Gson全解析(下)-Gson性能分析
Posted CameloeAnthony
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Gson全解析(下)-Gson性能分析相关的知识,希望对你有一定的参考价值。
本篇文章是本系列博客的第三篇文章。将从源码角度以及Gson的深入用法讲起,一起来学习吧。
本系列文章是基于Gson官方使用指导(Gson User Guide)以及Gson解析的优秀外文(来自http://www.javacreed.com/ )做出的一个翻译和归纳。博客原链接:
Gson全解析(上)-Gson基础
Gson全解析(中)-TypeAdapter的使用
Gson全解析(下)-Gson性能分析
前言
在之前的学习中,我们在Gson全解析(上)Gson使用的基础到分别运用了JsonSerializer和JsonDeserializer进行JSON和java实体类之间的相互转化。
在Gson全解析(中)中使用了TypeAdapter中的read和write方法分别进行了反序列化和序列化。
我们曾讲到使用TypeAdapter会比使用JsonSerializer和JsonDeserializer更加的高效,原理是怎么样的呢?性能提升明显吗?
下面的文章给你答案。
Gson性能分析
以下Gson性能分析,内容整理自: GSON TYPEADAPTER EXAMPLE SERIALISE LARGE OBJECTS
采用YourKit 作为性能分析工具。
首先来看看我们提供一个大一点的数据来论证下面一些方法的优缺点。 这里提供类LargeData.java,并分为四个部分进行内存消耗的分析:
public class LargeData
private long[] numbers;
public void create(final int length)
numbers = new long[length];
for (int i = 0; i < length; i++)
numbers[i] = i;
public long[] getNumbers()
return numbers;
第1部分 JsonSerializer的直接使用
看看下面的JsonSerializer:
package com.javacreed.examples.gson.part1;
import java.lang.reflect.Type;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonPrimitive;
import com.google.gson.JsonSerializationContext;
import com.google.gson.JsonSerializer;
public class LargeDataSerialiser implements JsonSerializer<LargeData>
@Override
public JsonElement serialize(final LargeData data, final Type typeOfSrc, final JsonSerializationContext context)
final JsonArray jsonNumbers = new JsonArray();
for (final long number : data.getNumbers())
jsonNumbers.add(new JsonPrimitive(number));
final JsonObject jsonObject = new JsonObject();
jsonObject.add("numbers", jsonNumbers);
return jsonObject;
上面的代码实现了从java对象>转化>JSON数组的序列化过程。下面的代码实现了配置和初始化的过程,被写入文件。这里可以看到的是对LargeData 初始化了
10485760个元素:
package com.javacreed.examples.gson.part1;
import java.io.File;
import java.io.IOException;
import java.io.PrintStream;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
public class Main
public static void main(final String[] args) throws IOException
// Configure GSON
final GsonBuilder gsonBuilder = new GsonBuilder();
gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataSerialiser());
gsonBuilder.setPrettyPrinting();
final Gson gson = gsonBuilder.create();
final LargeData data = new LargeData();
data.create(10485760);
final String json = gson.toJson(data);
final File dir = new File("target/part1");
dir.mkdirs();
try (PrintStream out = new PrintStream(new File(dir, "output.json"), "UTF-8"))
out.println(json);
System.out.println("Done");
这个例子实现了创建java对象并且转化为JSON字符串并写入文件的整个过程。下面的图标展示了内存的消耗情况:
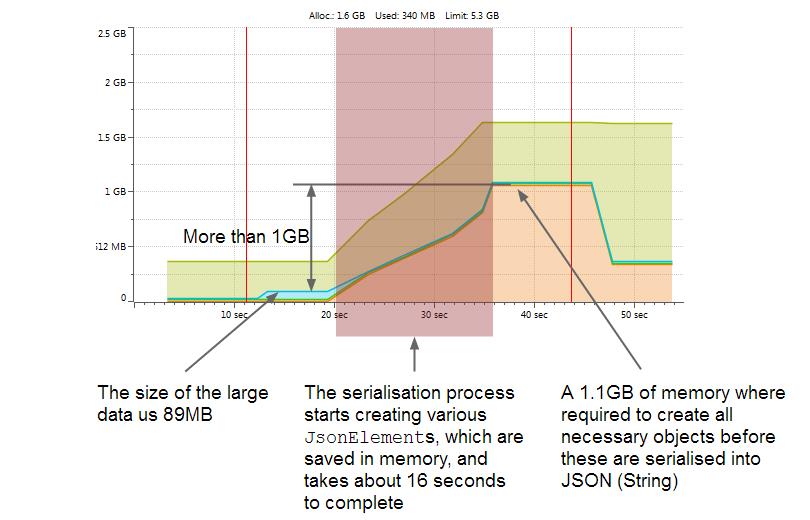
上面的的LargeData在这里会消耗89MB的内存,从java对象转化为JSON字符串的过程将会消耗大概16s的时间并且需要超过1GB的内存。也就是说,序列化1MB的数据我们需要大约11MB的工作空间。1:11的确实是一个不小的比列。下面的 图片会展示整个过程的几个阶段。
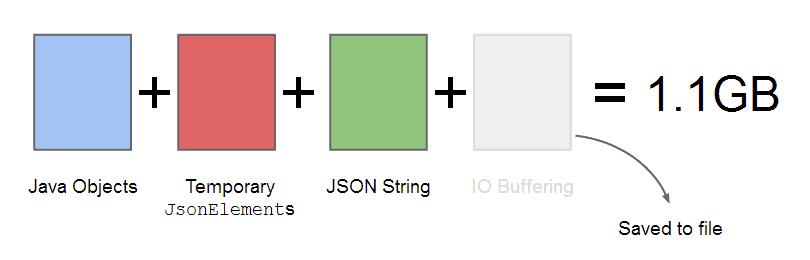
可以看到的是,这里有四个方块分别代表不同的阶段,(但是IO 缓冲区并没有在这里得到使用,所以以灰色进行标注。)整个过程从java对象(蓝色方块),然后由LargeDataSerialiser类创建的JSONElement对象(红色方块),然后这些临时的对象又被转化为JSON 字符串(绿色方块),上面的示例代码使用PrintStream将内容输出到文件中并没有使用任何缓冲区。
完成了第1部分的分析,接下来下面的分析流程是一样的:
第2 部分 TypeAdapter的直接使用
之前的系列文章中都对Gson基础的使用进行了很好的讲解,可以回顾一下。
TypeAdapter相比 于上面的方法,并没有使用JSONElement对象,而是直接将Java对象啊转化为了JSON对象。
package com.javacreed.examples.gson.part2;
import java.io.IOException;
import com.google.gson.TypeAdapter;
import com.google.gson.stream.JsonReader;
import com.google.gson.stream.JsonWriter;
public class LargeDataTypeAdapter extends TypeAdapter<LargeData>
@Override
public LargeData read(final JsonReader in) throws IOException
throw new UnsupportedOperationException("Coming soon");
@Override
public void write(final JsonWriter out, final LargeData data) throws IOException
out.beginObject();
out.name("numbers");
out.beginArray();
for (final long number : data.getNumbers())
out.value(number);
out.endArray();
out.endObject();
同样会需要配置,这里主要使用的方法是
gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataTypeAdapter());:
package com.javacreed.examples.gson.part2;
import java.io.File;
import java.io.IOException;
import java.io.PrintStream;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
public class Main
public static void main(final String[] args) throws IOException
// Configure GSON
final GsonBuilder gsonBuilder = new GsonBuilder();
gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataTypeAdapter());
gsonBuilder.setPrettyPrinting();
final Gson gson = gsonBuilder.create();
final LargeData data = new LargeData();
data.create(10485760);
final String json = gson.toJson(data);
final File dir = new File("target/part2");
dir.mkdirs();
try (PrintStream out = new PrintStream(new File(dir, "output.json"), "UTF-8"))
out.println(json);
System.out.println("Done");
上面的代码完成的是从java对象 >转化>JSON 字符串并最终写入文件的过程。看看下面的性能分析图表:

和最初的那个方法一样,这里的LargeData对象将会需要89MB的内存,从java对象转化为JSON字符串的过程需要消耗4s的时间,大概650MB的内存。也就是说,序列化1MB的数据,大概需要7.5MB的内存空间。相比于之前的第一种JsonSerializer方法,这里减少了接近一半的内存消耗。同样的,来看看这个方法的几个过程:

这里的序列化过程主要有两个阶段,相比于之前的JSONSerializer的序列化过程,这里没有了转化为JSONElement的过程,也就完成了内存消耗的减少。
第3部分 TypeAdapter的流式处理
下面的代码,我们使用上面同样的TypeAdapter,只不过我们直接在main()方法中修改Gson的用法,以流的形式进行输出。
package com.javacreed.examples.gson.part3;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
public class Main
public static void main(final String[] args) throws IOException
// Configure GSON
final GsonBuilder gsonBuilder = new GsonBuilder();
gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataTypeAdapter());
gsonBuilder.setPrettyPrinting();
final Gson gson = gsonBuilder.create();
final LargeData data = new LargeData();
data.create(10485760);
final File dir = new File("target/part3");
dir.mkdirs();
try (BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(dir,
"output.json")), "UTF-8")))
gson.toJson(data, out);
System.out.println("Done");
这个例子同样是将java对象转化为JSON字符串并且输出,也来看看下面的性能分析图表:

可以看到的是同样的最初产生的数据是89MB,序列化过程将java对象转化为JSON字符串花了大概三秒钟的时间,消耗大概160MB的内存。也就是说序列化1MB的数据我们需要大概2MB的内存空间。相比于之前的两种方法,有了很大的改进。

这个方法同样的是使用了两个阶段。不过在上面一个示例中的绿色方块部分在这里没有使用,这里直接完成了java对象到IO 缓冲区的转化并写入文件。
虽然这里并不是Gson的关系,但是我们使用Gson的方法极大的减少了内存消耗,所以说在使用开源库的时候,能够正确高效的使用API也显得尤为重要。
第4部分 JsonSerializer 的流式处理
同样的使用第一个例子中的JsonSerializer,这里的配置需要注意的是gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataSerialiser());
package com.javacreed.examples.gson.part4;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
public class Main
public static void main(final String[] args) throws IOException
// Configure GSON
final GsonBuilder gsonBuilder = new GsonBuilder();
gsonBuilder.registerTypeAdapter(LargeData.class, new LargeDataSerialiser());
gsonBuilder.setPrettyPrinting();
final Gson gson = gsonBuilder.create();
final LargeData data = new LargeData();
data.create(10485760);
final File dir = new File("target/part4");
dir.mkdirs();
try (BufferedWriter out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(dir,
"output.json")), "UTF-8")))
gson.toJson(data, out);
System.out.println("Done");
经过前面的分析,我们这里也可以这道这里主要分为三个阶段,下面提供性能分析图和JSONSerializer的阶段流程图:
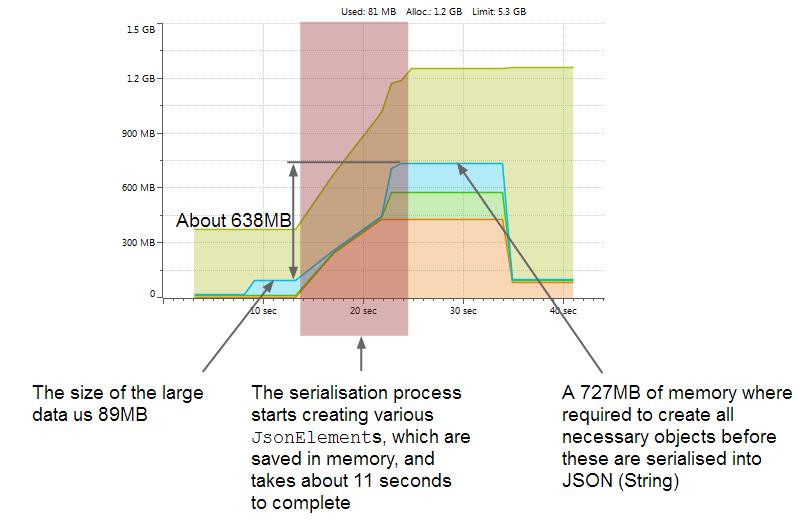
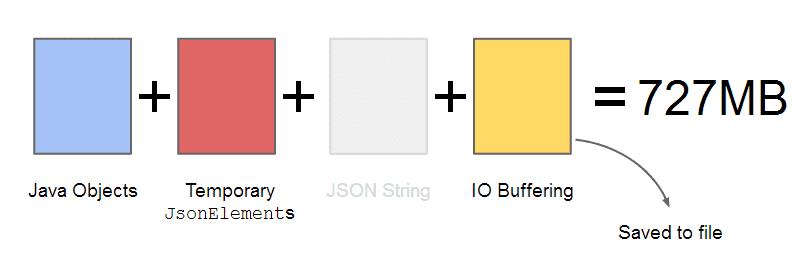
这里可以看到三个阶段完成的工作消耗了11s的时间,730MB的内存空间。也就是说1:8的比例。可以相比上面的例子,知道这里使用JSONSerializer产生了JSONElement对象消耗了很多的内存。
结论
在上面的分析过程中,我们采用了GSON的两种不同的方然完成了序列化一个大数据的过程,并且比较了不同的方法之间的差异。上面的第三种方法(TypeAdapter的流式处理)被论证为最合适的,消耗最少内存的一种方法。
Gson主要分成两部分,一个就是数据拆解,一个是数据封装。
参考链接
https://sites.google.com/site/gson/gson-user-guide
翻译原文,根据原文做出了较大改动。
1 SIMPLE GSON EXAMPLE
2 GSON DESERIALISER EXAMPLE
3 GSON ANNOTATIONS EXAMPLE
4 GSON SERIALISER EXAMPLE
5 GSON TYPEADAPTER EXAMPLE
6 GSON TYPEADAPTER EXAMPLE SERIALISE LARGE OBJECTS
另附: 你真的会用Gson吗?Gson使用指南(一)系列文章
以上是关于Gson全解析(下)-Gson性能分析的主要内容,如果未能解决你的问题,请参考以下文章