论文解读:Feature Enhancement in Attention for Visual Question Answering
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:Feature Enhancement in Attention for Visual Question Answering相关的知识,希望对你有一定的参考价值。
这是关于VQA问题的第十篇系列文章。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:Feature Enhancement in Attention for Visual Question Answering
1,主要思想:
这是2018年顶会(International Joint Conference on Artificial Intelligence )的一篇关于vqa的论文。本文提出vqa问题中视觉和文本表示空间的不同对结果有影响。为了可以更好的应用注意力机制,作者提出在特征上下功夫,即是,如何更有效的提取视觉信息。主要特征加强办法有:(注意,本文有两个容易混淆的概念:区域表示和区域语义表示,区域表示就是我们通常理解的视觉特征,区域语义表示是本文提出给区域的文本表示)
- 利用区域语义表示计算attention权重:区域语义表示和问题更加相关,
- 利用层次表示丰富区域表示:层次提取视觉特征
- 改善区域语义表示:区域语义表示还可以附有更多的信息,可以加入概率信息,而不是单纯的语义
2,模型结构
a.特征增强模型的概述

-
feature encoding part:采用GRU对文本进行编码,采用Faster R-CNN(bottom-up attention model)提取视觉特征k个。
-
attention part:权重的计算过程,R部分是后面再确定的。


-
Feature Fusion Part:特征融合

-
预测输出:

b.第一种视觉特征提取办法:V/V: Conventional Attention(图a)
也就是用图像计算与问题的相关性权重,并对图像进行加权求和。

c.第二种视觉特征提取办法:T/V: Region Semantic Representation(图b)
T:图像语义空间表示,即是,对图像区域进行预测类别标签,用对应的词向量作为图像区域语义表示,然后用这个和问题表示计算权重。后面步骤一样
d. 第三种视觉特征提取办法:TV/V and TV/TV: Representation Enrichment using Multi-Level Features
语义表达有时候过于抽象,为了能够获取更加具体的信息,把语义信息和图像信息合并起来与问题表示计算权重。同理,在特征融合的时候也可以同时考虑语义表示和图像特征。(多级别的图像特征使用)
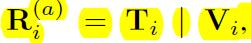

e.第四种视觉特征提取办法:rTV/V and rTV/rTV: Semantic Representation Refinement
有时候我们在类别标签预测的时候,并不是很准确,所以预测时,前面topk的预测信息都应该有用,所以可以在语义表示的时候加入概率特征。

3,主要贡献
- 提出了很多特征加强的技术,这是个比较有特色的创新
- 加入概率信息提取丰富的语义表示
以上是关于论文解读:Feature Enhancement in Attention for Visual Question Answering的主要内容,如果未能解决你的问题,请参考以下文章