2021 AAAI best Paper - Informer-2020 学习记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021 AAAI best Paper - Informer-2020 学习记录相关的知识,希望对你有一定的参考价值。
这篇文章是来自AAAI的best paper,目前已经开源在github,这里博主记录一下自己的学习过程。
项目使用pytorch开发,按照readme要求的环境即可,环境没有问题的话基本不需要改动即可完美调试,博主开始时pytorch版本太低,所以导致了很多问题,当然这个调试修改的过程也并非是毫无用处,它可以让我们对项目的理解更加深刻。此外这个项目也有tensorflow版本,大家可以看博主的这篇博文:
Informer学习记录之Informer-Tensorflow版本
运行环境
Informer是一个处理时间序列预测的项目,因此不同于那些目标检测等涉及图片的深度学习实验,其对内存,显卡等环境的要求相对较低。
作者的环境
Python 3.6
matplotlib == 3.1.1
numpy == 1.19.4
pandas == 0.25.1
scikit_learn == 0.21.3
torch == 1.8.0
博主的环境
windows 10
NVIDIA GeForce GTX 960M
python 3.6 cuda10.0 cudnn7.4
pytorch==1.1.0
numpy ==1.16.0
pandas == 1.1.5
matplotlib == 3.3.4
scikit_learn == 0.24.2
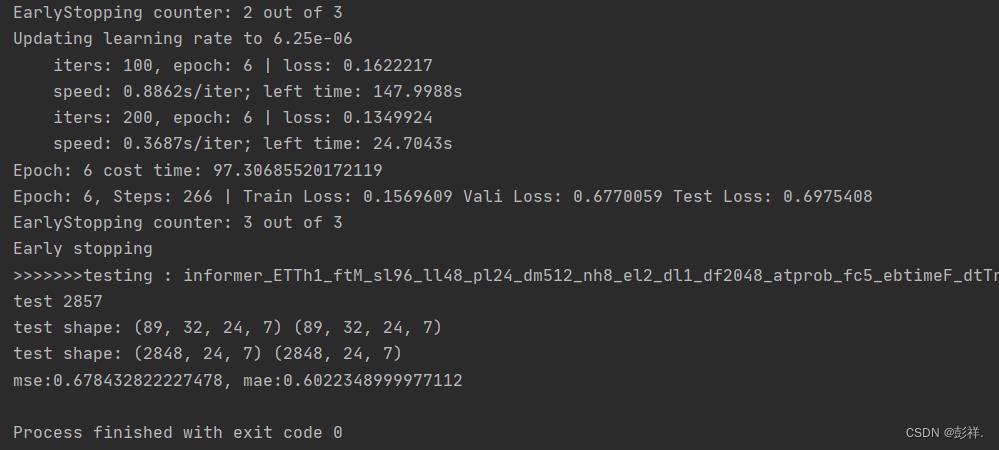
运行结果
学习重点
学习如何处理数据集于模型如何搭建
我们在获得一个项目源码及论文文档后,可以先不着急取调试这个项目,而是应该仔细去阅读关于项目的介绍,看看他的具体研究方向是否与自己相符合,看看他的研究方法是否可以为我所借鉴,观察其目录结构,并尝试去理解。
在完成这个过程后我们开始源码的学习过程。我们一般需要带着问题去完成这个过程:
数据是什么?数据特征是哪些?标签是哪些?
数据是如何预处理的?数据是如何放入模型开始训练的?
模型是如何搭建的?数据训练完成后得到什么,如何使用?
关于Informer项目的运行原理可以看博主这篇博文:
时间序列预测之为何舍弃LSTM而选择Informer?(Informer模型解读)
整个项目与先前的Tensorflow版本大致相同,但这个pytorch版本的自定义函数较多,因此还是有些许差距的,下面开始我们的学习过程:
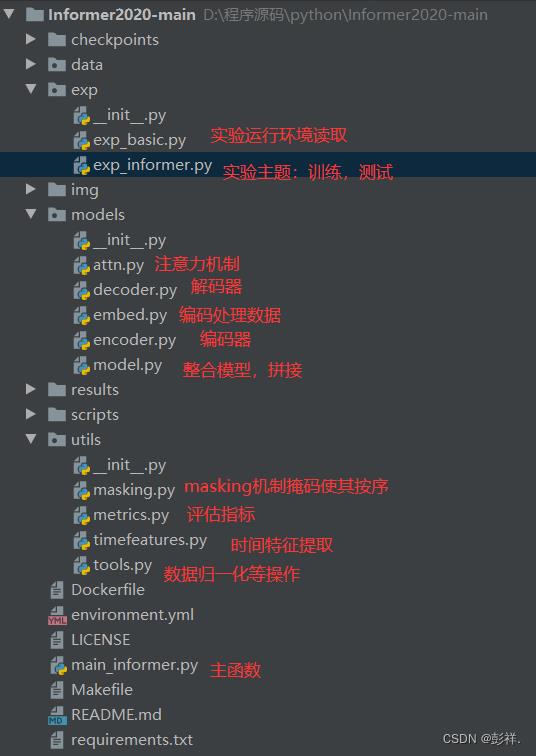
文件目录结构
参数含义
# 选择模型(去掉required参数,选择informer模型)
parser.add_argument('--model', type=str, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
# 数据选择(去掉required参数)
parser.add_argument('--data', type=str, default='WTH', help='data')
# 数据上级目录
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
# 数据名称
parser.add_argument('--data_path', type=str, default='WTH.csv', help='data file')
# 预测类型(多变量预测、单变量预测、多元预测单变量)
parser.add_argument('--features', type=str, default='M', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 数据中要预测的标签列
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
# 数据重采样(h:小时)
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型保存位置
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
# 输入序列长度
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
# 先验序列长度
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测序列长度
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
# 编码器default参数为特征列数
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
# 解码器default参数与编码器相同
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')
# 模型宽度
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制头数
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
# 模型中encoder层数
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
# 模型中decoder层数
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 网络架构循环次数
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
# 全连接层神经元个数
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 采样因子数
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
# 1D卷积核
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 是否需要序列长度衰减
parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True)
# 神经网络正则化操作
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
# attention计算方式
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
# 时间特征编码方式
parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')
# 激活函数
parser.add_argument('--activation', type=str, default='gelu',help='activation')
# 是否输出attention
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
# 是否需要预测
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data')
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
# 数据读取
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
# 多核训练(windows下选择0,否则容易报错)
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 训练轮数
parser.add_argument('--itr', type=int, default=2, help='experiments times')
# 训练迭代次数
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# mini-batch大小
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 早停策略
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test',help='exp description')
# loss计算方式
parser.add_argument('--loss', type=str, default='mse',help='loss function')
# 学习率衰减参数
parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')
# 是否使用自动混合精度训练
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
# 是否反转输出结果
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=False)
# 是否使用GPU加速训练
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
# GPU分布式训练
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
# 多GPU训练
parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus')
# 取参数值
args = parser.parse_args()
# 获取GPU
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
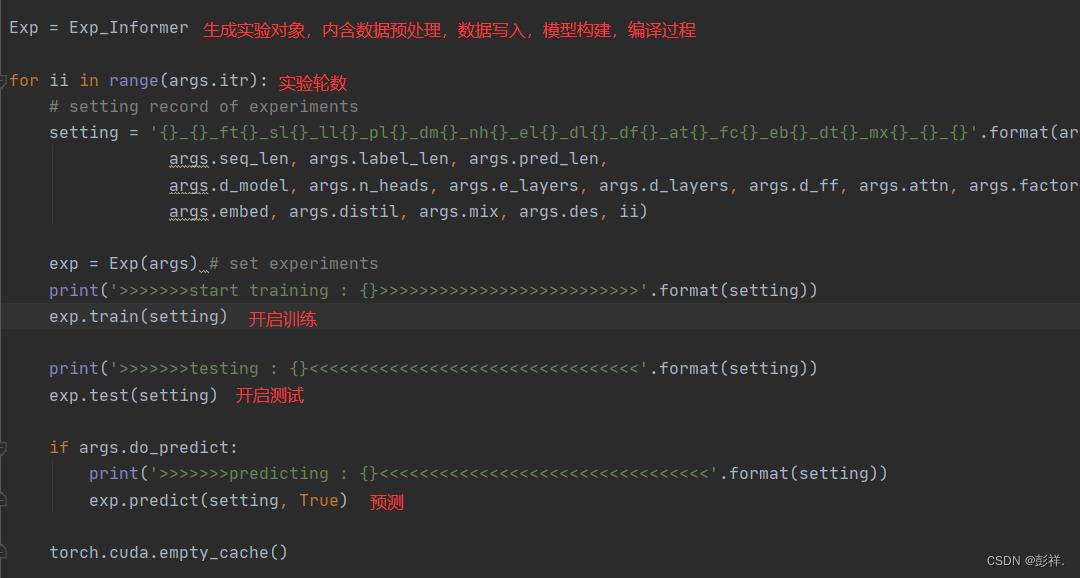
以上是关于2021 AAAI best Paper - Informer-2020 学习记录的主要内容,如果未能解决你的问题,请参考以下文章