POJ 2774 Long Long Message(后缀数组[最长公共子串])
Posted queuelovestack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了POJ 2774 Long Long Message(后缀数组[最长公共子串])相关的知识,希望对你有一定的参考价值。
此文章可以使用目录功能哟↑(点击上方[+])
 POJ 2774 Long Long Message
POJ 2774 Long Long Message
Accept: 0 Submit: 0
Time Limit: 4000 MS Memory Limit : 131072 K
 Problem Description
Problem Description
The little cat is majoring in physics in the capital of Byterland. A piece of sad news comes to him these days: his mother is getting ill. Being worried about spending so much on railway tickets (Byterland is such a big country, and he has to spend 16 shours on train to his hometown), he decided only to send SMS with his mother.
The little cat lives in an unrich family, so he frequently comes to the mobile service center, to check how much money he has spent on SMS.
Yesterday, the computer of service center was broken, and printed two very long messages. The brilliant little cat soon found out:
1. All characters in messages are lowercase Latin letters, without punctuations and spaces.
2. All SMS has been appended to each other – (i+1)-th SMS comes directly after the i-th one – that is why those two messages are quite long.
3. His own SMS has been appended together, but possibly a great many redundancy characters appear leftwards and rightwards due to the broken computer.
E.g: if his SMS is “motheriloveyou”, either long message printed by that machine, would possibly be one of “hahamotheriloveyou”, “motheriloveyoureally”, “motheriloveyouornot”, “bbbmotheriloveyouaaa”, etc.
4. For these broken issues, the little cat has printed his original text twice (so there appears two very long messages). Even though the original text remains the same in two printed messages, the redundancy characters on both sides would be possibly different.
You are given those two very long messages, and you have to output the length of the longest possible original text written by the little cat.
Background:
The SMS in Byterland mobile service are charging in dollars-per-byte. That is why the little cat is worrying about how long could the longest original text be.
Why ask you to write a program? There are four resions:
1. The little cat is so busy these days with physics lessons;
2. The little cat wants to keep what he said to his mother seceret;
3. POJ is such a great Online Judge;
4. The little cat wants to earn some money from POJ, and try to persuade his mother to see the doctor :(
Input
Two strings with lowercase letters on two of the input lines individually. Number of characters in each one will never exceed 100000.
Output
A single line with a single integer number – what is the maximum length of the original text written by the little cat.
Sample Input
yeshowmuchiloveyoumydearmotherreallyicannotbelieveit
yeaphowmuchiloveyoumydearmother
Sample Output
27
Problem Idea
解题思路:
【题意】
题目咯哩啰嗦一大堆,还不如直接看样例
就是给你两个字符串,求两个字符串的最长公共子串
例如样例中的最长公共子串为"howmuchiloveyoumydearmother"
【类型】
后缀数组[最长公共子串]
【分析】
此题是一道裸的后缀数组题
"最长公共子串"解法(摘自罗穗骞的国家集训队论文):
字符串的任何一个子串都是这个字符串的某个后缀的前缀。 求A和B的最长公共子串等价于求A的后缀和B的后缀的最长公共前缀的最大值。如果枚举A
和B的所有的后缀, 那么这样做显然效率低下。 由于要计算A的后缀和B的后缀的最长公共前缀, 所以先将第二个字符串写在第一个字符串后面, 中间用一个没有出现过的字符隔开,再求这个新的字符串的后缀数组。观察一下,看看能不能从这个新的字符串的后缀数组中找到一些规律。以A=“ aaaba”, B=“ abaa” 为例,如图所示。
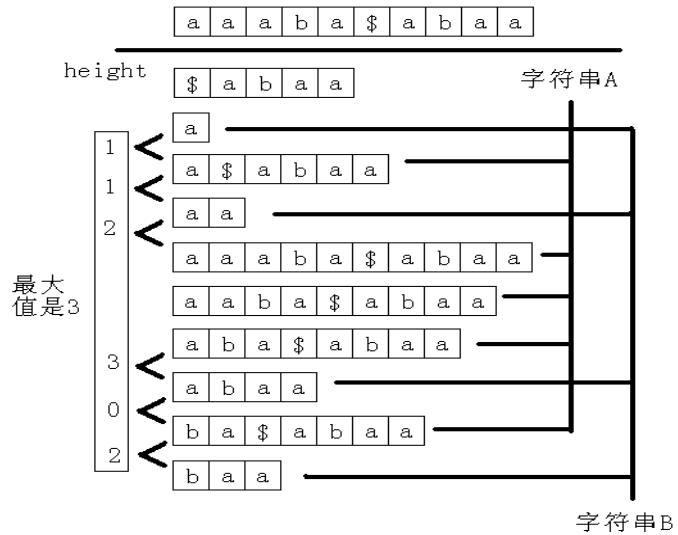
那么是不是所有的height值中的最大值就是答案呢?不一定!有可能这两个后缀是在同一个字符串中的,所以实际上只有当 suffix(sa[i-1])和suffix(sa[i])不是同一个字符串中的两个后缀时, height[i]才是满足条件的。而这其中的最大值就是答案。 记字符串A和字符串B的长度分别为|A|和|B|。 求新的字符串的后缀数组和height数组的时间是O(|A|+|B|),然后求排名相邻但原来不在同一个字符串中的两个后缀的 height 值的最大值,时间也是O(|A|+|B|),所以整个做法的时间复杂度为O(|A|+|B|)。时间复杂度已经取到下限,由此看出,这是一个非常优秀的算法。
ps:因为两个字符合成一个字符时,中间(位置k)会用一个没有出现过的字符隔开,所以判断两个后缀是不是同一个字符串可以借助这个位置k
即当(sa[i]-k)*(sa[i-1]-k)<0时,两个后缀属于不同的字符串,此题求乘积时可能会爆int,注意一下即可
【时间复杂度&&优化】
O(nlogn)
题目链接→POJ 2774 Long Long Message
Source Code
/*Sherlock and Watson and Adler*/
#pragma comment(linker, "/STACK:1024000000,1024000000")
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<queue>
#include<stack>
#include<math.h>
#include<vector>
#include<map>
#include<set>
#include<bitset>
#include<cmath>
#include<complex>
#include<string>
#include<algorithm>
#include<iostream>
#define eps 1e-9
#define LL long long
#define PI acos(-1.0)
#define bitnum(a) __builtin_popcount(a)
using namespace std;
const int N = 10;
const int M = 100005;
const int inf = 1000000007;
const int mod = 1000000007;
const int MAXN = 200005;
//rnk从0开始
//sa从1开始,因为最后一个字符(最小的)排在第0位
//height从1开始,因为表示的是sa[i - 1]和sa[i]
//倍增算法 O(nlogn)
int wa[MAXN], wb[MAXN], wv[MAXN], ws_[MAXN];
//Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
//待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
//为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
//同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
//函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
void Suffix(int *r, int *sa, int n, int m)
int i, j, k, *x = wa, *y = wb, *t;
//对长度为1的字符串排序
//一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
//如果r的最大值很大,那么把这段代码改成快速排序
for(i = 0; i < m; ++i) ws_[i] = 0;
for(i = 0; i < n; ++i) ws_[x[i] = r[i]]++;//统计字符的个数
for(i = 1; i < m; ++i) ws_[i] += ws_[i - 1];//统计不大于字符i的字符个数
for(i = n - 1; i >= 0; --i) sa[--ws_[x[i]]] = i;//计算字符排名
//基数排序
//x数组保存的值相当于是rank值
for(j = 1, k = 1; k < n; j *= 2, m = k)
//j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
//第二关键字排序
for(k = 0, i = n - j; i < n; ++i) y[k++] = i;//第二关键字为0的排在前面
for(i = 0; i < n; ++i) if(sa[i] >= j) y[k++] = sa[i] - j;//长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
for(i = 0; i < n; ++i) wv[i] = x[y[i]];//提取第一关键字
//按第一关键字排序 (原理同对长度为1的字符串排序)
for(i = 0; i < m; ++i) ws_[i] = 0;
for(i = 0; i < n; ++i) ws_[wv[i]]++;
for(i = 1; i < m; ++i) ws_[i] += ws_[i - 1];
for(i = n - 1; i >= 0; --i) sa[--ws_[wv[i]]] = y[i];//按第一关键字,计算出了长度为2 * j的子串排名情况
//此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
//计算长度为2 * j的子串的排名情况,保存到数组x
t = x;
x = y;
y = t;
for(x[sa[0]] = 0, i = k = 1; i < n; ++i)
x[sa[i]] = (y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j]) ? k - 1 : k++;
//若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
int Rank[MAXN], height[MAXN], sa[MAXN], r[MAXN];
void calheight(int *r,int *sa,int n)
int i,j,k=0;
for(i=1; i<=n; i++)Rank[sa[i]]=i;
for(i=0; i<n; height[Rank[i++]]=k)
for(k?k--:0,j=sa[Rank[i]-1]; r[i+k]==r[j+k]; k++);
char s[MAXN];
int main()
int k,n,i,Max;
while(~scanf("%s",s))
Max=0;
k=strlen(s);
s[k]='z'+1;
scanf("%s",s+k+1);
n=strlen(s);
for(i=0;i<n;i++)
r[i]=s[i]-'a'+1;
r[i]=0;
Suffix(r,sa,n+1,28);
calheight(r,sa,n);
for(i=1;i<=n;i++)
if(height[i]>Max&&1ll*(sa[i]-k)*(sa[i-1]-k)<0)
Max=height[i];
printf("%d\\n",Max);
return 0;
以上是关于POJ 2774 Long Long Message(后缀数组[最长公共子串])的主要内容,如果未能解决你的问题,请参考以下文章