决策树-随机森林-预测5年内皮马印第安人糖尿病发作的概率-机器学习实验一
Posted Time木0101
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树-随机森林-预测5年内皮马印第安人糖尿病发作的概率-机器学习实验一相关的知识,希望对你有一定的参考价值。
文末也可直接获取实验文档以及相关数据代码
实验目的
(1)掌握决策树算法及应用;
(2)掌握集成学习方法,包括随机森林。
一、 数据说明: Pima Indians Diabetes Data Set(皮马印第安人糖尿病数据集) 根据现有的医疗信息预测5年内皮马印第安人糖尿病发作的概率。
- 文件说明
pima-indians-diabetes.csv:数据文件 - 字段说明
数据集共9个字段:
pregnants:怀孕次数
Plasma_glucose_concentration:口服葡萄糖耐量试验中2小时后的血浆葡萄糖浓度
blood_pressure:舒张压,单位:mm Hg
Triceps_skin_fold_thickness:三头肌皮褶厚度,单位:mm
serum_insulin:餐后血清胰岛素,单位:mm
BMI:体重指数(体重(公斤)/ 身高(米)^2)
Diabetes_pedigree_function:糖尿病家系作用
Age:年龄
Target:标签, 0表示不发病,1表示发病
二、实验标准
(1)实验采用10折交叉验证,使用正确率、精确率和召回率作为评价标准;
(2)采用决策树方法及随机森林分别进行实验,实验结果需明确体现;
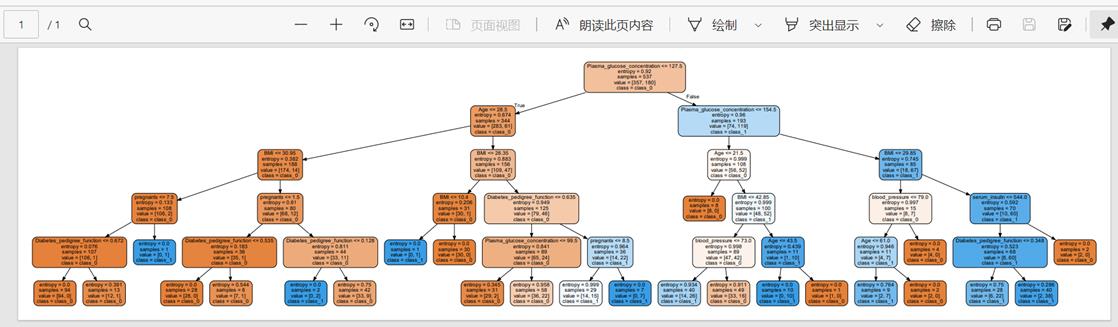
(3)实验报告中需体现决策树的结构;
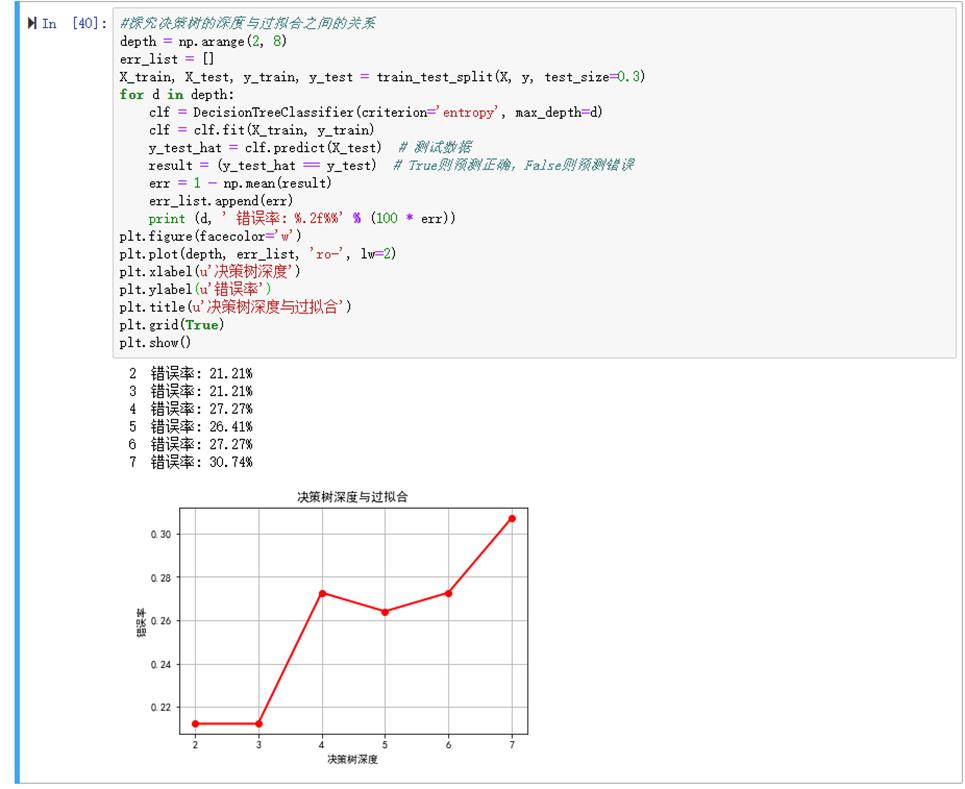
(3)在实验过程中进行参数调优,包括但不限于树的深度等,实验结果需体现相关对比。
1、 导入试验所要的包

2、 加载数据集,X为特征,y为标签。
3、 定义决策树模型,采用10折交叉验证。

4、 将树结构可视化,会输出一个树结构的pdf.
5、 输出平均正确率、平均精确率、平均召回率。1

6、 在10折交叉验证中决策树与随机森林正确率比较。

7,探究探究决策树的深度与过拟合之间的关系
7、 探究随机森林基分类器的个数与过拟合的关系

总结:在实验过程中,我基本上了解了决策树的算法和集成学习方法,包括随机森林,并用他们进行了应用。
实际感受到决策树的原理,理解了决策树的学习是采用自顶向下的递归的方法,基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处熵值为0。而随机森林,可以解决决策树泛化能力弱的缺点,会比决策树的模型表现的好。
关注公众号:Time木
回复:决策树
可获得相关代码,数据,文档
更多大学课业实验实训可关注公众号回复相关关键词
学艺不精,若有错误还望指点
以上是关于决策树-随机森林-预测5年内皮马印第安人糖尿病发作的概率-机器学习实验一的主要内容,如果未能解决你的问题,请参考以下文章