Elasticsearch 8.X 如何动态的为正文添加摘要字段?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 8.X 如何动态的为正文添加摘要字段?相关的知识,希望对你有一定的参考价值。
1、实战问题
返回指定字段可以用:
"_source":
"includes": [
*
],
"excludes": [
"a"
]
那有没有什么办法在返回指定字段的基础上指定返回前50个字符呢?
例如我现在有一个file_data字段,字段长度可能在一千以上并且需要对这个字段分词和检索,目前想指定返回file_data字段的前50字符,请问有没有什么好的方法?
——问题来源:死磕Elasticsearch知识星球 https://t.zsxq.com/052rvJ6q7
2、解决方案探讨
这个问题仅涉及到字符级别的提取,可以将上述问题精简提炼为:“已知正文字段 cont,如何提取前50个字符形成 abstr”, 其实如果是 java 里就一行代码:
String abstr = cont.substring(0, 50);python里也是一行代码搞定:
abstr = Substr(cont, 0, 50)而 Elasticsearch 如何实现呢?
其实,看到这里可能有同学说:“早干什么呢?写入的时候,提前建模好,直接根据 cont 自动生成好 abstr,不就可以了吗?”
但是,这是“事后诸葛亮”的做法,实战环节,大家可能都是有考虑场景不充分的情况。
所以,本文的假设已经写入了数十亿甚至更多的数据,不方便再重新导入数据,只考虑在已有数据的基础上做处理的问题。
多说一句,实际业务环节,摘要的提取可不是简单提取前置字符这么简单,还要考虑语义。语义级别的摘要的提取需要借助:深度神经网络的生成式自动文本摘要,举例:基于BERT实现,基于Seq2Seq+Attention模型改良实现,基于Seq2Seq模型对于长文本会产生数据截断等......
3、Elasticsearch 三种实现方案
基于上面的讨论,仅就字符级别,Elasticsearch 可以有如下几种方案。
方案一:基于 script field query 检索实现。
方案二:基于 runtime_field 运行时字段实现。
方案三:基于 ingest pipeline 预处理更新或者重新导入或 reindex 实现。
3.0 定义数据
有了数据,游刃有余。本文基于 Elasticsearch 8.1.0 实现。
用了“龙哥”数据作为索引,因为“龙哥”活全。
DELETE luo_index_001
PUT luo_index_001
"mappings":
"properties":
"cont":
"type": "text",
"analyzer": "ik_smart",
"fields":
"keyword":
"type": "keyword"
POST luo_index_001/_bulk
"index":"_id":1
"cont":"罗永浩一路走来,经历了很多的坎坷和磨难,有时候甚至于落入到万丈深渊,但是,罗永浩始终初心不改,最终成了让人为之敬佩的成功人士。这个沃尔沃汽车93年在汽车安全领域的坚守一样,因此,世界上才会有最安全的沃尔沃汽车的诞生。在安面前,人人平等沃在造车上一直秉承着的信念。因此,我们能够看到沃尔沃全系标配的诸多配置,例如CitySafety城市安全系统、道路偏离预防和爱护系统、LKA车道保持辅助、DAC疲惫警示系统等标准智能安全系统在其它品牌车型上不是选装就是顶配车型才有。同时,全方位智能护航系统和智能领航辅助系统,配置比率也远高于同级竞品。想必很多人都看过沃尔沃在遇到突发情况时紧急制动的相关视频。有时候,危险和安全之间的距离就是一两秒钟,而沃尔沃就是把你拉向安全更近一点。我想,这不仅仅是沃尔沃给车主带来的实实在在的帮助,也是沃尔沃对于整个行业的贡献。对于健康,沃尔沃可谓把控到了极致除了安全,健康和环保也能够在沃尔沃车型中看到,因为与豪华感等空洞的词汇相比,健康和环保仿佛更能体现出一辆车的豪华感。对于健康,沃尔沃可谓把控到了极致。除了与Blueair一起研发的AAC双效增强型空气净化系统外,沃尔沃还创立鼻子小组,专门对车内看不见的处所进行健康把关。而且提出了骨骼肌肉健康、触觉健康、听觉健康等健康座舱的观点,让用户能够享受到更极致的安全。经过十年的发展,现阶段,沃尔沃拥有SPA可扩展模块架构和CMA基础模块架构,而且众多车型已经完成换代,在中国上市。现在的沃尔沃已经完成涵盖豪华SUV、豪华轿车和豪华旅行车的产品矩阵,在主流豪华车市场占据了一席之地,满足不同用户的个性化需求。沃尔沃S90作为一款豪车新贵,在这个级别的车中,硬件肯定没问题的。值得让人花这个价钱,品牌的口碑有目共睹,提起沃尔沃就让人想到安全。作为现阶段沃尔沃品牌主推的豪车车型,沃尔沃S90的隔音性和操控性都非常具有优势,特别是用料方面,没有减配,这比同级别的BBA车型要厚道得多沃尔沃正是10年如一日的走在追求安全的路上,才有世界上最安全的汽车诞生;沃尔沃才能赢得更多的消费者的认可。沃尔沃汽车的安全的特别属性,早已根植在消费者的心中,因此,沃尔沃汽车才能成为消费者的购车首选。"3.1 方案一 script field query
POST luo_index_001/_search
"script_fields":
"abstr":
"script":
"lang": "painless",
"source": "doc['cont.keyword'].value.substring(0,50)"
执行效果如下:
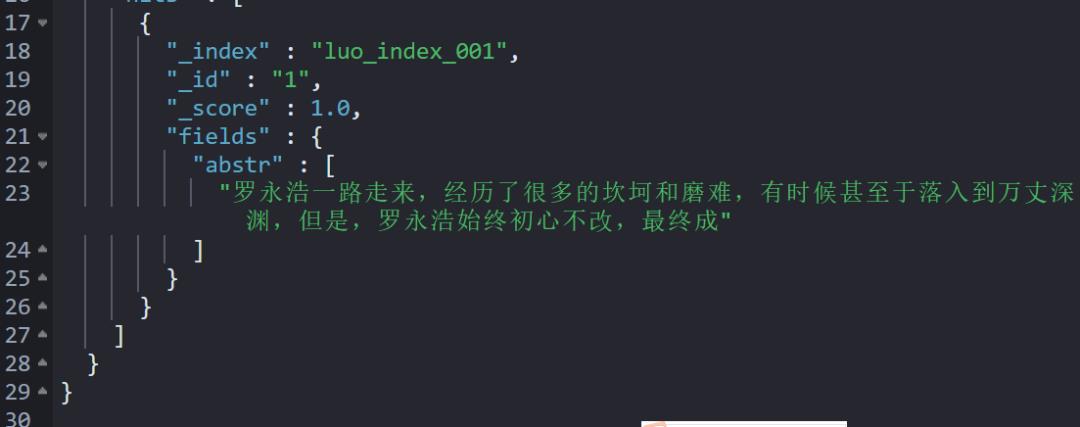
3.2 方案二 runtime_field
POST luo_index_001/_search
"fields": [
"abstr"
],
"_source":
"excludes": "cont"
,
"runtime_mappings":
"abstr":
"type": "keyword",
"script":
"source": "emit(doc['cont.keyword'].value.substring(0,50))"
执行效果如下:
参考知识点:Elasticsearch 运行时类型 Runtime fields 深入详解
3.3 方案三:写入前数据预处理,检索后立得
前置条件:定义预处理管道。
涉及知识点:Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
PUT _ingest/pipeline/add_abstr_20220815
"processors": [
"script":
"lang": "painless",
"source": """
ctx.abstr = ctx.cont.substring(0, 50);
"""
]
3.3.1 写入的时候指定缺省管道 default_pipeline
DELETE luo_index_002
PUT luo_index_002
"settings":
"index.default_pipeline":"add_abstr_20220815"
,
"mappings":
"properties":
"abstr":
"type": "text",
"analyzer": "ik_smart",
"fields":
"keyword":
"type": "keyword"
,
"cont":
"type": "text",
"analyzer": "ik_smart",
"fields":
"keyword":
"type": "keyword"
POST luo_index_002/_bulk
"index":"_id":1
"cont":"罗永浩一路走来,...省略1000字+...汽车才能成为消费者的购车首选。"
POST luo_index_002/_search
"_source":
"excludes": "cont"
执行效果如下:
3.3.2 批量更新update_by_query 和 预处理管道结合
POST luo_index_001/_update_by_query?pipeline=add_abstr_20220815
"query":
"match_all":
POST luo_index_001/_search
"_source":
"excludes": "cont"
执行效果如下:
4、小结
全程无废话视频解读>>
如果方便,依然重磅推荐写入前提前建模充分的方式,有了提前建模本文的一切都是多余。
万不得已,推荐本文的方案三。方案一、方案二在数据量极大的情况会性能非常低,使用时慎重一些。
推荐阅读

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 8.X 如何动态的为正文添加摘要字段?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 8.X 如何动态的为正文添加摘要字段?
Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发
Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发
Elasticsearch:如何在 CentOS 上创建多节点的 Elasticsearch 集群 - 8.x
Elasticsearch:如何在 CentOS 上创建多节点的 Elasticsearch 集群 - 8.x
Logstash:如何配置 Metricbeat 及 Logstash 为 Elasticsearch 8.x 收集数据