Python多CPU(核)并行数据处理解决方案
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python多CPU(核)并行数据处理解决方案相关的知识,希望对你有一定的参考价值。
Python 进行数据处理的时候,因为有GIL锁,因此多线程也只能使用一个处理器,这样经常出现程序运行只使用了一个CPU核心在运算,导致数据处理需要比较长的时间。如果将多个CPU核心同时参与运算,可以大幅度运算速度,下面讨论原则上不修改程序而发挥多CPU效率方案。
其中,GIL 的全称为 Global Interpreter Lock ,意即全局解释器锁。
- 数据处理多使用Numpy
- Scikit-Learn中使用多CPU任务
- 使用modin.pandas替换pandas
- 数据分批次处理
1. Numpy使用多CPU(核)与OpenBLAS
1.1. Numpy多任务
python因为有GIL锁,因此多线程也只能使用一个处理器,但是numpy是例外,因为numpy内部是用C写的,不经过python解释器,因此它本身的矩阵运算(array operations)都可以使用多核,此外它内部还用了BLAS(the Basic Linear Algebra Subroutines),因此可以进一步优化计算速度。
并非所有NumPy都使用BLAS,只有一些功能 , 特别是dot()、vdot()、innerproduct()和numpy.linalg
1.2. OpenBLAS及其安装步骤
1.2.1. OpenBLAS
OpenBLAS 是一个基于BSD许可(开源)发行的优化 BLAS 计算库。BLAS(Basic Linear Algebra Subprograms 基础线性代数程序集)是一个应用程序接口(API)标准,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法),OpenBLAS是BLAS标准的一种具体实现。
https://github.com/xianyi/OpenBLAS/
https://github.com/xianyi/OpenBLAS/wiki/Installation-Guide
1.2.2. OpenBLAS 安装
环境要求:Centos需要gcc及g++ ,如果没有则安装gcc命令,yum install gcc 。(详情,请查资料)
(1)下载最新的openblas
git clone https://github.com/xianyi/OpenBLAS.git
如果没有安装git,先安装git 。
CentOS安装git
yum install git
(2)打开 OpenBLAS
下载后,生成OpenBLAS目录。
[root@DeepLearning]#cd OpenBLAS
(3)安装依赖gfortran
如果没有安装gfortran,centos安装gfortran
[root@DeepLearning OpenBLAS]# yum install gcc-gfortran
[root@DeepLearning OpenBLAS]# make FC=gfortran
(4)将OpenBLAS安装到/opt下
[root@DeepLearning OpenBLAS]# make install
To install the library, you can run “make PREFIX=/path/to/your/installation install”.
安装完成后,查看目录内容:
[root@DeepLearning python]# ls /opt
eclipse google neo4j OpenBLAS rh
(5)执行以下命令完成安装
ln -s /opt/OpenBLAS/lib/libopenblas.so /usr/lib/libblas.so.3
ln -s /opt/OpenBLAS/lib/liblapack.so.3 /usr/lib/liblapack.so.3
(6)在/etc/profile中加入
在/etc/profile中加入
LD_LIBRARY_PATH=/opt/OpenBLAS/lib
export LD_LIBRARY_PATH
(7)重新启动配置
[root@DeepLearning python]#source /etc/profile
1.3. 重新安装Numpy
由于数据计算环境持续计算中的原因,此部分内容还未验证,谨慎实践!
1.3.1. 获取numpy源代码
[root@DeepLearning python]# git clone https://github.com/numpy/numpy
[root@DeepLearning python]# cd numpy
1.3.2. 编辑site.cfg配置文件
拷贝 site.cfg.example到 site.cfg 并且编辑此拷贝:
[root@DeepLearning python]# cp site.cfg.example site.cfg
[default]
include_dirs = /opt/OpenBLAS/include
library_dirs = /opt/OpenBLAS/lib
[openblas]
openblas_libs = openblas
include_dirs = /opt/OpenBLAS/include
library_dirs = /opt/OpenBLAS/lib
[lapack]
lapack_libs = openblas
[atlas]
atlas_libs = openblas
libraries = openblas
1.3.3. 检查配置,构建和安装
检查配置
[root@DeepLearning python]# python setup.py config
输出应如下所示:
openblas_info:
FOUND:
libraries = ['openblas', 'openblas']
library_dirs = ['/opt/OpenBLAS/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
FOUND:
libraries = ['openblas', 'openblas']
library_dirs = ['/opt/OpenBLAS/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
重新安装Numpy
[root@DeepLearning python]#python setup.py install
与安装pip比较,因为pip将跟踪包的元数据,让你轻松卸载或将来升级numpy的。
[root@DeepLearning python]# pip install .
2. Scikit-Learn中使用多CPU任务
使用 Python 在 scikit-learn 机器学习库 通过 n_jobs 参数提供此功能,例如模型训练、模型评估和超参数调整。
- n_jobs=None:使用单核或后端库配置的默认值。
- n_jobs=4:使用指定数量的核心。
- n_jobs=-1:使用所有可用的内核。
3. 使用modin.pandas替换pandas
Modin是一个Python第三方库,可以通过并行来处理大数据集。它的语法和pandas非常相似,因其出色的性能,能弥补Pandas在处理大数据上的缺陷。

modin.pandas 确实能使得一部分函数使用多核cpu进行加速处理,但是现在有些功能还不完善,有些函数还是用的默认pandas处理。
https://github.com/modin-project/modin
https://modin.readthedocs.io/en/latest/index.html
Modin使用Ray或Dask作为后端
Dask既可以作为Modin的后端引擎,也能单独并行处理DataFrame,提高数据处理速度。
Modin 利用 Ray 以毫不费力的方式加速 Pandas 的 notebook、脚本和程序库。Ray 是一个针对大规模机器学习和强化学习应用的高性能分布式执行框架。同样的代码可以在单台机器上运行以实现高效的多进程,也可以在集群上用于大型计算。你可以通过下面的 GitHub 链接获取 Ray:http://github.com/ray-project/ray。
3.1. 安装modin.pandas
[root@DeepLearning python]#pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modin[all]
安装内容:
| modin-0.8.3 | ray-1.12.0 | dask-2.19.0 | filelock-3.4.1 | botocore-1.8.50 |
|---|---|---|---|---|
| distlib-0.3.4 | distributed-2.19.0 | docutils-0.18.1 | boto3-1.4.8 | frozenlist-1.2.0 |
| heapdict-1.0.1 | importlib-resources-5.4.0 | jmespath-0.10.0 | cloudpickle-1.4.1 | msgpack-1.0.3 |
| platformdirs-2.4.0 | plumbum-1.7.2 | protobuf-3.19.4 | psutil-5.9.0 | pyarrow-1.0.0 |
| aiosignal-1.2.0 | rpyc-4.1.5 | s3transfer-0.1.13 | sortedcontainers-2.4.0 | tblib-1.7.0 |
| virtualenv-20.14.1 | zict-2.1.0 |
3.2. 使用modin.pandas
import modin.pandas as pd
import modin.config as cfg
cfg.Engine.put("dask")
df = pd.DataFrame([0,1,2,3])
3.3. 使用注意或出现的错误
3.3.1. 运行错误
使用 if name == ‘main’:,控制程序线程范围。
错误发生,如果使用modin.pabdas,运行程序,如果出现如下错误:[7]
Error when using Dask engine: RuntimeError: if __name__ == '__main__':
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
解决方案:
import modin.pandas as pd
import modin.config as cfg
cfg.Engine.put("dask")
if __name__ == "__main__":
df = pd.DataFrame([0, 1, 2, 3]) # Dask Client creation is hidden in the first call of Modin functionality.
print(df)
3.3.2. modin.pandas局限性
modin没有兼容所有的pandas方法,但是大部分常见操作还是可以用的。
3.3.3. 与Clickhouse结合
from clickhouse_driver import Client
import pandas as pd
import modin.pandas as mpd
price_sql = '''SELECT DIM_ID, DIM_DATE, V_0, V_92, V_95, V_89, CITYNAME, ZDE_0, ZDE_92,
ZDE_95, ZDE_89, QE_0, QE_92, QE_95, QE_89 FROM price
order by DIM_DATE DESC
'''
client = Client(host=host,
port=port,
database=database,
user=user,
password=password,
connect_timeout=connect_timeout) #, send_receive_timeout=send_receive_timeout)
df=client.query_dataframe(price_sql)
df
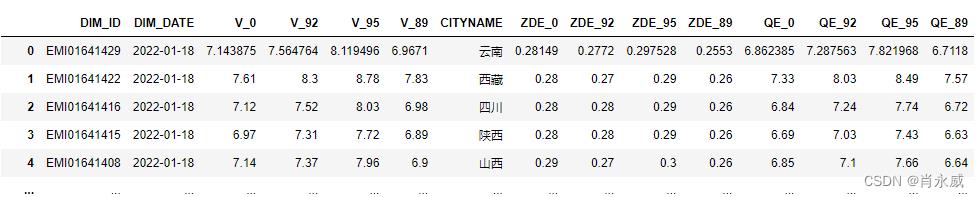
把pandas的DataFrame转换为modin.pandas。
mdf = mpd.DataFrame(df)
mdf

4. 数据分批次处理
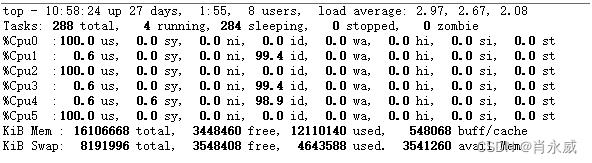
按每CPU使用内存4G计算,控制python程序使用内容,发挥出CPU与内存的配比。通常专家建议:cpu占用率在0%–75%之间变化是正常的。
启动三个进程效果如下:
[python@DeepLearning ~]$python3 FeatureEngineeringProcess.py

5. 总结
虽然Python中的多线程是表面上的多线程(同一时刻只有一个线程),不是真正的多线程。但是,Python在多CPU(核)并行数据处理方面是有解决方案的。
我们可以把Python看做模块连接器,使用第三方专业包完成多CPU(核)并行数据处理,以及从数据、模型等多角度综合分布计算处理。
- 首先,在操作系统层面使用BLAS,在编程方面多使用第三方Numpy,发挥Numpy并行数据计算处理能力。
- 其次,合理使用modin.pandas与原生pandas,发挥各自的优势。
- 使用支持并行计算的专用算法包,例如:XGBoost、Scikit-Learn、Tensorflow等。
- 在数据模型、算法模型设计开发时,采用减少依赖、分布计算原则,人工分散计算,例如拆分Tensorflow计算图,以及本案例中,数据处理拆分数据集分散到不同处理器上计算处理。
上述方案中,最直接、简单、可控的方法是采用分布计算原则设计、开发数据模型和算法模型。个人经验总结,仅供参考,欢迎多交流。
参考:
[1]. ROMAN KH. How to make numpy use several CPUs. 2015.12
[2]. Long Wang, Rick Y Wang, and Ken Lu. Improving Python* NumPy Performance on Kubernetes* using Clear Linux* OS. Clear Linux* Project. 2020.03
[3]. 枫依流水. CentOS7安装OpenBLAS的简单步骤. CSDN博客. 2018.08
[4]. Mr数据杨. Scikit-Learn在Python中进行多CPU内核机器学习方法. 知乎. 2022.02
[5]. ThomasYoungK. numpy如何并行计算. 简书. 2018.07
[6]. 朱卫军. Modin,只需一行代码加速你的Pandas. 腾讯云. 2022.04
[7]. troubleshooting. Error when using Dask engine: RuntimeError: if name == ‘main’:
[8]. i-kernel. TensorFlow使用并行计算. CSDN博客. 2019.12
以上是关于Python多CPU(核)并行数据处理解决方案的主要内容,如果未能解决你的问题,请参考以下文章