据:使用get
data.get(0);
打印集合:调用的是toString方法
System.out.println(data);
熟悉ArrayList的每个方法,并整理笔记。
2.Vector集合(重点)
不是vector冲锋枪,是可增长的对象数组。也是List接口的子类,从Java 1.2开始改进,可以实现List接口。
与ArrayList很像,存取数据方式一样,都通过size获取总长度。
使用:
Vector<Integer> vector = new Vector();
vector.add(1);
vector.add(2);
vector.add(3);
System.out.println(vector);
- 运行结果:

3.ArrayList类与Vector类的区别(重点)
Vector是线程安全的,ArrayList是线程不安全的。
| No. | 区别点 | ArrayList | Vector |
|---|---|---|---|
| 1 | 时间 | 是新的类,是在 JDK1.2 之后推出的 | 是旧的类是在 JDK1.0 的时候就定义的 |
| 2 | 性能 | 性能较高,是采用了异步处理 | 性能较低,是采用了同步处理 |
| 3 | 输出 | 支持 Iterator、ListIterator 输出 | 除了支持 Iterator、ListIterator 输出,还支持 Enumeration 输出 |
4.LinkedList集合(理解)
使用的是双向链表结构,增删快,查找慢。使用几率很低。
除了add、remove、get等,LinkedList还有特殊方法,可以当作栈、队列结构进行使用。
- addFirst(E e) 在此列表的开头插入指定的元素
- getFirst() 返回此列表中的第一个元素
- removeFirst() 从此列表删除并返回第一个元素
使用:
LinkedList<Integer> linkedList = new LinkedList<>();
linkedList.addFirst(222);
linkedList.addFirst(111);
linkedList.addFirst(333);
linkedList.addFirst(666);
Integer i = linkedList.removeFirst();
System.out.println(i);
System.out.println(linkedList);
-
可以用addFirst进行压栈,实际更像队列
-
运行结果:

真正的压栈、弹栈方法:
//压栈
linkedList.push(2);
linkedList.push(8);
System.out.println(linkedList);
//弹栈
Integer p = linkedList.pop();
System.out.println(p);
- 运行结果:

看需求选择使用双端、单端、栈、队列等方式,但在实际应用中较少使用到。
2、Set接口(重点)
继承自Collection接口,本身方法与Collection接口中方法基本一致,仅增加一点使用不太多的方法。是单值存储结构的顶级父接口。
- Set特性:无序,不可重复
Set在存储数据时不包含重复元素,null也只能放一个,模拟了数学中的集。
可变对象用作set元素可能会导致一些问题。
Set接口的两个常用子类:HashSet、TreeSet
1.HashSet集合(重点)
无get方法,想要获取数据要用toArray将其转为数组再遍历,还有就是用迭代器对其进行迭代。内部使用了哈希表(学习Map集合时了解)的存储方式,HashSet 属于散列的存放类集,里面的内容是无序存放的。
查看HashSet源码:
private transient HashMap<E,Object> map;

- 看到其中96行有一个HashMap
创建一个HashSet对象:调用add方法
HashSet<String> set = new HashSet<>();
set.add("12315");
-
点进add方法查看源码:
/** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element @code e to this set if * this set contains no element @code e2 such that * @code Objects.equals(e, e2). * If this set already contains the element, the call leaves the set * unchanged and returns @code false. * * @param e element to be added to this set * @return @code true if this set did not already contain the specified * element */ public boolean add(E e) return map.put(e, PRESENT)==null;- 看到是使用map对数据进行添加,重新利用了双值存储的数据结构
-
HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方 式,才能保证HashSet集合中的对象唯一
2.TreeSet集合(重点)
采用有序的二叉树进行存储。
TreeSet<String> data = new TreeSet();
//基于ASCII码
//A : 65
data.add("A");
data.add("bb");
data.add("C");
data.add("dd");
for (String i : data)
System.out.println(i);
- 运行结果:按照ASCII码进行排序

3.TreeSet与Comparable(重点)
测试TreeSet是否可以对类中的对象进行排序:假设已经创建了Person类,其中有in age和String name两个属性
TreeSet<Person> set = new TreeSet<>();
Person p1 = new Person(18, "小木");
Person p2 = new Person(15, "小帆");
set.add(p1);
set.add(p2);
for (Person p:set)
System.out.println(p);
-
创建两个Person对象,使用forEach对其遍历输出:

- 运行时出错,原因:“class wct.day12.Person cannot be cast to class java.lang.Comparable”,没有实现Comparable方法
什么是Comparable?
就是可以对对象比较大小的一种方法。
想要改正上述错误,需要对Person类实现Comparable接口:要加一个比较的泛型 ,并实现抽象方法CompareTo
public class Person implements Comparable<Person>
private int age;
private String name;
@Override
public int compareTo(Person o)
//返回的数据:可以是负数(this小)、0(相等)、正数(this大)
if(this.age > o.age)
return 1;
else if (this.age == o.age)
return 0;
return -1;
//get、set方法
- 此时再对Person类对象进行遍历输出,运行结果:
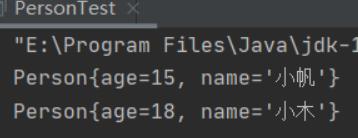
注意:如果发现两个内容一样大,就不会进行存储
所有单值存储结束。
其他
Comparator比较器:指定规则的排列
public int compare(String o1, String o2) :比较其两个参数的顺序。
两个对象比较的结果有三种:大于,等于,小于。
如果要按照升序排序
则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
如果要按照降序排序
则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
public class CollectionsDemo3
public static void main(String[] args)
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法 按照第一个单词的降序
Collections.sort(list, new Comparator<String>()
@Override
public int compare(String o1, String o2)
return o2.charAt(0) - o1.charAt(0);
);
System.out.println(list);
-
运行结果:
[sba, nba, cba, aba]
简述Comparable和Comparator两个接口的区别
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo方法被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码 实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进 行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparator强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构 (如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
五、集合输出(重点)
1、Iterator迭代器(重点)
现在需要遍历一个集合,使用for循环,如果遍历一个ArrayList,效率可观;但如果是一个LinkedList集合,那效率就不是最优的,此时可以使用迭代器来循环。
迭代器(2种)
-
Iterator:迭代Collection下的所有集合(如List、Set)
-
ListIterator:只能迭代List集合
Iterator(绝对重点)
通过集合对象调用iterator方法:拿到Iterator对象
Iterator<Integer> iterator = data.iterator();
iterator有许多方法:

| 变量和类型 | 方法 | 描述 |
|---|---|---|
default void | forEachRemaining(Consumer<? super E> action) | 对每个剩余元素执行给定操作,直到处理完所有元素或操作引发异常。 |
boolean | hasNext() | 如果迭代具有更多元素,则返回 true 。 |
E | next() | 返回迭代中的下一个元素。 |
default void | remove() | 从底层集合中移除此迭代器返回的最后一个元素(可选操作)。 |
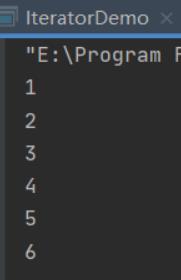
//使用迭代器对集合中的数据进行遍历
Iterator<Integer> iterator = data.iterator();
while (iterator.hasNext())
Integer i = iterator.next();
System.out.println(i);
- 运行结果
特殊的remove:必须用next获取数据,才能remove,否则会报错
iterator.next();
iterator.remove();
ListIterator(理解)
是Iterator的一个子接口。
| 变量和类型 | 方法 | 描述 |
|---|---|---|
void | add(E e) | 将指定的元素插入列表(可选操作)。 |
boolean | hasNext() | 如果此列表迭代器在向前遍历列表时具有更多元素,则返回 true 。 |
boolean | hasPrevious() | 如果此列表迭代器在反向遍历列表时具有更多元素,则返回 true 。 |
E | next() | 返回列表中的下一个元素并前进光标位置。 |
int | nextIndex() | 返回后续调用 next()将返回的元素的索引。 |
E | previous() | 返回列表中的上一个元素并向后移动光标位置。 |
int | previousIndex() | 返回后续调用 previous()将返回的元素的索引。 |
void | remove() | 从列表中删除 next()或 previous() (可选操作)返回的最后一个元素。 |
void | set(E e) | 用指定的元素替换 next()或 previous()返回的最后一个元素(可选操作)。 |
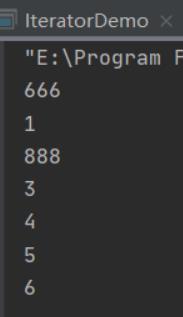
要想使用迭代器遍历数据必须将指针归0:
ListIterator<Integer> listIterator = data.listIterator();
listIterator.add(666);
listIterator.next();
listIterator.next();
listIterator.set(888);
listIterator.previous();
listIterator.previous();
listIterator.previous();
while (listIterator.hasNext())
System.out.println(listIterator.next());
- 运行结果:
2、forEachÿ
以上是关于4-3《Java中所有集合》——链表和二叉树CollectionListSetMapIterator迭代器集合在JDK9中的新特性的主要内容,如果未能解决你的问题,请参考以下文章