软件工程应用与实践(12)——工具类分析
Posted 叶卡捷琳堡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件工程应用与实践(12)——工具类分析相关的知识,希望对你有一定的参考价值。
2021SC@SDUSC
文章目录
一、概述
在上一篇文章中,我们主要分析了代码生成包的工具类,和一部分搜索引擎包中的工具类。经过小组成员讨论,决定继续由我分析关于搜索引擎包下的几个工具类。
本次要分析的几个工具类都与搜索引擎Lucene有关,位于下面的包下

经过这一部分的分析,我希望能更好地掌握有关Lucene搜索引擎的相关知识
除了这一部分以外,本篇博客还将分析项目中关于日志打印的工具类。

希望经过相关的学习讨论,能更好地掌握关于日志打印方面的内容
二、代码分析
2.1 IKAnalyzer5x类
本类是Lucene的IK分词器,继承了Analyzer类。而Analyzer类拥有构建分词器,分析文章中的关键词。
首先我们关注引入的包
本类中引入了下面两个类,都是由lucene搜索引擎提供的
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
接下来我们看到类的定义
该类继承了Analyzer类
public class IKAnalyzer5x extends Analyzer
接下来看构造方法
在本类中,一共有两个构造方法。
- 默认的构造方法将useSmart属性置为false,使用细粒度切分算法
- 在有参的构造方法中,可以传入true,使IK分词器使用智能切分
/**
* IK分词器Lucene Analyzer接口实现类
*
* 默认细粒度切分算法
*/
public IKAnalyzer5x()
this(false);
/**
* IK分词器Lucene Analyzer接口实现类
*
* @param useSmart 当为true时,分词器进行智能切分
*/
public IKAnalyzer5x(boolean useSmart)
super();
this.useSmart = useSmart;
接下来是这个类剩余的一些方法
获取是否使用智能切分算法,设置useSmart属性的值
private boolean useSmart;
public boolean useSmart()
return useSmart;
public void setUseSmart(boolean useSmart)
this.useSmart = useSmart;
重写createComponents,用于构造分词组件
/**
* 重写createComponents
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName)
Tokenizer _IKTokenizer = new IKTokenizer5x(this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
2.2 IKTokenizer5x类
IKTokenizer5x是一个中文分词器,与上面的类相似,都提供了相关的分词方法
首先我们看到这个类的引入
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
引入了apache相关的分词器依赖,同时又引入了Java IO流的相关类
接下来我们看到这个类的属性,由于这个类继承了Tokenizer类,具体属性的解释在注释中有。
//IK分词器实现
private IKSegmenter _IKImplement;
//词元文本属性
private final CharTermAttribute termAtt;
//词元位移属性
private final OffsetAttribute offsetAtt;
/*词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)*/
private final TypeAttribute typeAtt;
//记录最后一个词元的结束位置
private int endPosition;
接下来我们看到这个类的构造方法,在这个构造方法中,调用了addAttribute方法对属性进行初始化。而这个addAttribute方法,是apache官方在lucene搜索引擎的AttributeSource类下的一个方法
/*IK构造器*/
public IKTokenizer5x(boolean useSmart)
super();
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input, useSmart);
通过查看addAttribute方法我们发现,这个方法底层利用Java的反射机制创建相应的对象。
public final <T extends Attribute> T addAttribute(Class<T> attClass)
AttributeImpl attImpl = attributes.get(attClass);
if (attImpl == null)
if (!(attClass.isInterface() && Attribute.class.isAssignableFrom(attClass)))
throw new IllegalArgumentException(
"addAttribute() only accepts an interface that extends Attribute, but " +
attClass.getName() + " does not fulfil this contract."
);
addAttributeImpl(attImpl = this.factory.createAttributeInstance(attClass));
return attClass.cast(attImpl);
接下来我们看到下一个方法,这个方法的主要作用是用来进行中文分词,在分词的过程中设置词元的各种属性。这个方法的具体作用已经放在注释中说明了。值得一提的是,这个方法中的clearAttributes方法,与上面的方法一样,都调用了AttributeSource类的方法。接下来我们看一下这个方法做了什么
@Override
public final boolean incrementToken() throws IOException
/*清除所有的词元属性*/
clearAttributes();
Lexeme nextLexeme = _IKImplement.next();
if(nextLexeme != null)
/*将Lexeme转成Attributes*/
/*设置词元文本*/
termAtt.append(nextLexeme.getLexemeText());
/*设置词元长度*/
termAtt.setLength(nextLexeme.getLength());
/*设置词元位移*/
offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition());
/*记录分词的最后位置*/
endPosition = nextLexeme.getEndPosition();
/*记录词元分类*/
typeAtt.setType(nextLexeme.getLexemeTypeString());
/*返会true告知还有下个词元*/
return true;
/*返会false告知词元输出完毕*/
return false;
在这个方法中,利用for循环,使用state=state.next进行迭代前进,调用clear方法将对应的状态清除。
public final void clearAttributes()
for (State state = getCurrentState(); state != null; state = state.next)
state.attribute.clear();
接下来我们看到这个类的最后两个方法。这两个方法分别代表重置分词器,以及分词结束后执行的方法。在end方法中,重置了分词器的偏移。这两个方法重写了父类中的reset和end方法
@Override
public void reset() throws IOException
super.reset();
_IKImplement.reset(input);
@Override
public final void end()
//设置最终偏移
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
2.3 QueryUtil类
这个类的内容比较简单,主要是对要查询的字符串进行一些基本的操作。
首先我们看到这个类引入的包,可以看到,这个类同样与lucene搜索引擎相关,引入了如Analyzer,Query等类。
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.Query;
接下来我们看到这个类的主体部分,可以看到,这个类主要包含两个方法,一个是queryStringFilter方法,另一个是query方法。两个方法都是静态方法,方便调用。
在queryStringFilter方法中,使用字符串的replace方法将/与\\重置为空格。这个方法的主要作用是过滤非法字符。
在query方法中,首先调用了BooleanQuery的setMaxClauseCount方法,这个方法用于设置每个 BooleanQuery 允许的最大子句数。通过阅读源码可知,这个值得默认值为1024。接下来调用了queryStringFilter方法过滤非法字符。之后构建一个MultiFieldQueryParser对象,并设置默认的条件为or,最后返回一个Query对象。
public class QueryUtil
private static String queryStringFilter(String query)
return query.replace("/", " ").replace("\\\\", " ");
public static Query query(String query, Analyzer analyzer, String... fields) throws ParseException
BooleanQuery.setMaxClauseCount(32768);
//过滤非法字符
query = queryStringFilter(query);
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer);
parser.setDefaultOperator(QueryParser.Operator.OR);
return parser.parse(query);
2.4 DBLog类
上面我们提到了搜索引擎,接下来我们开始分析本项目中与日志相关的类。
日志记录在一个系统中是非常重要的,在本项目中,使用Slf4j作为日志记录的工具
在这个类中,首先我们关注引入的包,可以看到引入了Slf4j类,还引入了BlockingQueue类,LinkedBlockingQueue类作为暂时存储的队列
import com.sdu.nurse.security.api.vo.log.LogInfo;
import com.sdu.nurse.security.gate.service.LogService;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
接下来我们关注方法头,这个方法继承了Java的Thread类,说明这个方法可多线程运行,并且加上了@Slf4j注解
@Slf4j
public class DBLog extends Thread
由于这个类继承了Thread类,下面我们关注这个类重写的run方法。
在这个类中首先新建了一个LogInfo的缓冲队列,用于保存日志信息,接下来通过for-each循环读取缓冲队列的数据。在finally语句块中,如果缓冲区不为空,则将缓冲区中的内容清除。
@Override
public void run()
// 缓冲队列
List<LogInfo> bufferedLogList = new ArrayList<LogInfo>();
while (true)
try
bufferedLogList.add(logInfoQueue.take());
logInfoQueue.drainTo(bufferedLogList);
if (bufferedLogList != null && bufferedLogList.size() > 0)
// 写入日志
for(LogInfo log:bufferedLogList)
logService.saveLog(log);
catch (Exception e)
e.printStackTrace();
// 防止缓冲队列填充数据出现异常时不断刷屏
try
Thread.sleep(1000);
catch (Exception eee)
finally
if (bufferedLogList != null && bufferedLogList.size() > 0)
try
bufferedLogList.clear();
catch (Exception e)
接下来我们关注LogService对象,这个类在后面会说明,目前只需要知道,这个类是用于调用一些日志的相关服务即可,这里有get和set方法,其中set方法直接返回一个DBLog对象,便于链式调用。
public LogService getLogService()
return logService;
public DBLog setLogService(LogService logService)
if(this.logService==null)
this.logService = logService;
return this;
private LogService logService;
最后我们关注以下几个方法
- 第一个方法加上了synchronized关键字,说明这是一个线程同步的方法,通过getInstance方法放回一个本类的一个实例对象
- 第二个方法中,调用了父类(Thread类)中的构造方法,传入了字符串(代表线程名)
- 第三个方法用于写入对应的日志信息
public static synchronized DBLog getInstance()
if (dblog == null)
dblog = new DBLog();
return dblog;
private DBLog()
super("CLogOracleWriterThread");
public void offerQueue(LogInfo logInfo)
try
logInfoQueue.offer(logInfo);
catch (Exception e)
log.error("日志写入失败", e);
2.5 LogService接口和LogServiceImpl类
这两个类相比前几个类来说比较简单。分别是日志服务的接口和接口的实现类
首先我们看到接口,这个接口中只有一个方法,就是保存日志信息的方法,里面传入了一个LogInfo参数
public interface LogService
void saveLog(LogInfo info);
接下来我们关注实现类,可以看到,这个实现类上加上了@Component注解,并且自动注入了一个WebClient.Builder对象,最后log.debug函数在控制台上输出对应的日志
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.BodyInserters;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Mono;
@Component
@Slf4j
public class LogServiceImpl implements LogService
@Autowired
private WebClient.Builder webClientBuilder;
@Override
public void saveLog(LogInfo info)
Mono<Void> mono = webClientBuilder.build().post().uri("http://nurse-admin/api/log/save").body(BodyInserters.fromValue(info)).retrieve().bodyToMono(Void.class);
// 输出结果
log.debug(String.valueOf(mono.block()));
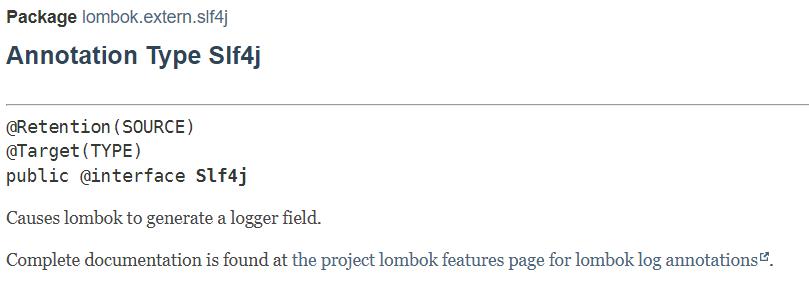
这里特别说明一下这个@Slf4j注解,这个注解是lombok提供的一个注解,加上这个注解之后,可以自动生成以下方法
比如原本的类是
@Slf4j
public class LogExample
相当于自动生成如下代码,可以省略不必要的代码
public class LogExample
private static final org.slf4j.Logger log = org.slf4j.LoggerFactory.getLogger(LogExample.class);
因此在上面的类中,我们可以使用log这个变量调用对应的方法。而表面上log变量并没有出现在类中。
这一部分内容,我们同样可以再lombok的官方文档上查询到
三、总结
在本篇博客中,我主要对老年健康管理系统中的几个工具类进行了相关的分析,总的来说,通过本次分析,我获得了不少知识,并在这个过程中,通过小组讨论与查阅资料,解决了很多问题。希望在未来的项目实训中,我也能吸收这个项目的优点,争取用在项目中。
以上是关于软件工程应用与实践(12)——工具类分析的主要内容,如果未能解决你的问题,请参考以下文章