(DDIA)SQL与NoSQL数据模型简介
Posted 雨钓Moowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(DDIA)SQL与NoSQL数据模型简介相关的知识,希望对你有一定的参考价值。
翻译《Designing Data-Intensive Applications》
作者:Martin Kleppmann
译者:雨钓(有增改)
一、SQL与NOSQL起源与优劣对比
1.1、SQL
今天最著名的数据结构可能就是SQL了,一种基于Edgar Codd在1970年提出的关系模型: 数据被组织成关系(SQL中的表),其中每个关系是一个无序的元组集合(SQL中的行), 关系模型是一个理论上的建议,许多人当时怀疑它是否能有效地实现。 然而,到20世纪80年代中期,关系数据库管理系统(RDBMSes)和SQL已经成为大多数人的首选工具,他们需要存储和查询带有某种regular结构的数据。 关系数据库的主导地位持续了大约25-30年——这在计算历史上是绝无仅有的;
关系数据库的根源在于业务数据处理,主要是执行在上世纪六、七十年代的一种大型计算机上。它所针对的用例从今天的角度来看是很平常的,例如:典型的交易处理(销售或银行中转业务,航空公司预订,仓库库存)和批处理( 用户的发票、工资、报告)。哪些当时与关系型数据库共存的其他数据库,由于其本身设计的问题,使得应用程序开发人员需要对数据库中数据的内部结构进行大量的思考和优化。而与之相反,关系模型的目标是将实现细节隐藏在一个更干净的接口后面。
多年来,针对于数据存储和查询的方法有很多。 20世纪70年代和80年代初,网络模型和层次模型是当时主要的选择。 但是伴随着关系模式的出现和快速发展,关系模型主键占据主导地位。 在上世纪80年代末和90年代初,Object数据库再次出现, XML数据库出现于本世纪初,但只出现了小众的采用。 关系模型的每个竞争对手在这段时间内都进行了大量的宣传和炒作但是仍然未能生存下来。
随着计算机变得更加强大和网络化,它们开始被用于越来越多样化的场景。值得注意的是,关系数据库在其原始的业务数据处理范围之外,非常好地推广到针对WEB的应用上。 你在web上看到的许多东西仍然是由关系数据库驱动的,比如在线发布、讨论、社交网络、电子商务、游戏、软件服务等等。
1.2、The Birth of No SQL
2010年 出现的NOSQL是推翻关系模型统治地位的一次最新尝试。“No SQL”这个名字是不准确的,因为它实际上并不是指任何特定的技术——它最初只是一个简单的Twitter在2009年提出的一个标签,主要关于分布式,非关系数据库,只后很快就传遍了业界。现在,许多有趣的数据库系统都与No SQL相关,并且它被重新定义为***NOT Only SQL***。
在NO SQL数据库的情况下,有几个驱动因素,包括:
-
比关系型数据库更好的扩展性,包括更大的数据集以及吞吐量。
-
更好的开源特性而不是商业化的。
-
拥有关系模型所不支持的特定查询操作
-
抛弃了关系模型中对schema的限制,支持更动态和更具代表性的数据模型
不同的应用程序有不同的需求,对于一个用例场景来说,最好的技术选择可能与另一个用例的最佳选择是不同。因此,在可预见的将来,关系数据库将继续与广泛的非关系数据存储共存,这一概念有时被称为***polyglot persistence***
二、The Object-Relational Mismatch
当今大多数应用程序开发都是在面向对象的编程语言中完成的,这导致了开发人员对SQL数据模型存在很多意见,因为如果数据存储在关系表中,那么在应用代码中的对象(面向对象的语言,如JAVA)和关系型模型中的表之间需要一个笨拙的转换层。 模型之间的讨论有时被称为***impedance mismatch***( 从电子产品中借用的术语。每个电路的输入和输出都有一定的阻抗。当你将一个电路的输出连接到另一个电路的输入时,如果两个电路的输出和输入阻抗匹配,连接上的power transfer就会最大化。阻抗不匹配会导致信号反射和其他问题)
因此则常见的面向对象的开发中,如JAVA Web项目中通常会使用如Active Record和Hibernate等***对象-关系映射(ORM)框架***,以减少这个翻译层所需的样板代码量。但它们并不能完全隐藏这两个模型之间的差异。

例如,上图说明了在关系模式中如何表示一份简历(概要文件中的链接)。整个文件可以通过一个唯一一的标识符user_id来标识, 像first_name和last_name这样的字段恰好显示为每一个用户,因此它们可以被建模为users表上的列。 然而,大多数人在他们的职业(职位)中有不止一份工作,而且人们可能会有很多的教育时期和任何数量的联系信息,从用户和项目之间具有一对多的关系,可以用不同的方式表示:
-
1、在传统的SQL模型(在SQL:1999之前)中,最常见的标准化 的 表现是将位置、教育和联系信息放在不同的表中,并通过外键引用放在users表中,如图所示。
-
2、后来版本的SQL标准增加了对结构化数据类型和xml数据的支持;允许将多值数据存储在单个行中,并支持在这些文档中查询和索引。这些特性在Oracle、IBM DB2、MS SQL Server和Post‐gre SQL(6、7)进行了不同程度的实现。JSON数据类型也被几个数据库所支持,包括IBM DB2、SQL和Postgre SQL。
-
3、第三种选择是将工作、教育和联系信息作为JSON或XML Document进行编码,将其存储在数据库的文本列上,并让应用程序对其结构和内容进行优先处理。在这个设置中,通常无法使用数据库查询在编码列内的值。
对于像上面提到的类似简历这样的数据结构,它通常是一个自包含的文档,JSON可能非常合适:参见示例2-1。JSON相较于XML而言要简单得多,因此也更具吸引力。面向文档的数据库如Mongo DB、Rethink DB、Couch DB和Espresso都支持这个数据模型。
Example 2-1. Representing a Linked In profile as a JSON document
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
"job_title": "Co-chair","organization": "Bill & Melinda Gates Foundation",
"job_title": "Co-founder, Chairman", "organization": "Microsoft"
],
"education": [
"school_name": "Harvard University", "start": 1973, "end": 1975,
"school_name": "Lakeside School, Seattle", "start": null, "end": null
],
"contact_info":
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
三、JSON
一些开发人员认为,JSON模型减少了应用程序代码和存储层之间的阻抗不匹配(impedance mismatch)。但是,接下来我们将看到,JSON作为一种数据编码格式也存在一些问题。同时缺乏schema常常被认为是一种优势。
JSON表示比图2-1中多表模式具有更好的局部性。 如果您想在关系数据库示例中获取一个简历文件,您需要执行多个查询(通过user_id查询每个表),或者在users表及其附属表之间执行一个混乱的多路JOIN。在JSON表中,所有相关信息都在一个地方,一个查询就足够了。
用户位置、教育历史和联系信息的一对多关系可以表示成数据中的树结构,而json表示的树结构显式如图2-2所示:
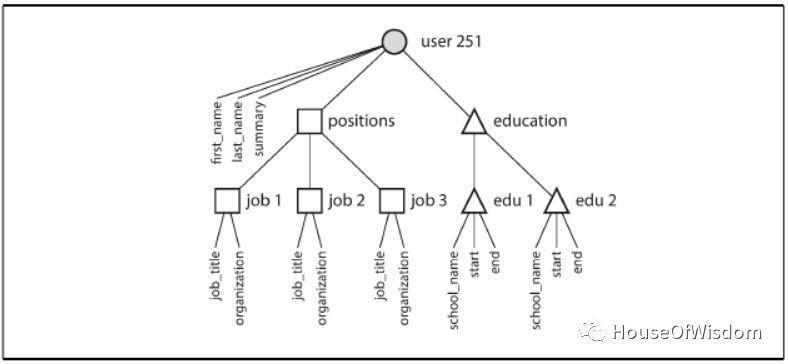
四、Many-to-One and Many-to-Many Relationships
在前一节中,以图2-1为例,区域id和行业id被指定为ID,而不是纯文本字符串“Greater Seattle Area”和“Philanthropy”。思考下这是为什么?
如果用户界面有需要输入的诸如“区域”或“行业”等文本字段,那么没有将它们(行业和区域)存储为纯文本字符串是有意义的。 同时,将地理位置信息抽取出来组成一张表也是有好处的:
- 1、有助于保持一致的风格和拼写
- 2、避免歧义 (e.g., if there are several cities with the same name)
- 3、易于更新-the name is stored in only one place, so it is easy to update across the board if it ever needs to be changed (e.g., change of a city name due topolitical events)
- 4、本地化支持—when the site is translated into other languages, the stand‐ardized lists can be localized, so the region and industry can be displayed in theviewer’s language
- 5、方便更好的查询—e.g., a search for philanthropists in the state of Washington can match this profile, because the list of regions can encode the fact that Seattle is in Washington (which is not apparent from the string “Greater Seattle Area”)
是否存储ID或文本字符串主要考虑的是重复问题。 当您使用ID时,对人类有意义的信息(例如“Philanthropy慈善”)只存储在一个地方,所有引用的信息都使用一个ID(在数据库中只有这个ID)。 当你直接存储文本时,你将在每个使用它的记录中复制具有人类意义的文本信息,存储的占用会更高。 使用ID的优点是,因为它对人类没有意义,所以即使它标识的信息发生了变化,它也不需要改变。而任何对人类有意义的事情都可能在未来的某个时候发生变化——如果这些信息被复制,所有多余的副本都需要更新。 这就会导致写过多的开销,并且会出现不一致的风险(有些信息会被更新,而有些则没有更新)。消除这种重复是数据库标准化的关键思想。
不幸的是对数据进行规范化需要多对一的关系(many-to-one )例如,许多人生活在同一个区域,许多人在同一个行业工作等,此时人与区域,人与行业都是多对一关系,这种多对一关系并不适合文档数据模型(document model)。而在关系型数据库中通常通过ID引用其他表中的行,因此在关系型数据库中JOIN很容易。但是在document model中join操作对于一对多(one-to-many)的树形结构并不是必须的,并且对Join的支持非常差。
如果数据库本身不支持JOIN,那么就需要在应用端代码中通过多次查询数据库模拟JOIN操作(在上面提到的这种情况下,区域和行业列表可能很小,你可以把他们保存在内存中,但是这样做相当于把JOIN的工作从数据库中转移到应用端代码中了)
此外,即使应用程序的初始版本很适合无连接的document model,但是随着应用程序功能的不断添加,数据会倾向于变得更加具有关联性。
五、Relational Versus Document Databases Today
当比较关系型数据与Document数据库时有很多需要考虑的地方,包括他们的容错性,并发处理能力。这里我们仅仅对数据模型进行对比。
Document模型的最大优势是***schema灵活***,同时对于一些应用而言,他与一些应用代码中所使用的数据结构很相似。而关系型数据库的优势是提供JOIN和更好的对多对一关系支持,以及多对多的支持。
六、Which data model leads to simpler application code?
如果你的应用的数据结构类似文档(例如一个一对多的树型结构,且通常一次加载整个树)那么Document将非常合适;而关系技术将一个类似文档的结构撕裂成几个碎片化的表,会导致复杂的schema和复杂的应用程序代码。
文档数据库也有限制,例如你不能直接引用文档中未定义的项目,例如你通常需要这样描述:“用户251的职位列表中第二个职位”(很像层级模型中的访问路径),然而只要文档没有太深的嵌套,这通常不是问题。
而文档数据库对JOIN的支持不足,可能是问题,也可能不是问题,这主要取决于应用。例如利用文档数据库记录某个时间点发生的事件并分析的应用中,可能不需要多对多关系。然而如果你的应用中确实需要多对多关系,那么Document数据库就不那么吸引人了。它可能导致需要使用非常规的手段来实现JOIN操作,此外应用程序也需要添加额外的代码来保证数据一致性:通过向数据库发送多个请求可以在应用端实现JOIN操作,但是这样会将复杂性转移到应用程序中,同时,这样做通常比在数据库中执行的JOIN要慢。因此在这种情况下,会导致应用程序更加复杂以及更糟糕的性能。
一般来说,无法肯定哪个数据库一定会导致应用程序更加复杂,它主要取决于数据之间的关系类型,对于高度互联的数据,文档数据库是笨拙的,而关系型数据库是有效的,图数据库是更加自然的。
七、Schema flexibility in the document model
大多数的document数据库以及支持JSON的关系型数据库不会对document中的数据进行任何强制的schema,在关系型数据库中支持XML时通常带有可选的schema验证。当没有schema时,任意的key和value都可以插入到document中,同时在读取数据时客户端对数据也没有任何保证。
document数据库通常也被称为***schemaless***,这样称呼有一些误导的意思,因为在代码读取数据时通常采用某种结构来解析数据,例如是一个隐式的schema,只是没有被数据库强制执行。一个更准确的词应该是:schema-on-read(数据的结构是隐式的,只有当读取数据时才使用该结构去解析)***。与之相应的 是***schema-on-write(通常在关系型数据库中被采用,schema是显示的,数据库会确保所有的数据都符合schema)
***Schema-on-read***类似于编程语言中的动态类型检查,相反,***Schema-on-write***就是静态类型检查。正如开发人员对于静态类型检查和动态类型检查有很大争论一样 ,数据库中schema的实现也是一个有很大争议的额话题,无关没有对错。
当应用程序想要更改他的数据格式时,这两种模式的差异将会非常明显;假如,当前你正在将每个用户的全名存储在一个字段中,然而不久之后你希望姓和名分开存储。在document数据库中,你需要使用一个新的document用来写first name,同时在应用程序中当读取老的数据时需要进行如下处理:
if (user && user.name && !user.first_name)
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
而另一方面,在静态类型schema的数据库中,你需要进行迁移:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- Postgre SQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- My SQL
schema修改的代价是需要停机时间,这个代价是非常昂贵且完全不值得的。大多数的关系型数据在执行 ALTER TABLE语句的耗时约在几秒内,mysql是一个明显的例外, 它可以在ALTER table上复制整个表,这意味着在修改一个大型表时,可能需要几分钟甚至几个小时的停机时间——尽管有各种各样的工具在这个限制下工作。
在大表上运行UPDATE语句可能会在任何数据库上都很慢,因为每一行都需要重写。通常这是不可接受的,当然你也可以在应用程序中进行处理,将first_name设置为NULL,并在读取时填充它,就像使用文档数据库一样。但是在schema-on-read模式下是危险的,如果一个集合中的所有元素因为一些原因(例如数据是多样的)导致结构并不是一致,例如:有许多不同类型的对象,将每种类型的对象放到各自的表中是不切实际的,数据的结构是由外部系统决定的,而这些系统是您所控制的,并且随时可能发生变化。
在这种情况下,一个schema可能会过大于功,而schemaless的记录则是一个更自然的数据模型。 但是,如果所有的记录都被期望具有相同的结构,那么schema是用来记录和执行结构的有用机制。我们将在之后详细讨论模式和模式演化。
相关参考文档References
[1] Edgar F. Codd: “A Relational Model of Data for Large Shared Data Banks,” Com‐munications of the ACM, volume 13, number 6, pages 377–387, June 1970. doi:10.1145/362384.362685
[2] Michael Stonebraker and Joseph M. Hellerstein: “What Goes Around ComesAround,” in Readings in Database Systems, 4th edition, MIT Press, pages 2–41, 2005.ISBN: 978-0-262-69314-1
[3] Pramod J. Sadalage and Martin Fowler: No SQL Distilled. Addison-Wesley, August2012. ISBN: 978-0-321-82662-6
[4] Eric Evans: “No SQL: What’s in a Name?,” blog.sym-link.com, October 30, 2009.
[5] James Phillips: “Surprises in Our No SQL Adoption Survey,” blog.couchbase.com,February 8, 2012.
[6] Michael Wagner: SQL/XML:2006 – Evaluierung der Standardkonformität ausge‐wählter Datenbanksysteme. Diplomica Verlag, Hamburg, 2010. ISBN:978-3-836-64609-3
[7] “XML Data in SQL Server,” SQL Server 2012 documentation, technet.micro‐soft.com, 2013.
[8] “Postgre SQL 9.3.1 Documentation,” The Postgre SQL Global DevelopmentGroup, 2013.
[9] “The Mongo DB 2.4 Manual,” Mongo DB, Inc., 2013.
[10] “Rethink DB 1.11 Documentation,” rethinkdb.com, 2013.
[11] “Apache Couch DB 1.6 Documentation,” docs.couchdb.org, 2014.
[12] Lin Qiao, Kapil Surlaker, Shirshanka Das, et al.: “On Brewing Fresh Espresso:Linked In’s Distributed Data Serving Platform,” at ACM International Conference onManagement of Data (SIGMOD), June 2013.
[13] Rick Long, Mark Harrington, Robert Hain, and Geoff Nicholls: IMS Primer.IBM Redbook SG24-5352-00, IBM International Technical Support Organization,January 2000.
[14] Stephen D. Bartlett: “IBM’s IMS—Myths, Realities, and Opportunities,” TheClipper Group Navigator, TCG2013015LI, July 2013.
[15] Sarah Mei: “Why You Should Never Use Mongo DB,” sarahmei.com, November11, 2013.
译者注:
17年初读此书,惊为神作,年末心(Kai)血(shi)来(zuo)潮(si)利用空闲时间翻译此书,自(chun)娱(shu)自(zhuang)乐(bi)!历时8个月完成十之七八后,终告失败。之后会整理归纳后,希望作为一个系列,在此记录,聊以自慰。。。
需要提的是,18年9月份国内有三位大神已经成功出版了该书的中文版,有兴趣可以去读下。
未完待续。。。。。。。。。。。。
文章来源《Designing Data-Intensive Applications》翻译有删改

以上是关于(DDIA)SQL与NoSQL数据模型简介的主要内容,如果未能解决你的问题,请参考以下文章