Promethus概览
Posted shark_西瓜甜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Promethus概览相关的知识,希望对你有一定的参考价值。
这里写自定义目录标题
一、概述
1 介绍
Prometheus是一个开源系统监控和警报工具包,最初在SoundCloud上构建。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。它现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并澄清项目的治理结构,Prometheus于2016年加入了云原生计算基金会,成为继Kubernetes之后的第二个托管项目。
Prometheus将其指标收集并存储为时间序列数据,即指标信息与记录它的时间戳一起存储,以及称为标签的可选键值对。
2 特征
普罗米修斯的主要特点是:
- 具有由指标名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,一种灵活的查询语言,可利用这种维度
- 不依赖分布式存储;单个服务器节点是自治的
- 时序收集通过 HTTP 上的拉取模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种模式的绘图和仪表板支持
3 什么是指标
通俗地说,指标是用于测量的数字。时间序列意味着随时间记录的变化。用户想要测量的内容因应用程序而异。对于Web服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。
指标在理解应用程序以某种方式工作的原因方面起着重要作用。假设您正在运行一个 Web 应用程序,并发现该应用程序运行缓慢。您将需要一些信息来了解您的应用程序发生了什么。例如,当请求数较高时,应用程序可能会变慢。如果您有请求计数指标,则可以发现原因并增加服务器数量以处理负载。
4 组件
普罗米修斯生态系统由多个组件组成,其中许多组件是可选的:
- Prometheus server 主要组件,用于抓取和存储时间序列数据
- client libraries, 用于检测应用程序代码
- Push gateway 支持短期作业的推送
- Exporters,用于监控特殊服务,如HAProxy,StatsD,Graphite等服务。
- alertmanager 用于处理警报
- 各种支持工具
大多数Prometheus组件都是用Go编写的,这使得它们易于构建和部署为静态二进制文件。
二、 架构
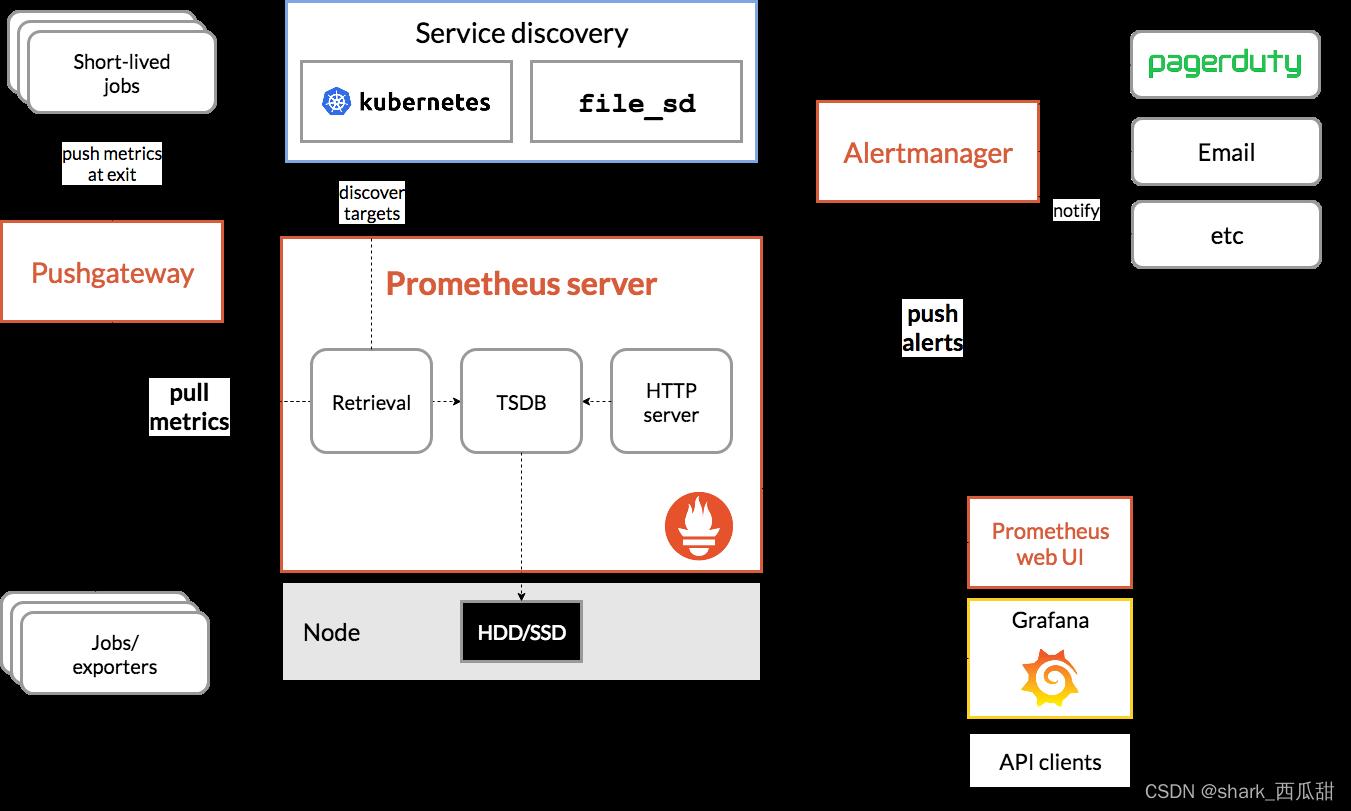
Prometheus server 直接从监控任务进程中拉取监控指标,也可以通过其他程序或脚本,将监控数据推送 Pushgateway,之后 Prometheus server 再从 Pushgateway 中拉取指标。
Prometheus server 将所有抓取的样本存储在本地,并对此数据运行规则,以聚合和记录现有数据中的新时间序列或生成警报。Grafana 或其他 API 使用者可用于可视化收集的数据。
适用场景
1 普罗米修斯非常适合记录任何纯数字时间序列。
2 既适合以机器为中心的监视,也适合监视高度动态的面向服务的体系结构。
3 在微服务世界中,它对多维数据收集和查询的支持是一个特别的优势。
4 每个Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。
不适用的场景
如果您需要100%的准确性,例如按请求计费,Prometheus不是一个好的选择,因为收集的数据可能不够详细和完整。
三 部署
1 下载
1.1 二进制方式 点击官方下载链接
1.2 docker 容器方式
镜像名称:
- prom/prometheus # 官方镜像 docer hub 地址
- bitnami/prometheus:2.36.2 # 第三方镜像
2 启动参数
--config.file=/etc/prometheus/prometheus.yml
指定配置文件
--web.enable-lifecycle
热加载配置文件
--web.read-timeout=5m
请求连接持续等待时长
--web.max-connections=512
最大并发连接数
--storage.tsdb.retention=15d
采集的监控数据保留在内存或者磁盘中的最长时间
15-30天为宜
--storage.tsdb.path="/data"
存储数据的路径
--query.timeout=2m
单次查询等待时长,超时中断本次查询
--query.max-concurrency=20
接受的最大并发查询数
3 配置文件
普罗米修斯的配置是YAML。
3.1 示例配置文件
二级制方式下载的压缩包中附带了一个名 prometheus.yml 的示例配置。
去掉注释和空行,会得到更简洁的配置内容
[root@zbx-server prometheus-2.36.2.linux-amd64]# grep -Pv "^#|^$" prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
示例配置文件中有三个配置块:
- global 全局配置
scrape_interval控制普罗米修斯抓取目标的频率。您可以为单个目标覆盖此内容。15s表示 15 秒 刷新 1 次。
evaluation_interval该选项控制普罗米修斯评估规则的频率。普罗米修斯使用规则来创建新的时间序列并生成警报。 - rule_files 加载规则文件的路径,目前没有规则文件,规则用于触发告警。
- scrape_configs 指定一组目标和参数,描述如何抓取它们。
job_name可以按照不同的环境或者其他信息对被监控的主机进行分组。
static_configs表示此配置信息下的被监控的主机是通过配置静态的配置文件获取的。
targets具体被监控的主机IP,或者可以别解析的主机名和端口,其值应该是一个列表。
"localhost:9090"普罗米修斯可以监控自身,可以使用curl http://localhost:9090/metrics来获取当前服务器的状态和性能。
3.2 配置文件详解
通用占位符定义如下:
<boolean>:一个可以取值或truefalse<duration>:与正则表达式匹配的持续时间,例如((([0-9]+)y)?(([0-9]+)w)?(([0-9]+)d)?(([0-9]+)h)?(([0-9]+)m)?(([0-9]+)s)?(([0-9]+)ms)?|0), e.g. 1d, 1h30m, 5m, 10s<filename>:当前工作目录中的有效路径<float>:浮点数<host>:由主机名或 IP 后跟可选端口号的有效字符串<int>:整数值<labelname>:与正则表达式匹配的字符串[a-zA-Z_][a-zA-Z0-9_]*<labelvalue>:一串 unicode 字符<path>:有效的网址路径<scheme>:可以取值或httphttps<secret>:作为机密的常规字符串,如密码<string>:常规字符串<size>:以字节为单位的大小,例如 512MB。需要一个单位。支持的单位:B、KB、MB、GB、TB、PB、EB。512MB<tmpl_string>:在使用前经过模板扩展的字符串
关于配置文件的更多信息,参考: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
4 部署
4.1 二进制部署
curl -O proemtheus.tar.gz https://github.com/prometheus/prometheus/releases/download/v2.36.2/prometheus-2.36.2.linux-amd64.tar.gz
tar -xf proemtheus.tar.gz -C /usr/local/
ln -s /usr/local/prometheus-2.36.2.linux-amd64/ /usr/local/prometheus
/etc/systemd/system/prometheus.service
[Unit]
Description=The nginx HTTP and reverse proxy server
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
#EnvironmentFile=-/etc/default/prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml
KillSignal=SIGQUIT
Restart=always
RestartPreventExitStatus=1 6 SIGABRT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
LimitNOFILE=1048576
LimitNPROC=1048576
[Install]
WantedBy=multi-user.target
4.2 docker-compose
目录结构
prometheus
├── compose.yml
├── config
│ └── prometheus.yml
└── data
compose.yml
version: '3.9'
services:
# 添加 普罗米修斯服务
prometheus:
# Docker Hub 镜像
image: prom/prometheus:v2.36.2
# 容器内部 hostname
hostname: prometheus
# 容器支持自启动
restart: always
# 容器与宿主机 端口映射
ports:
- '9090:9090'
# 将宿主机中的config文件夹,挂载到容器中/config文件夹
volumes:
- './config/prometheus.yml:/etc/prometheus/prometheus.yml'
- './data:/prometheus/data' # data 目录属主需要是 65534
# 指定容器中的配置文件
command:
# 支持热更新
- '--web.enable-lifecycle'
- "--web.read-timeout=5m"
- "--storage.tsdb.retention=30d"
- "--web.max-connections=512"
- "--query.timeout=2m"
- "--query.max-concurrency=20"
- "--web.console.libraries=/usr/share/prometheus/console_libraries"
- "--web.console.templates=/usr/share/prometheus/consoles"
- "--config.file=/etc/prometheus/prometheus.yml"
grafana:
environment:
GF_INSTALL_PLUGINS: "grafana-clock-panel,grafana-simple-json-datasource"
image: grafana/grafana-enterprise:8.5.5
# 容器支持自启动
restart: always
# 容器与宿主机 端口映射
ports:
- '3030:3000'
user: "104"
# 默认密码: admin/admin
chown 65534.65534 data
prometheus.yml
# my global config
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
#- "/usr/local/prometheus/prometheus.rules.yml"
- "prometheus.rules.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets:
- "localhost:9090"
- job_name: "beijing"
static_configs:
- targets:
- "10.10.10.101:9111"
labels:
group: 'beijing'
- job_name: "nanjing"
static_configs:
- labels:
group: 'k8s-630'
targets:
- '192.168.0.10:9111'
第一次启动
docker-compose up -d
热加载配置文件命令
cu rl -X POST http://localhost:9090/-/reload
四 页面功能菜单介绍
启动后,可以在浏览器中输入如下地址访问 普罗米修斯
http://普罗米修斯服务器ip:9090
Alerts 中包含的告警信息
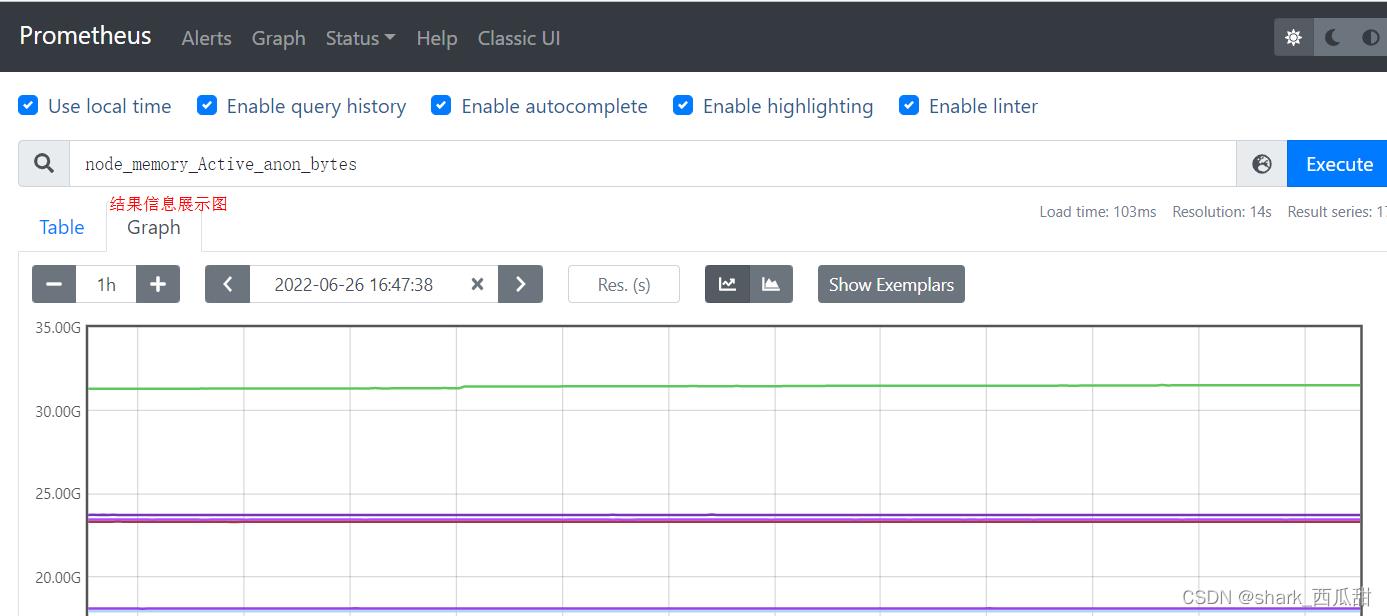
Graph 中可以根据查询表达式返回的结果,呈现出具体的图表信息
Status 各种状态
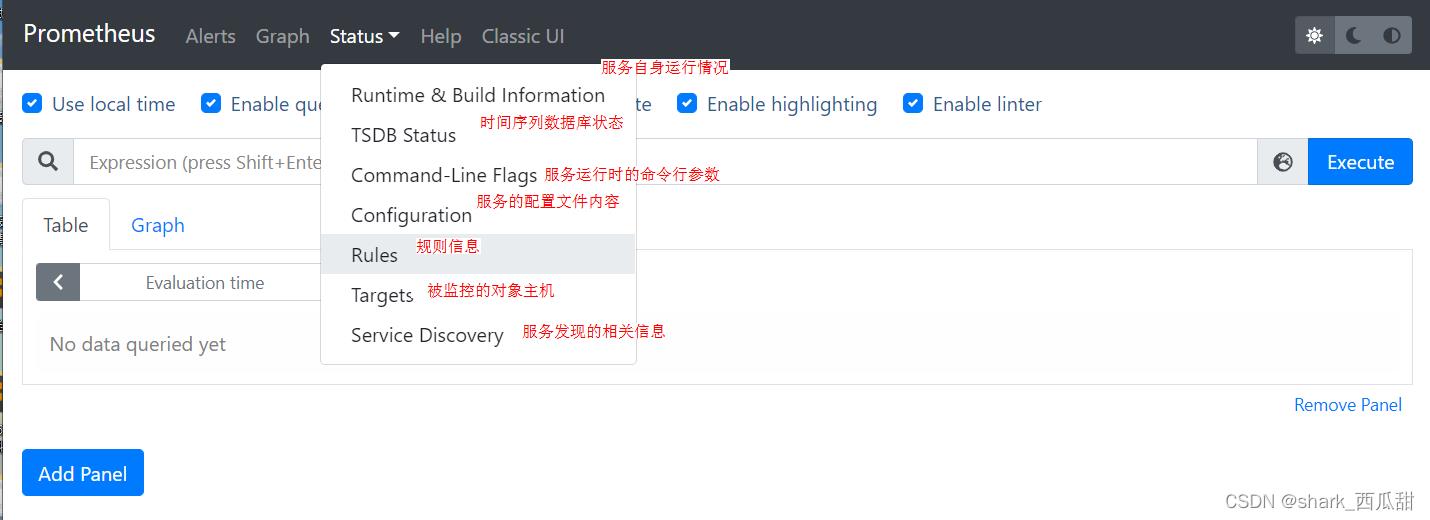
Classic UI 不同的页面 UI 风格
以上是关于Promethus概览的主要内容,如果未能解决你的问题,请参考以下文章