C++实战之OpenCL矩阵相乘
Posted 哇小明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++实战之OpenCL矩阵相乘相关的知识,希望对你有一定的参考价值。
简单概念理解
在opencl中,有个索引空间NDRange的概念,NDRange是一个N维的索引空间,N可以是1,2,3。NDRange由一个长度为N的整数阵列来定义,他指定了索引空间各个维度的宽度,每个work-item的全局id和局部id,都是N维元组。
有多个work-item构成的叫做work-group,作業組的 ID 跟作業項的全局 ID差不多。一個長度為 N 的陣列定義了每個維度上作業組的數 目。作業項在所隸屬的作業組中有一個局部 ID,此 ID 中各維度的取值範圍為0到作業組在相應維 度上的大小減一。因此,作業組的 ID 加上其中一個局部 ID可以唯一確定一個作業項。有兩種途徑 來標識一個作業項:根據全局索引,或根據作業組索引加一個局部索引。
下面一张简单的图介绍下在代码中的应用:

具体实例介绍
==—–矩阵的相乘。==
串行实现代码:
int a[midle*heightA];
int b[widthB*midle];
//初始化省略
for(int l=0;l<heightA;l++)
for(int n = 0;n<widthB;n++)
for(int q=0;q<midle;q++)
result[l*widthB+n] +=a [l*midle+q]*b[q*widthB+n];
//std::cout<<"r = "<<result[l*widthB+n]<<std::endl;
简单从网上找几张图片理解下矩阵乘法的基本步骤和原理:

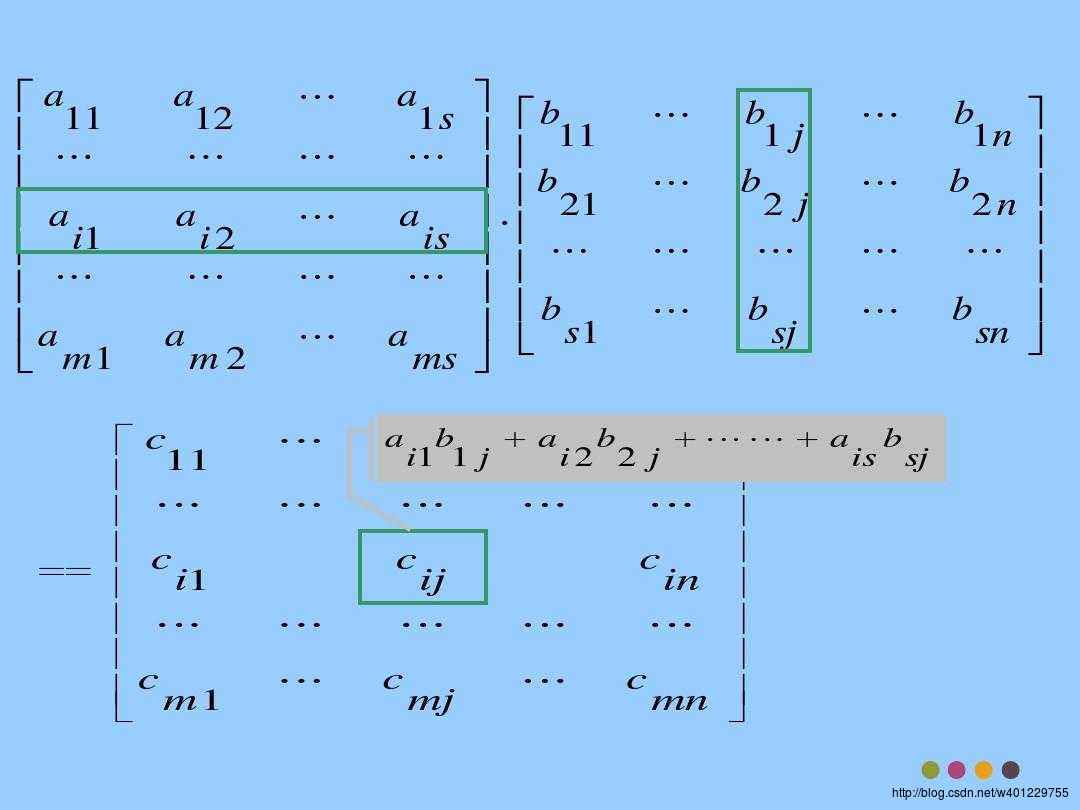
可以得知矩阵A其中的第i行和矩阵B中的第j列对应项相乘并相加的结果就是结果矩阵C[i][j]的元素了。
opencl实现矩阵相乘
a*b=c
下面是opencl的运行在gpu上内核具体实现,也就是矩阵相乘代码中在gpu中并行执行的单位代码:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
int row = get_global_id(0);
int col = get_global_id(1);
int sum = 0;
for(int i=0;i<compute_size;i++)
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
result_matrix[row*result_matrix_col+col] = sum;
这边的参数:a(M*P),b(P*N)是输入矩阵,result_matrix 是结果矩阵,result_matrix_row是结果矩阵的行(M),result_matrix_col是结果矩阵的列(N)。compute_size是a和b两个矩阵相同的行列,也就是P,是矩阵相乘中元素想加的个数。
kernel的核心代码即为上述串行代码中去掉外面两个for循环的代码,row和col分别是对应结果矩阵行和列的id,是变化的。目前这个kernel是也是这个work-item每次计算出结果矩阵中的一个元素,可以根据需要,改成每次计算出结果矩阵的一行数据,或其他块数据。我这边有做实验,计算出一个元素和一行元素在我的macbook pro上时间没有什么区别,网上看别的大神用代码说明改成计算一行的的元素,时间上减少了2/3,这部分有待验证。
如上所说,一次执行这个kernel算出结果矩阵当中的一个元素,那么需要执行M*N个这个kernel,意思就是说会有M *N个这样的(work-item)线程同时执行这个kernel,也就是并行执行。
这边为了加深对opencl 运行时的理解分析,对这个kernel做了打印测试分析。不过opencl spec上说printf是从缓冲区flush 出来的,没有顺序的,所以打印的结果仅供参考。
在cl文件中加入以下两句:
#pragma OPENCL EXTENSION cl_khr_fp64: enable
#pragma OPENCL EXTENSION cl_amd_printf : enable
就可以在kernel 中使用printf了,语法跟平时一样。
位了方便测试,把矩阵大小改成 6*6 ,10*10,20*20,对比他们的结果:
kernel中的改动:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
int row = get_global_id(0);
int col = get_global_id(1);
printf("row =%d,col=%d\\n",row,col);
int sum = 0;
for(int i=0;i<compute_size;i++)
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
printf("result_matrix[%d]=%d\\n",row*result_matrix_col+col,sum);
result_matrix[row*result_matrix_col+col] = sum;
下面是结果:
row =0,col=0
row =1,col=0
row =2,col=0
row =3,col=0
row =4,col=0
row =5,col=0
row =0,col=1
row =1,col=1
row =2,col=1
row =3,col=1
row =4,col=1
row =5,col=1
row =0,col=2
row =1,col=2
row =2,col=2
row =3,col=2
row =4,col=2
row =5,col=2
row =0,col=3
row =1,col=3
row =2,col=3
row =3,col=3
row =4,col=3
row =5,col=3
row =0,col=4
row =1,col=4
row =2,col=4
row =3,col=4
row =4,col=4
row =5,col=4
row =0,col=5
row =1,col=5
row =2,col=5
row =3,col=5
row =4,col=5
row =5,col=5
result_matrix[17]=36
result_matrix[23]=36
result_matrix[29]=36
result_matrix[35]=36
result_matrix[0]=36
result_matrix[6]=36
result_matrix[12]=36
result_matrix[18]=36
result_matrix[24]=36
result_matrix[30]=36
result_matrix[1]=36
result_matrix[7]=36
result_matrix[13]=36
result_matrix[19]=36
result_matrix[25]=36
result_matrix[31]=36
result_matrix[2]=36
result_matrix[8]=36
result_matrix[14]=36
result_matrix[20]=36
result_matrix[26]=36
result_matrix[32]=36
result_matrix[3]=36
result_matrix[9]=36
result_matrix[15]=36
result_matrix[21]=36
result_matrix[27]=36
result_matrix[33]=36
result_matrix[4]=36
result_matrix[10]=36
result_matrix[16]=36
result_matrix[22]=36
result_matrix[28]=36
result_matrix[34]=36
result_matrix[5]=36
result_matrix[11]=36
cpu t = 0.00000300
gpu t = 0.00001500
Executed program succesfully.
这个结果先是上面一句printf的全部打印冲出来,然后
再是下面打印矩阵值的printf。不急着下结论,再看一组实验结果10*10:
row =6,col=9
row =7,col=9
row =8,col=9
row =9,col=9
row =0,col=0
row =1,col=0
row =2,col=0
row =3,col=0
row =4,col=0
row =5,col=0
row =6,col=0
row =7,col=0
row =8,col=0
row =9,col=0
row =0,col=1
row =1,col=1
row =2,col=1
row =3,col=1
row =4,col=1
row =5,col=1
row =6,col=1
row =7,col=1
row =8,col=1
row =9,col=1
row =0,col=2
row =1,col=2
row =2,col=2
row =3,col=2
row =4,col=2
row =5,col=2
row =6,col=2
row =7,col=2
row =8,col=2
row =9,col=2
row =0,col=3
row =1,col=3
row =2,col=3
row =3,col=3
row =4,col=3
row =5,col=3
row =6,col=3
row =7,col=3
row =8,col=3
row =9,col=3
row =0,col=4
row =1,col=4
row =2,col=4
row =3,col=4
row =4,col=4
row =5,col=4
row =6,col=4
row =7,col=4
row =8,col=4
row =9,col=4
row =0,col=5
row =1,col=5
row =2,col=5
row =3,col=5
row =4,col=5
row =5,col=5
row =6,col=5
row =7,col=5
row =8,col=5
row =9,col=5
row =0,col=6
row =1,col=6
row =2,col=6
row =3,col=6
row =4,col=6
row =5,col=6
row =6,col=6
row =7,col=6
row =8,col=6
row =9,col=6
row =0,col=7
row =1,col=7
row =2,col=7
row =3,col=7
row =4,col=7
row =5,col=7
row =6,col=7
row =7,col=7
row =8,col=7
row =9,col=7
row =0,col=8
row =1,col=8
row =2,col=8
row =3,col=8
row =4,col=8
row =5,col=8
row =6,col=8
row =7,col=8
row =8,col=8
row =9,col=8
row =0,col=9
row =1,col=9
row =2,col=9
row =3,col=9
row =4,col=9
row =5,col=9
result_matrix[0]=60
result_matrix[10]=60
result_matrix[20]=60
result_matrix[30]=60
result_matrix[40]=60
result_matrix[50]=60
result_matrix[60]=60
result_matrix[70]=60
result_matrix[80]=60
result_matrix[90]=60
result_matrix[1]=60
result_matrix[11]=60
result_matrix[21]=60
result_matrix[31]=60
result_matrix[41]=60
result_matrix[51]=60
result_matrix[61]=60
result_matrix[71]=60
result_matrix[81]=60
result_matrix[91]=60
result_matrix[2]=60
result_matrix[12]=60
result_matrix[22]=60
result_matrix[32]=60
result_matrix[42]=60
result_matrix[52]=60
result_matrix[62]=60
result_matrix[72]=60
result_matrix[82]=60
result_matrix[92]=60
result_matrix[3]=60
result_matrix[13]=60
result_matrix[69]=60
result_matrix[79]=60
result_matrix[89]=60
result_matrix[99]=60
result_matrix[46]=60
result_matrix[56]=60
result_matrix[66]=60
result_matrix[76]=60
result_matrix[86]=60
result_matrix[96]=60
result_matrix[7]=60
result_matrix[17]=60
result_matrix[27]=60
result_matrix[37]=60
result_matrix[47]=60
result_matrix[57]=60
result_matrix[67]=60
result_matrix[77]=60
result_matrix[87]=60
result_matrix[97]=60
result_matrix[8]=60
result_matrix[18]=60
result_matrix[28]=60
result_matrix[38]=60
result_matrix[48]=60
result_matrix[58]=60
result_matrix[68]=60
result_matrix[78]=60
result_matrix[88]=60
result_matrix[98]=60
result_matrix[9]=60
result_matrix[19]=60
result_matrix[29]=60
result_matrix[39]=60
result_matrix[49]=60
result_matrix[59]=60
result_matrix[23]=60
result_matrix[33]=60
result_matrix[43]=60
result_matrix[53]=60
result_matrix[63]=60
result_matrix[73]=60
result_matrix[83]=60
result_matrix[93]=60
result_matrix[4]=60
result_matrix[14]=60
result_matrix[24]=60
result_matrix[34]=60
result_matrix[44]=60
result_matrix[54]=60
result_matrix[64]=60
result_matrix[74]=60
result_matrix[84]=60
result_matrix[94]=60
result_matrix[5]=60
result_matrix[15]=60
result_matrix[25]=60
result_matrix[35]=60
result_matrix[45]=60
result_matrix[55]=60
result_matrix[65]=60
result_matrix[75]=60
result_matrix[85]=60
result_matrix[95]=60
result_matrix[6]=60
result_matrix[16]=60
result_matrix[26]=60
result_matrix[36]=60
cpu t = 0.00000600
gpu t = 0.00001600
Executed program succesfully.
看了上面就会发现,也是乱序的,不过仔细一看,其实还是有一点规律的,这边只是让自己对opencl runtime有个初步的认识。后面在对矩阵相乘的优化中,继续学习work-group和work-item等抽象概念。
下面是在cpu上跑的代码:
//
// main.cpp
// OpenCL
//
// Created by wmy on 2017/9/19.
// Copyright © 2017年 wmy. All rights reserved.
//
#include <OpenCL/OpenCL.h>
#include <iostream>
#include <fstream>
#include <sstream>
#include <unistd.h>
#include <sys/time.h>
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include <mach/mach_time.h>
#include <boost/algorithm/string.hpp>
using namespace std;
//const int ARRAY_SIZE = 100000;
//4*3---3*5
const int midle = 640;
const int heightA = 480;
const int widthB = 640;
//const int heightB = 3;
//一、 选择OpenCL平台并创建一个上下文
cl_context CreateContext()
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
//选择可用的平台中的第一个
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
//创建一个OpenCL上下文环境
cl_context_properties contextProperties[] =
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformId,
0
;
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_GPU,
NULL, NULL, &errNum);
return context;
//二、 创建设备并创建命令队列
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device)
cl_int errNum;
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
// 获取设备缓冲区大小
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (deviceBufferSize <= 0)
std::cerr << "No devices available.";
return NULL;
// 为设备分配缓存空间
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
//选取可用设备中的第一个
commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
*device = devices[0];
delete[] devices;
return commandQueue;
// 三、创建和构建程序对象
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open())
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
return program;
//创建和构建程序对象
bool CreateMemObjects(cl_context context, cl_mem memObjects[3],
int *a, int *b)
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(int) * midle*heightA, a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(int) * widthB*midle, b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE,
sizeof(int) * widthB*heightA, NULL, NULL);
return true;
// 释放OpenCL资源
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem memObjects[3])
for (int i = 0; i < 3; i++)
if (memObjects[i] != 0)
clReleaseMemObject(memObjects[i]);
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (context != 0)
clReleaseContext(context);
int main(int argc, char** argv)
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = 0, 0, 0 ;
cl_int errNum;
// uint64_t t1,t2,t3;
clock_t t1,t2,t3;
const char* filename = "/Users/wangmingyong/Projects/OpenCL/OpenCL/HelloWorld.cl";
// 一、选择OpenCL平台并创建一个上下文
context = CreateContext();
// 二、 创建设备并创建命令队列
commandQueue = CreateCommandQueue(context, &device);
//创建和构建程序对象
program = CreateProgram(context, device, filename);//"HelloWorld.cl");
// 四、 创建OpenCL内核并分配内存空间
kernel = clCreateKernel(program, "hello_kernel", NULL);
//创建要处理的数据
int result[widthB*heightA]0;
int a[midle*heightA];
int b[widthB*midle];
for (int i = 0; i < heightA; i++)
for(int j = 0;j < midle;j++)
a[i*midle+j]=2;//10.0f * ((int) rand() / (int) RAND_MAX);
for (int k = 0; k < midle; k++)
for(int m = 0;m < widthB;m++)
b[k*widthB+m]=3;//10.0f * ((int) rand() / (int) RAND_MAX);
t1 = clock(); //mach_absolute_time();
printf("t1 = %.8f\\n",(double)t1);
//cpu串行处理代码
for(int l=0;l<heightA;l++)
for(int n = 0;n<widthB;n++)
for(int q=0;q<midle;q++)
result[l*widthB+n] +=a [l*midle+q]*b[q*widthB+n];
//std::cout<<"r = "<<result[l*widthB+n]<<std::endl;
t2 = clock(); //mach_absolute_time();
printf("t2 = %.8f\\n",(double)t2);
//创建内存对象
if (!CreateMemObjects(context, memObjects, a, b))
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
// 五、 设置内核数据并执行内核
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
errNum |= clSetKernelArg(kernel, 3, sizeof(int), &heightA);
errNum |= clSetKernelArg(kernel, 4, sizeof(int), &widthB);
errNum |= clSetKernelArg(kernel, 5, sizeof(int), &midle);
size_t globalWorkSize[2];
globalWorkSize[0]= heightA;
globalWorkSize[1]=widthB;
// size_t localWorkSize[2] = 1,1 ;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
globalWorkSize, NULL,
0, NULL, NULL);
// 六、 读取执行结果并释放OpenCL资源
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE,
0, widthB*heightA * sizeof(int), result,
0, NULL, NULL);
// for(int p=0;p<20;p++)
// cout<<"new ="<<result[p];
//
t3 = clock(); //mach_absolute_time();
printf("cpu t = %.8f\\n",(float)(t2-t1)/CLOCKS_PER_SEC);
printf("gpu t = %.8f \\n",(double)(t3-t2)/CLOCKS_PER_SEC);
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
getchar();
Cleanup(context, commandQueue, program, kernel, memObjects);
return 0;
下面是具体运行效果:
耗时:
| 维度 | cpu | gpu |
|---|---|---|
| 10*10 | 0.00001900 | 0.00064400 |
| 100*100 | 0.00279000 | 0.00073800 |
| 500*500 | 0.38360301 | 0.00235700 |
可以看出随着维度的增加cpu的虐势就体现出来了
以上是关于C++实战之OpenCL矩阵相乘的主要内容,如果未能解决你的问题,请参考以下文章