大顶堆,小顶堆
Posted 这瓜保熟么
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大顶堆,小顶堆相关的知识,希望对你有一定的参考价值。
什么是堆?
堆是一种非线性结构,可以把堆看作一个数组,也可以被看作一个完全二叉树,通俗来讲堆其实就是利用完全二叉树的结构来维护的一维数组但堆并不一定是完全二叉树
按照堆的特点可以把堆分为大顶堆和小顶堆
大顶堆:每个结点的值都大于或等于其左右孩子结点的值
小顶堆:每个结点的值都小于或等于其左右孩子结点的值
使用堆的原因?
如果仅仅是需要得到一个有序的序列,使用排序就可以很快完成,并不需要去组织一个新的数据结构。但是如果我们的需求是对于一个随时会有更新的序列,我要随时知道这个序列的最小值或最大值是什么。显然如果是线性结构,每次插入之后,假设原数组是有序的,那使用二分把它放在正确的位置也未尝不可,但是插入的时候从数组中留出空位就需要O(n)的时间复杂度,删除的时候亦然。
可是如果我们将序列看作是一个集合,我们需要的是这个集合的一个最小值或者最大值,并且,在它被任意划分成为若干个子集的时候,这些子集的最小值或者最大值我们也是知道的,这些子集被不断划分,我们依然知道这些再次被划分出来的子集的最小值或者最大值。而且我们去想办法去保持这样的一个性质,那么这个问题是不是变得非常好解决了呢?那么问题就转换成了一种集合之间的关系,并且是非常明显的一种包含关系,那么最适合于解决这种集合上的关系的数据结构是什么呢?那么就是树,所以就形成了这样的一种树,他的每一个节点都比它的子节点们小或者大。 当我们插入一个新的节点的时候,实际上我们需要去调整的大部分时候只是这棵树上的一条路径,也就是决定它在哪一个集合里面,树上的路径长度相对于这个集合,由于是对数级别的,所以非常可以接受,那么这种数据结构也就应运而生,而这个数据结构为什么叫做堆,那就不知道了。
堆的特点

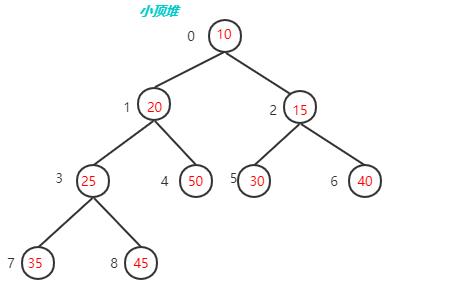
我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子
大顶堆 arr : 50 45 40 20 25 35 30 10 15
小顶堆 arr : 10 20 15 25 50 30 40 35 45
我们用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
其中arr[2i+1]是左节点 arr[2i+2]是右节点
堆和普通树的区别
内存占用:
普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配额外的内存。堆仅仅使用数组,且不使用指针
平衡:
二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(nlog2n)。你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足对属性即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(nlog2n) 的性能
搜索:
在二叉树中搜索会很快,但是在堆中搜索会很慢。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作
堆排序的过程
堆排序的基本思想 假设是构建大顶堆
1.将待排序的关键字序列(R1,R2,...Rn)构建大顶堆,此堆为初始的无序区.
2.将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区
(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3.由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,
然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。
不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。举例如下
1.给一个无序序列如下int a[6] = 7, 3, 8, 5, 1, 2
2.根据数组将完全二叉树还原出来

现在我们要做的事情就是要把7,3,8,5,1,2变成一个有序的序列,如果想要升序就是1,2,3,5,7,8如果想要降序就是8,7,5,3,2,1这两种就是我们要的最终结果,然后我们就可以根据我们想要的结果来选择
适合类型的堆来进行排序
- 升序----使用大顶堆
- 降序----使用小顶堆
3.为什么升序要用大顶堆呢
大顶堆的特点:每个结点的值都大于或等于其左右孩子结点的值,我们把大顶堆构建完毕后根节点的值一定是最大的,然后把根节点和最后一个元素(也可以说最后一个节点)交换位置,那么末尾元素此时就是最大元素了
4.图解交换过程
先要找到最后一个非叶子节点,数组的长度为6,那么最后一个非叶子节点就是:长度/2-1,也就是6/2-1=2,然后下一步就是比较该节点值和它的子树值,如果该节点小于其左\\右子树的值就交换(意思就是将最大的值放到该节点)
8只有一个左子树,左子树的值为2,8>2不需要调整
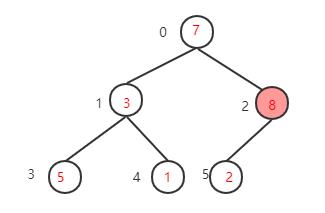
下一步,继续找到下一个非叶子节点
(其实就是当前坐标-1就行了这里为2-1=1),该节点的值为3小于其左子树的值5,交换值,交换后该节点值为5,大于其右子树的值1,不需要交换
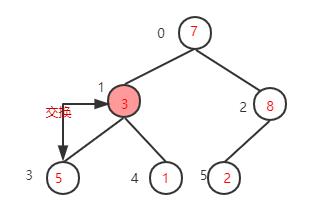
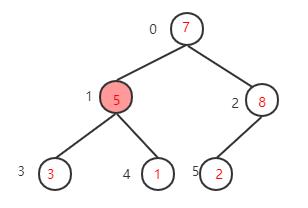
下一步,继续找到下一个非叶子节点1-1=0,该节点的值为7,大于其左子树的值,不需要交换,再看右子树,该节点的值小于右子树的值8,需要交换值
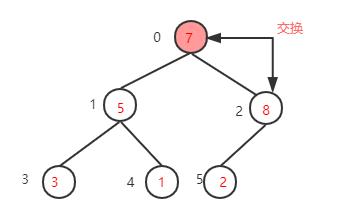

下一步,检查调整后的子树,是否满足大顶堆性质,如果不满足则继续调整(这里因为只将右子树的值与根节点互换,只需要检查右子树是否满足,而7>2刚好满足大顶堆的性质,就不需要调整了。如果运气不好整个数的根节点的值是1,那么就还需要调整右子树
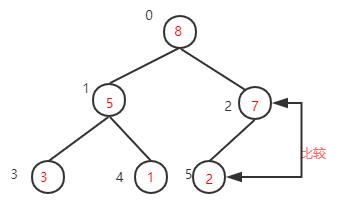
到这里大顶堆的构建就算完成了
然后下一步交换根节点8与最后一个元素2交换位置(将最大元素"沉"到数组末端),此时最大的元素就归位了,然后对剩下的5个元素重复上面的操作
这里用紫色来表示已经归位的元素
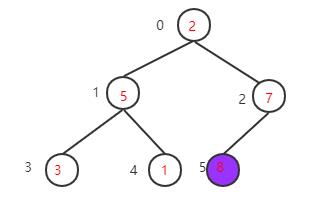
剩下只有5个元素,最后一个非叶子节点是5/2-1=1,该节点的值5大于左子树的值3也大于右子树的值1,满足大顶堆性质不需要交换
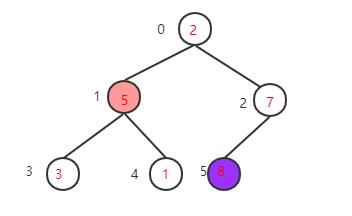
找到下一个非叶子节点,该节点的值2小于左子树的值5,交换值,交换后左子树的2不再满足大顶堆的性质再调整左子树,左子树满足要求后再返回去看根节点,根节点的值5小于右子树的值7,再次交换值
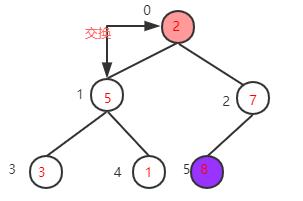


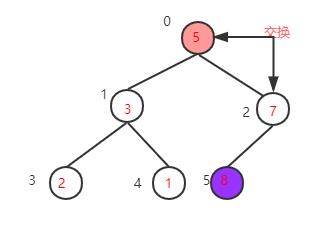
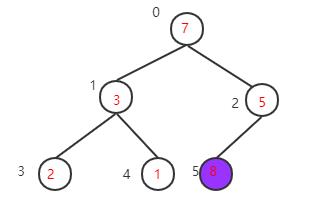
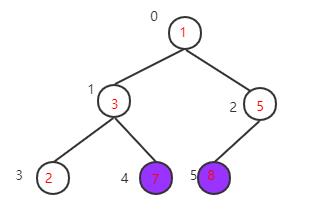
得到新的大顶堆,再把根节点的值7与当前数组最后一个元素值1交换,再重构大顶堆->交换值->重构大顶堆->交换值····,直到整个数组都变成有序序列

堆排序的代码实现
将堆排序的过程分成了两部分,构建一个大顶堆,就沉下去最大值,然后断开与最大值的链接,重新构建大顶堆
public class HeapSort
public static void BuildMaxHeap(int arr[], int n, int i)//n为完全二叉树个数,i为根节点位置
printArray(arr);
System.out.println("");
int largest = i; // 初始化根
int l = 2 * i + 1;
int r = 2 * i + 2;
// left > root
if (l < n && arr[l] > arr[largest])
largest = l; //largest表示此时最大值的位置
// right > root
if (r < n && arr[r] > arr[largest])
largest = r;
// 如果最大值不是根节点,调整
if (largest != i)
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
// BuildMaxHeap层层找到最最大值
BuildMaxHeap(arr, n, largest);
//打印函数
public static void printArray(int arr[])
int n = arr.length;
for (int i = 0; i < n; ++i)
System.out.print(arr[i] + " ");
public static void main(String[] args)
int arr[] = 7, 3, 8, 5, 1, 2;
int n = arr.length;
// 初始化堆 初始化后就可以得到 根节点为最大值
for (int i = n / 2 - 1; i >= 0; i--)
BuildMaxHeap(arr, n, i);
//依次把最大值沉下去 从右到左断开最后一个元素,重新构造大顶堆 也就是从小到大 排序
for (int i = n - 1; i >= 0; i--)
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
BuildMaxHeap(arr, i, 0);
// 打印结果
System.out.println("结果:");
printArray(arr);
/*
7 3 8 5 1 2
7 3 8 5 1 2
7 5 8 3 1 2
7 5 8 3 1 2
8 5 7 3 1 2
2 5 7 3 1 8
7 5 2 3 1 8
1 5 2 3 7 8
5 1 2 3 7 8
5 3 2 1 7 8
1 3 2 5 7 8
3 1 2 5 7 8
2 1 3 5 7 8
1 2 3 5 7 8
1 2 3 5 7 8
结果:
1 2 3 5 7 8
*/可以看到过程打印的数组值就是图解中的每步。
堆排序的最坏、最好、平均时间复杂度均为O(nlogn),是不稳定排序算法。
稳定指,如果a=b,a在b的前面,排序后a仍然在b的前面;不稳定指,如果a=b,a在b的前面,排序后可能会交换位置
注意:以上的大顶堆、小顶堆和用PriorityQueue实现的大顶堆、小顶堆不一样:
上述的大顶堆是从小到大排列的,实现原理不一样
PriorityQueue实现的小顶堆:是从小到大排列的
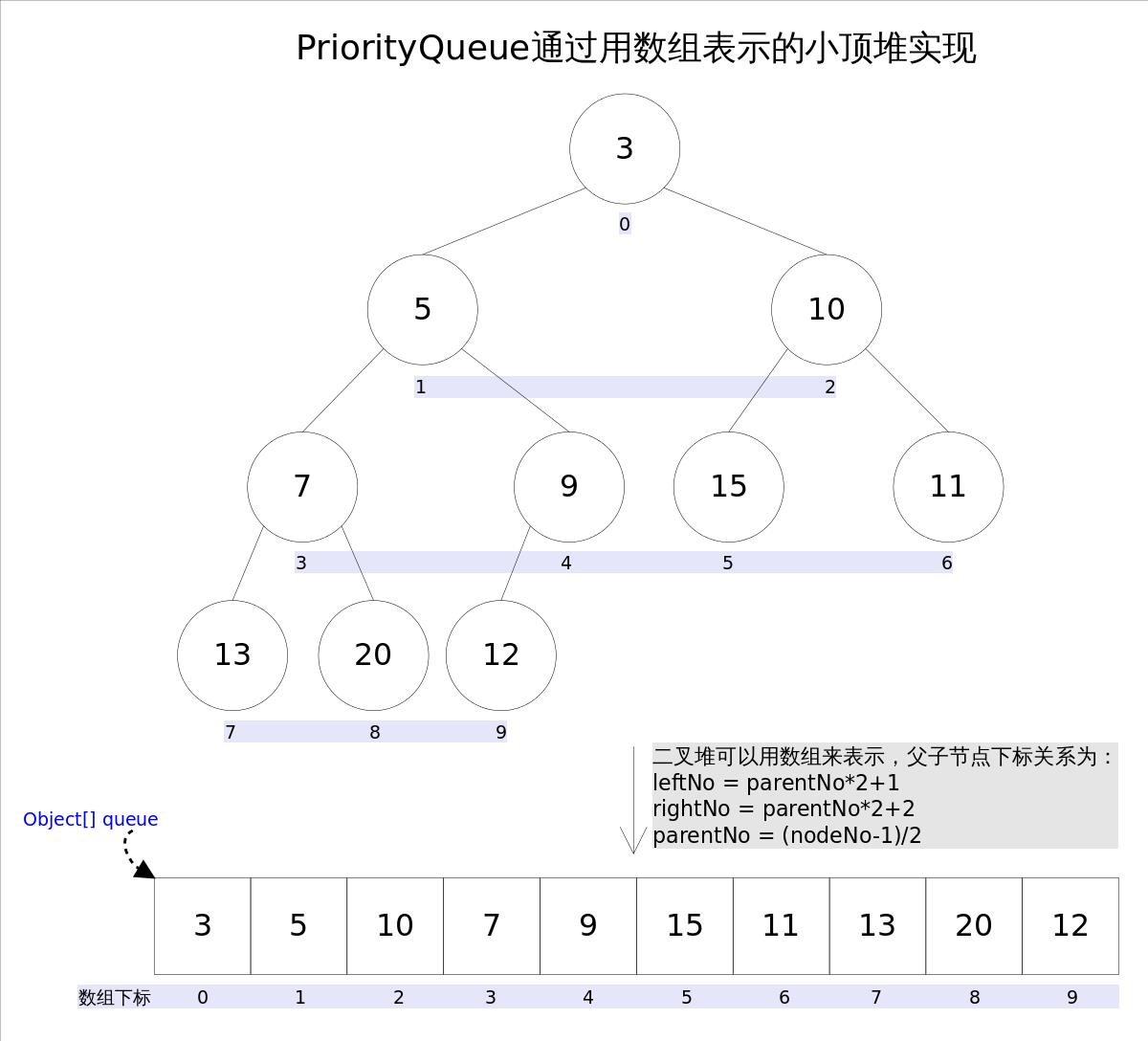
参考:https://www.jianshu.com/p/ffbe8b8d69e7
以上是关于大顶堆,小顶堆的主要内容,如果未能解决你的问题,请参考以下文章