中科院医工所工作笔记:数据量少多分割问题
Posted Mario cai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中科院医工所工作笔记:数据量少多分割问题相关的知识,希望对你有一定的参考价值。
面对标注数据量非常少(影像科医生是稀有资源)的多分类问题
先放出代码
https://github.com/caihaihua057200/Inf-Net
引用一篇大佬的论文
论文中文版http://dpfan.net/wp-content/uploads/TMI20_InfNet_Chinese_Finalv2.pdf
Inf-Net: Automatic COVID-19 Lung Infection Segmentation From CT Images
这篇论文被IEEE收录并且置顶,最良心的是作者放出代码。
论文灵感:
源于临床医生在肺部感染检测过程中,首先对感染区域进行粗略定位,然后根据局部症状准确提取其轮廓。
因此,我们认为区域和边界是区分正常组织和感染的两个关键特征。
因此,我们的网络首先预测粗糙区域(PPD),然后通过反向注意和边界约束引导隐式建模边界,
显式增强边界识别。整个过程大概就这样:
所以根据灵感,作者创造出这个网路
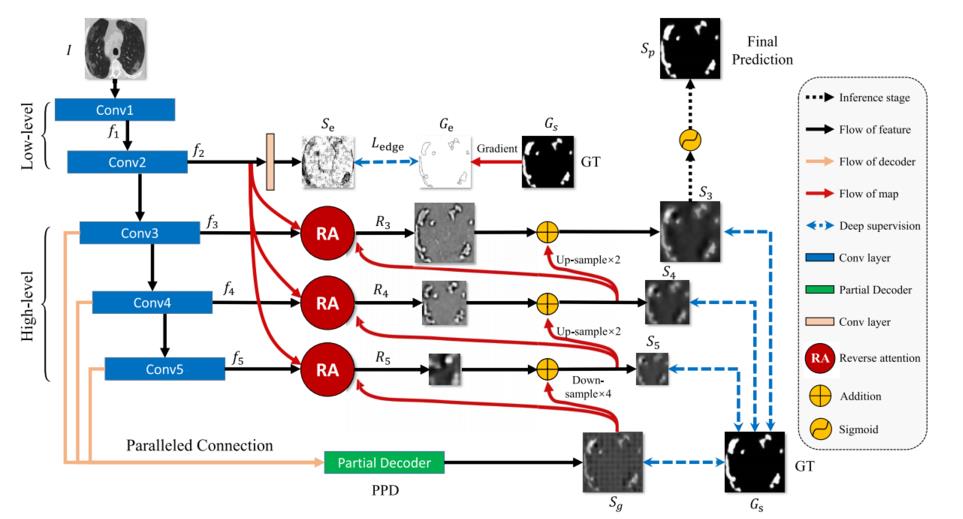
看起来有点复杂,咱们慢慢一步步刨析:
第一步:边缘注意模块
图片进入模型,经过5层卷积,其中前两层为低级特征(边缘信息明显),后三层为高级特征,这样做可以通过连接将所有不同的特征集合在一起。
2、低级特征进入EA模块。
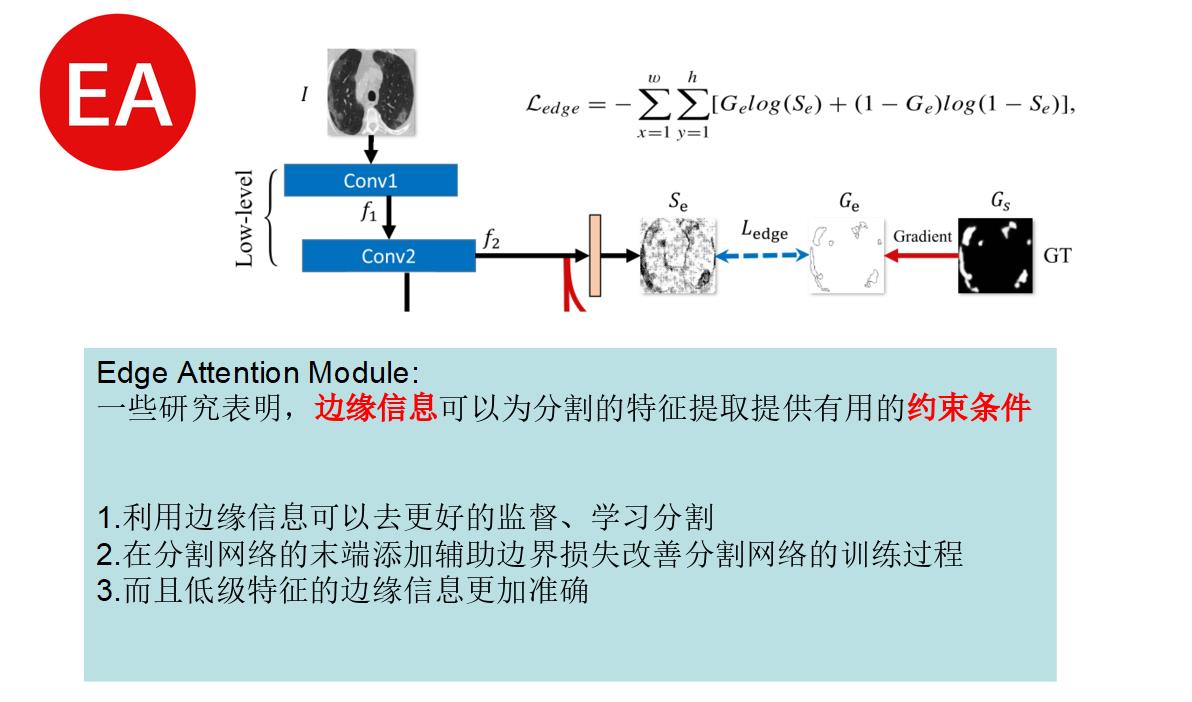
这里作者引用了几个论文,主要就是告诉大家,边缘信息可以优化网络。
对图片求梯度可以得到边缘信息,也可以使用该代码批量获取
import cv2
import numpy as np
import glob
def auto_canny(image, sigma=0.33):
# Compute the median of the single channel pixel intensities
v = np.median(image)
# Apply automatic Canny edge detection using the computed median
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 + sigma) * v))
return cv2.Canny(image, lower, upper)
# Read in each image and convert to grayscale
images = [cv2.imread(file,0) for file in glob.glob(r"C:\\Users\\Admin\\SIAT\\Inf-Net-master\\Dataset\\TrainingSet\\LungInfection-Train\\Doctor-label\\GT/*.png")]
# Iterate through each image, perform edge detection, and save image
number = 0
for image in images:
canny = auto_canny(image)
cv2.imwrite('canny_.png'.format(number), canny)
number += 1
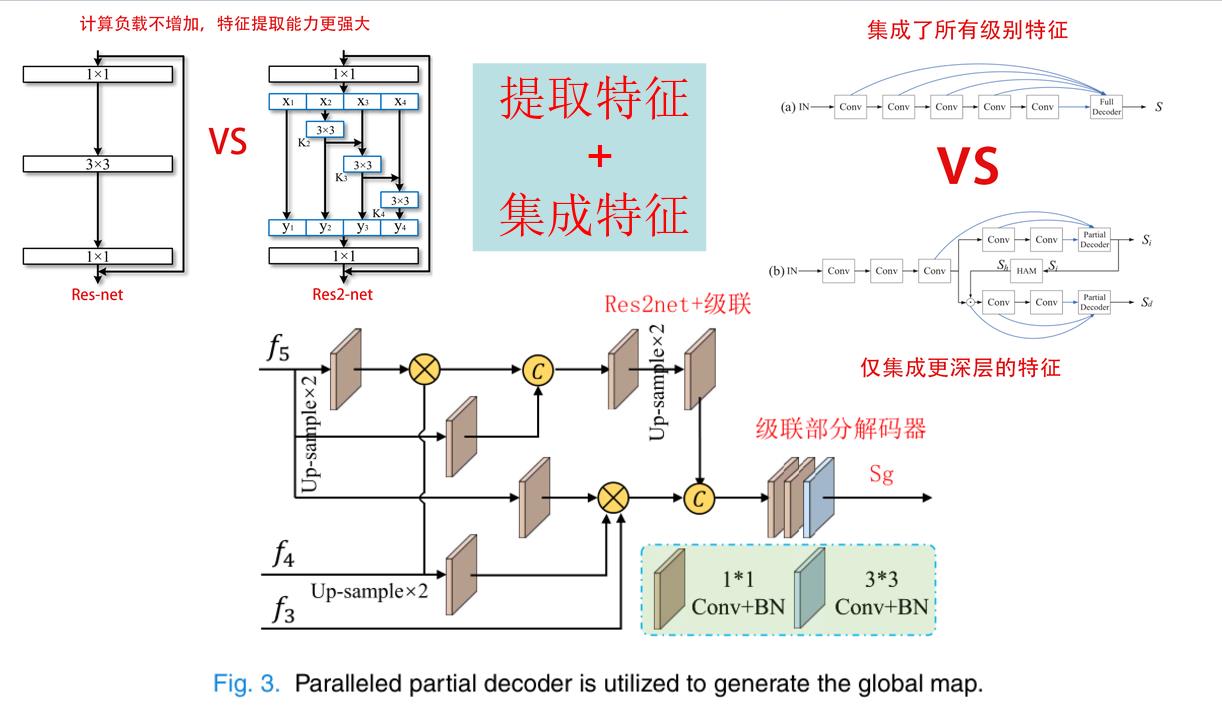
第二步:粗略提取模块
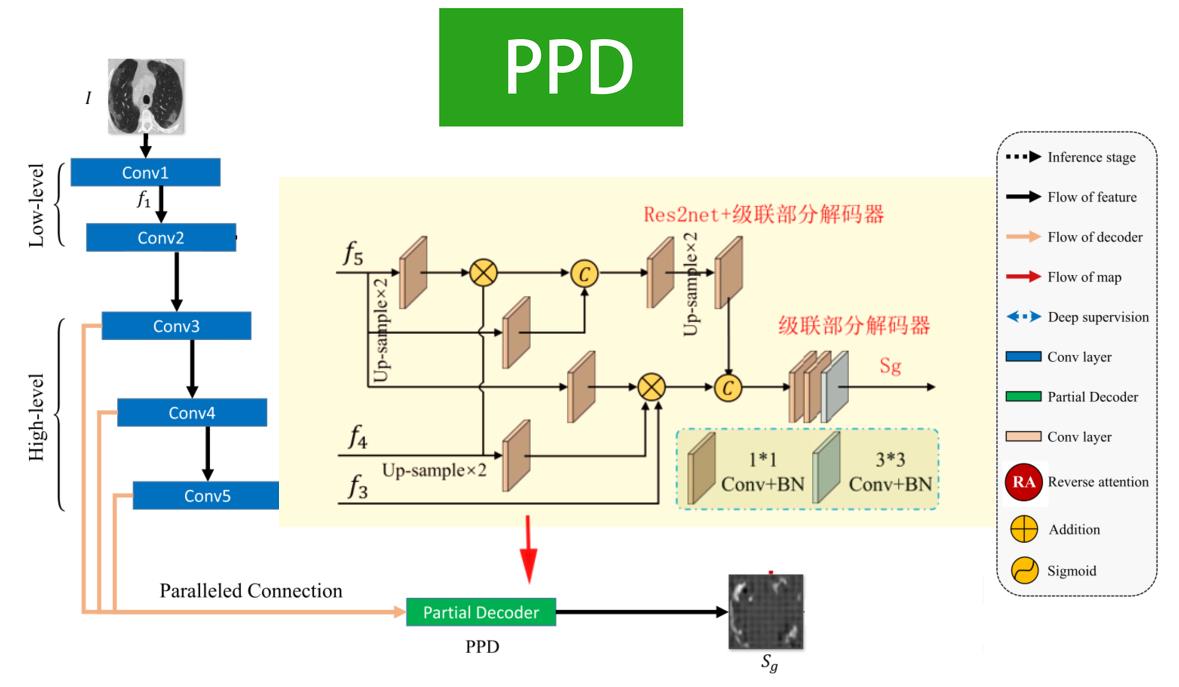
刨析一下PPD内部,他使用了RES2的前五层,末尾加上部分解码器
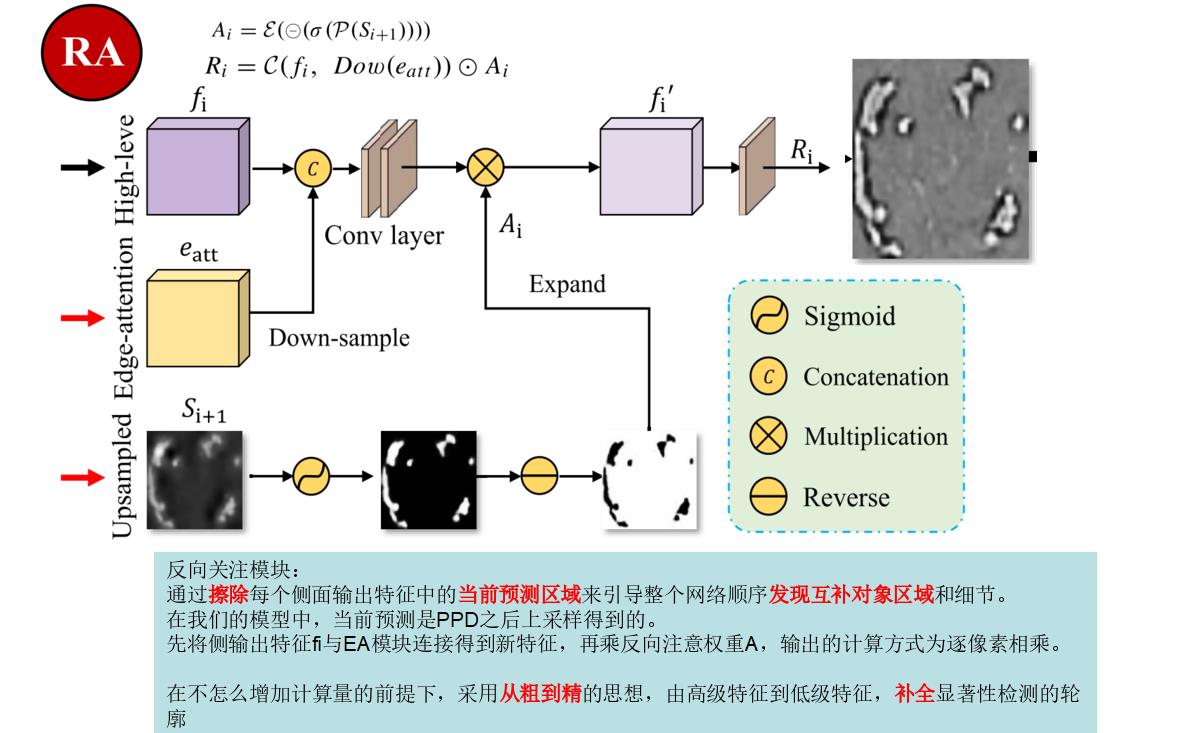
第三步:RA模块,反向注意模块
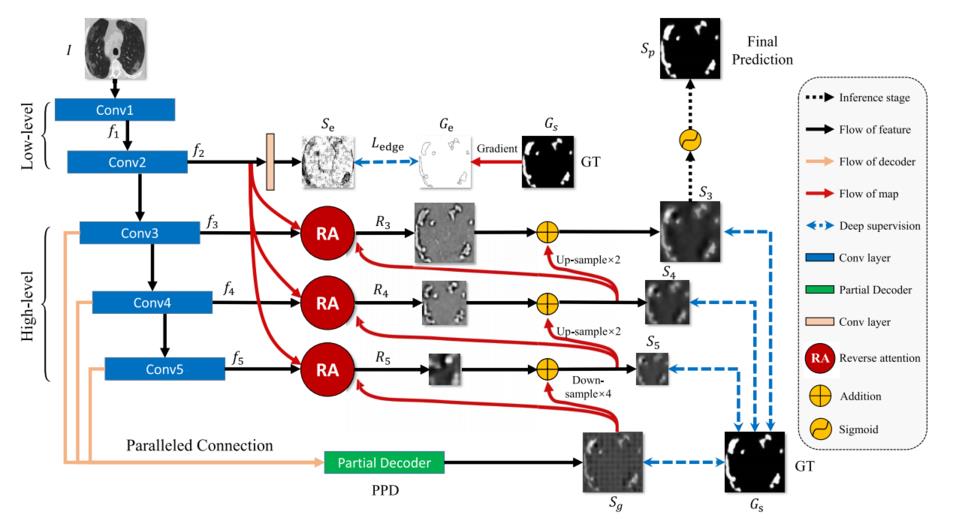
经过完所有模块之后网络初步完成
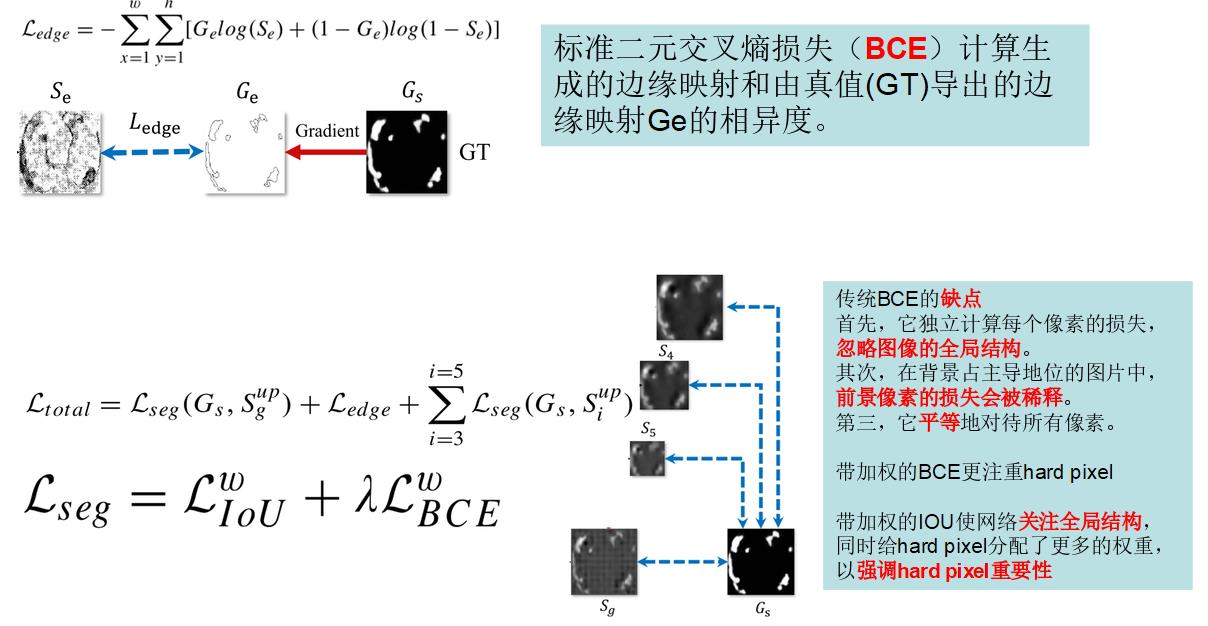
这里作者还对LOSS进行了修改,修改如下
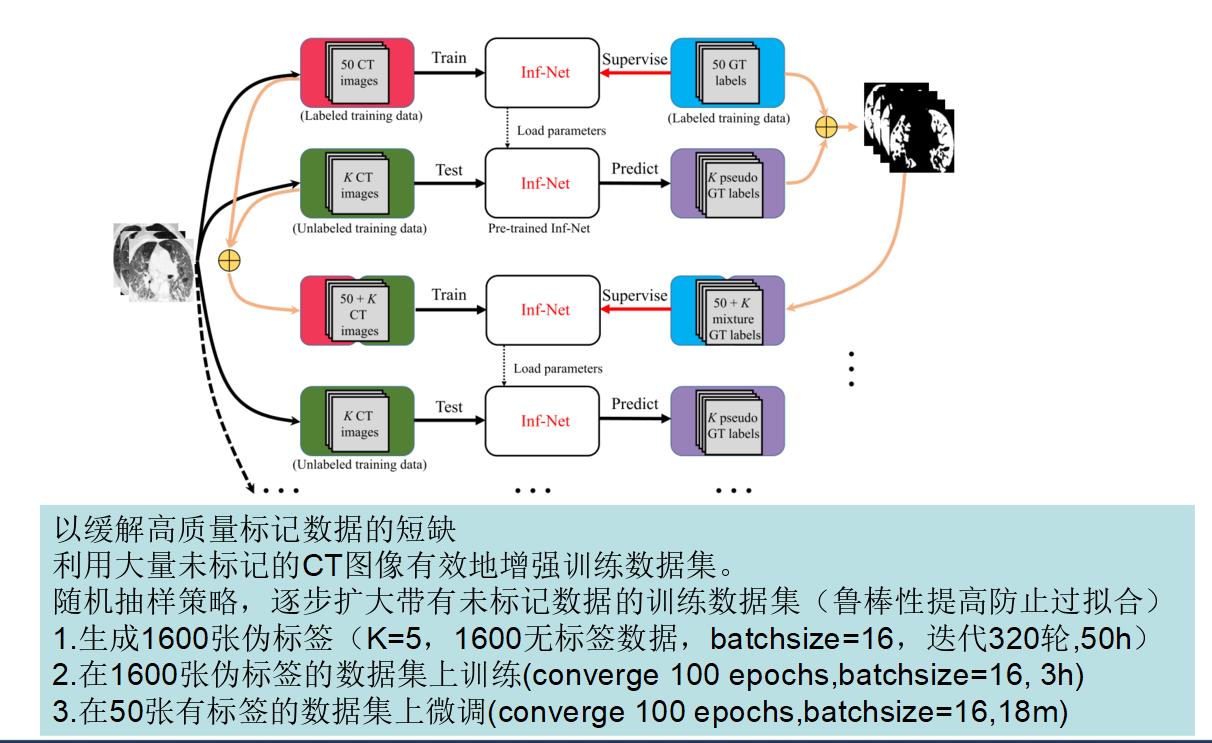
第四步:半监督学习
开始训练,因为数据量少,使用半监督学习(随机采样慢慢优化提高鲁棒性)
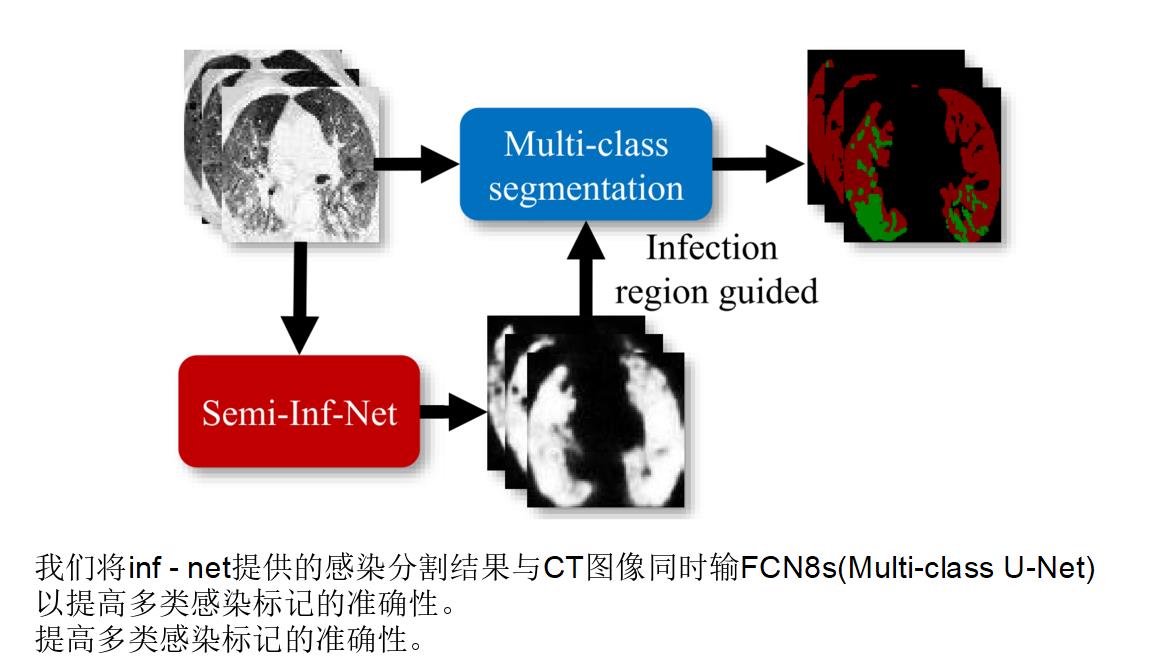
最后一步:加入多分类模型
加入多分类模型(UNET、UNET++…)
评估指标:

训练结果:
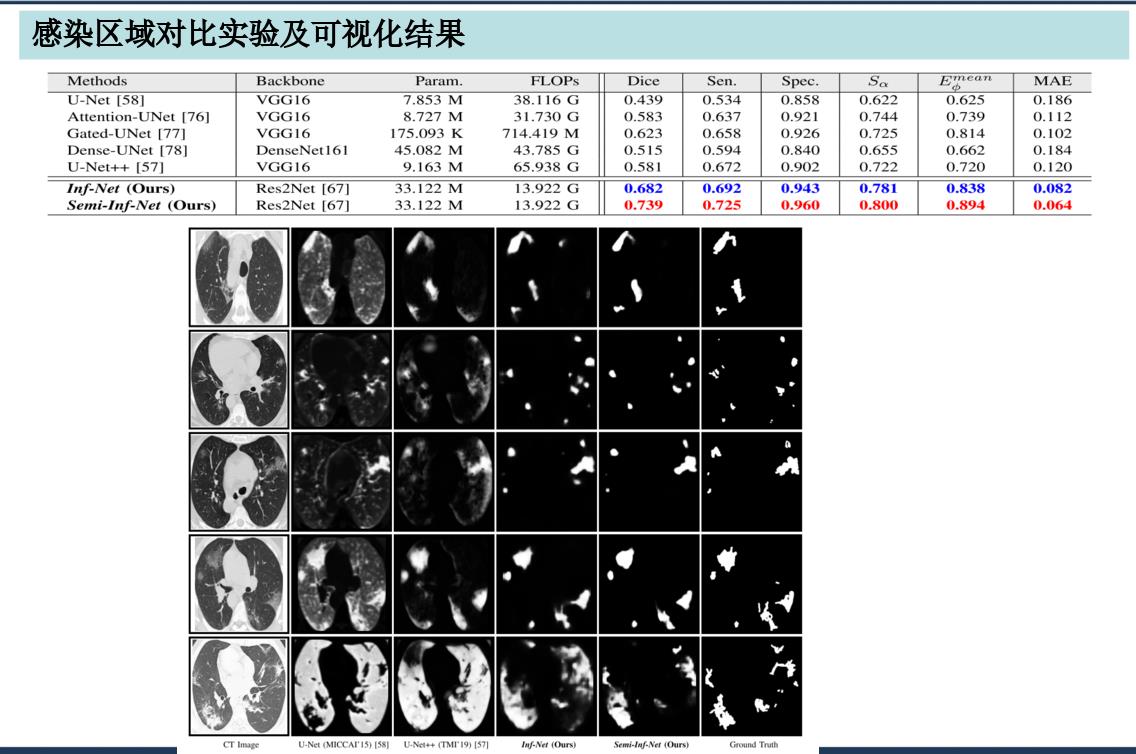
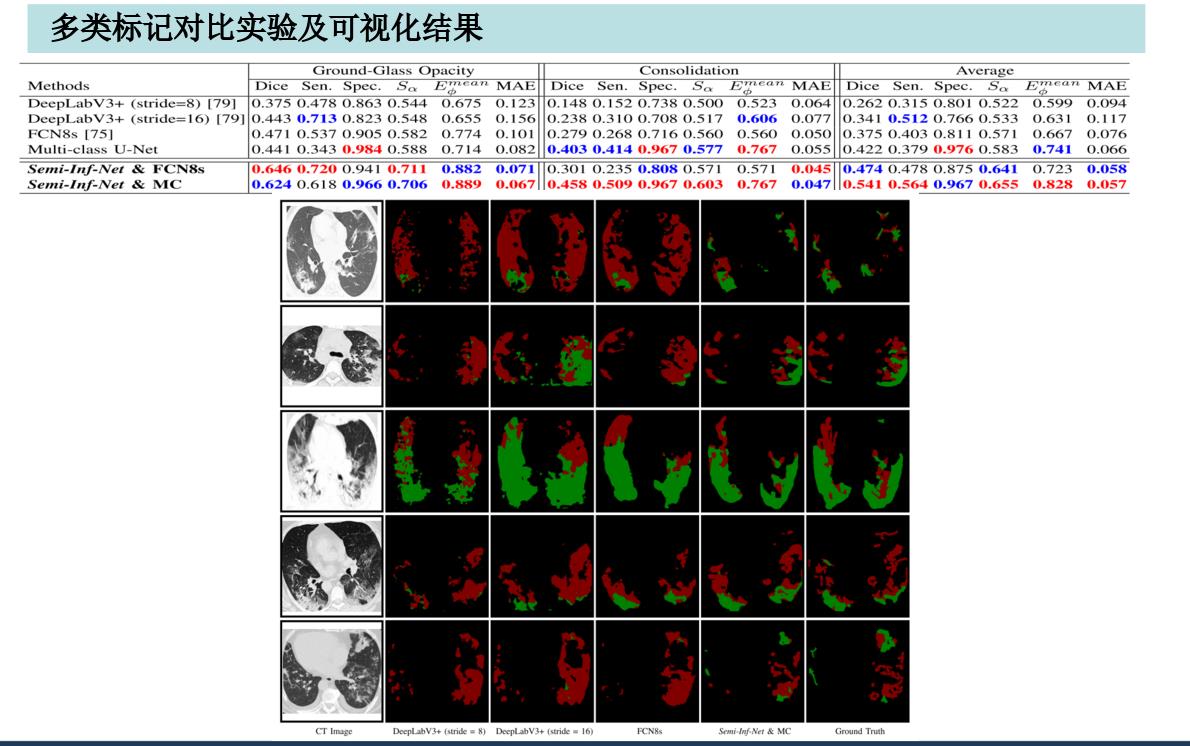
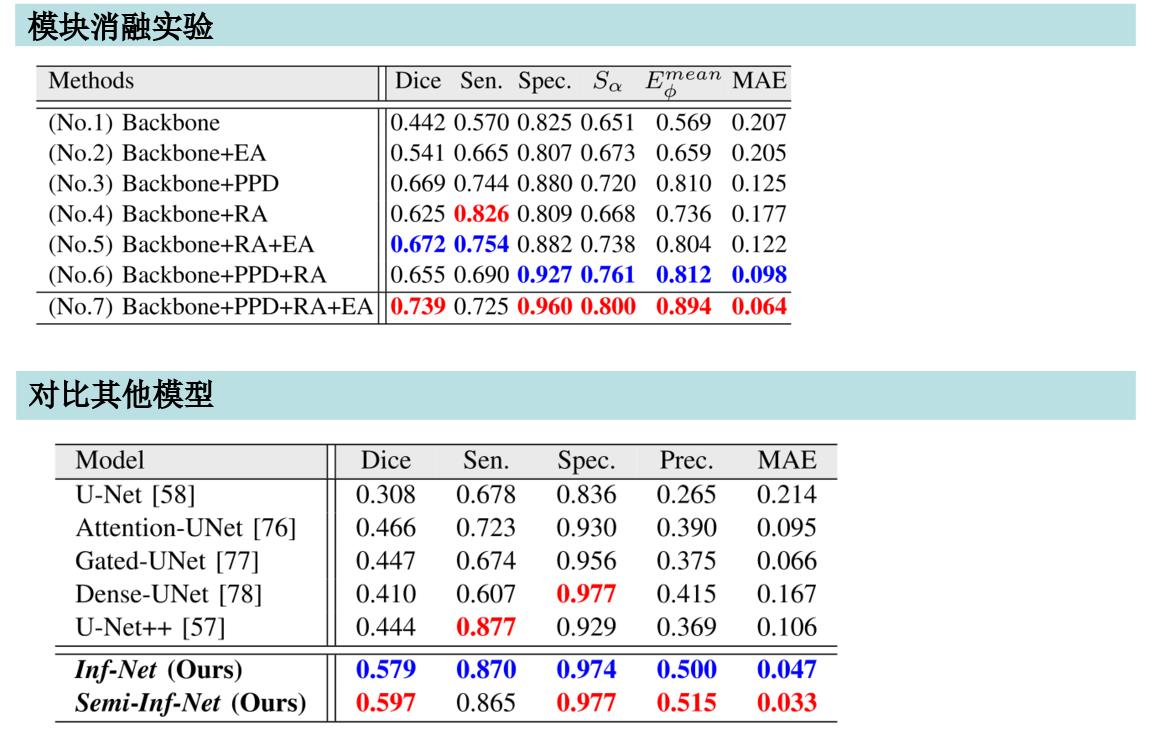
实验证明,该模型在数据少的情况下非常厉害
以上是关于中科院医工所工作笔记:数据量少多分割问题的主要内容,如果未能解决你的问题,请参考以下文章