论文解读:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering相关的知识,希望对你有一定的参考价值。
这是关于VQA问题的第九篇系列文章。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
1,主要思想
论文使用了目标检测算法,先找出候选的区域;然后再采用注意力机制去找到重要的区域。
文章提出一种自上而下与自下而上相结合的注意力模型方法,应用于视觉场景理解和视觉问答系统的相关问题。其中基于自下而上的关注模型(一般使用Faster R-CNN)用于提取图像中的兴趣区域,获取对象特征;而基于自上而下的注意力模型用于学习特征所对应的权重(一般使用LSTM),以此实现对视觉图像的深入理解。
解释:文章中虽然没有提及在目前研究中最为广泛使用的Encode—Decode框架,但是基于自下而上的注意力模型的任务是获取图像兴趣区域提取图像特征类似于对图像进行特征编码,实现编码阶段任务;而基于自上而下的注意力模型用于学习调整特征权重,实现了图像内容的“时刻关注”,逐词生成描述,相当于解码阶段。
2,模型结构
模型部分包括三部分:自下而上的关注模型,自上而下的关注模型,vqa的模型
a.自下而上的关注模型
- 使用Faster R-CNN实现基于自下而上的注意力模型:关于Faster R-CNN的介绍可以点击连接:Faster R-CNN论文及源码解读
- Faster R-CNN模型主要部分:RPN候选框提取模块和Fast R-CNN检测模块。如下图所示,又可细分为4个部分:Conv Layer,Region Proposal Network(RPN),RoI Pooling,Classification and Regression。

- Faster R-CNN的输出是k个图像的特征向量。

b.自上而下的关注模型,图像字幕生成模型:
主要有两个LSTM,第一个是Attention LSTM,对特征特征进行加权; 第二个是Language LSTM,产生输出。

-
Attention LSTM :
第一步:lstm步骤:在每个时间步上的输入为,上一个时间步的 Language LSTM的 输出 + 图像特征的均值 + 上一时刻生成的encoding of word。
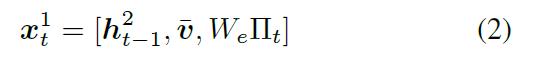

第二步:权重计算:Attention LSTM 都会输出一个output ,并且都会为 k 个image feature生成一个标准化的 attention权重 :

第三步:产生关注后的图像特征向量:

-
Language LSTM:产生文字生成
第一步:拼接x
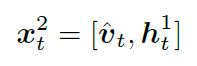
第二步:计算文字概率
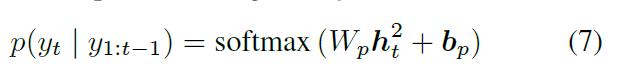
-
目标函数:有两种损失函数:
交叉熵损失函数:

优化后的损失函数:
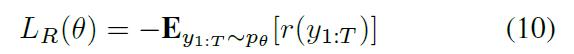
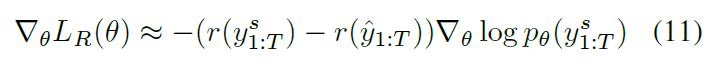
-
解释:简单的理解就是每次对特定的图像区域产生文字预测
c.VQA模型

- 对问题采用GRU编码
- 对图像特征进行关注:

其中:

- 预测输出:
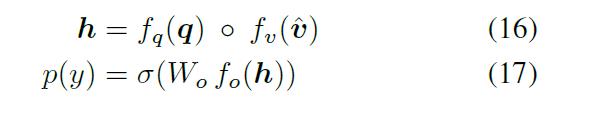
3,主要贡献:
- 结合了自上而下与自下而上相结合的注意力模型方法
- 将目标检测用于vqa或者字幕生成
以上是关于论文解读:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering的主要内容,如果未能解决你的问题,请参考以下文章