SORT+DeepSORT
Posted Arrow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SORT+DeepSORT相关的知识,希望对你有一定的参考价值。
SORT+DeepSORT
1. 简介
- SORT: Simple Online and Realtime Tracking
- MOT:Multiple Object Tracking (是一个数据关联问题)
- BBox:Bounding Box
- ReID:Re-Identification
- MOTA:Multi-object tracking accuracy
- MOTP:Multi-object tracking precision
- FP:number of false detections (误检数)
- FN:number of missed detections (漏检数)
- 奥卡姆剃刀定律(Occam’s Razor) :“如无必要,勿增实体”,即“简单有效原理”
1.1 评价指标
- ( o i , h j ) (o_i, h_j) (oi,hj):是对象 o i o_i oi与跟踪假设 ( h j ) (h_j) (hj)间的一个映射(匹配),且它们的距离不超过阈值 T T T,所有的映射应当确保所有的距离和最小
- c t c_t ct:在时间 t t t ,找到的匹配数量
- d t i d_t^i dti:在时间 t t t,对象 o i o_i oi与它的跟踪假设间的距离 (距离计算方法:区域(框)跟踪器,距离可用两者的重叠区域来度量;点跟踪器,距离可用两者中心点的欧氏距离来度量)
- f p t fp_t fpt:在时间 t t t,未被匹配的跟踪假设数量(false positive)
- m t m_t mt:在时间 t t t,未被匹配的对象数量(missed objects)
- g t g_t gt:在时间 t t t,找到的对象数量
- m m e t mme_t mmet:在时间 t t t,ID跳变数量
- MOTP:跟踪定位精度指标
M O T P = Σ i , t d t i Σ t c t MOTP = \\frac\\Sigma_i,t d_t^i\\Sigma_t c_t MOTP=ΣtctΣi,tdti - MOTA:综合了漏检率,误检率,以及 ID 跳变率
M O T A = 1 − Σ t ( m t + f p t + m m e t ) Σ t g t MOTA = 1 - \\frac\\Sigma_t(m_t + fp_t + mme_t)\\Sigma_t g_t MOTA=1−ΣtgtΣt(mt+fpt+mmet)
1.2 SORT功能
- 仅使用Kalman Filter和Hungarian algorithm获得较好的准确率和实时性
- 在图像空间执行卡尔曼滤波
- 使用匈牙利算法进行相邻帧间的数据关联
- 遵循奥卡姆剃刀定律,未考虑以下因素:
- 外观特征
- 短期和长期的遮挡
- 其速度模型仅考虑相邻帧间的预测,而未考虑对象重识别(ReID)
- 不足之外
- 仅状态估计不确定性低时效果才比较好 (由所使用的关联指标决定的)
1.3 DeepSORT功能
- 方法:
- 在SORT的基础上,集成了外观信息(appearance information)以改善SORT的性能
- 在可视的外观空间中,通过最近邻查询方法(nearest neighbor queries)来建立测量到跟踪的关联(measurement-to-track associations)
- 效果:
- 可跟踪长时间遮挡的对象
- 有效地减少了ID跳变
1.4 实现方案
- 视频中不同时刻的同一个人,位置发生了变化,那么是如何关联上的呢? 答案就是:
- 匈牙利算法
- 卡尔曼滤波。
- 卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。
- 匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同。
2. 卡尔曼滤波(Kalman Filter: 运动预测)
- 作用:基于传感器的测量值来更新预测值,以达到更精确的估计。
- 举例说明:假设我们要跟踪小车的位置变化,如下图所示,蓝色的分布是卡尔曼滤波预测值,棕色的分布是传感器的测量值,灰色的分布就是基于测量值更新后的最优估计值。
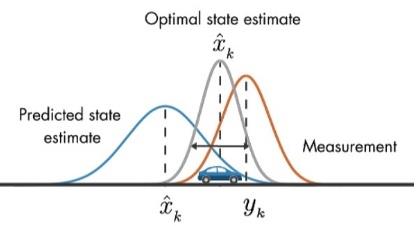
- 在目标跟踪中,需要估计track的以下两个状态:
- 均值(Mean):表示目标的位置信息,由BBox的中心坐标 ( c x , c y ) (c_x, c_y) (cx,cy),宽高比r,高h,以及各自的速度变化值组成,由8维向量表示为 x = [ c x , c y , r , h , v x , v y , v r , v h ] x = [c_x, c_y, r, h, v_x, v_y, v_r, v_h] x=[cx,cy,r,h,vx,vy,vr,vh],各个速度值初始化为0。
- 协方差(Covariance ):表示目标位置信息的不确定性,由8x8的对角矩阵表示,矩阵中数字越大则表明不确定性越大,可以以任意值初始化。
- 卡尔曼滤波分为两个阶段:
- (1) 预测track在下一时刻的位置
- (2) 基于detection来更新预测的位置。
3. 匈牙利算法(Hungarian Algorithm:数据关联)
3.1 分配问题(Assignment Problem)
- 假设有N个人和N个任务,每个任务可以任意分配给不同的人,已知每个人完成每个任务要花费的代价不尽相同,那么如何分配可以使得总的代价最小。
- 举个例子,假设现在有3个任务,要分别分配给3个人,每个人完成各个任务所需代价矩阵(cost matrix)如下所示(这个代价可以是金钱、时间等等)
P e r s o n Task1 Task2 Task3 P e r s o n 1 15 40 45 P e r s o n 2 20 60 35 P e r s o n 3 20 40 25 \\beginarrayc|lcr Person & \\textTask1 & \\textTask2 & \\textTask3 \\\\ \\hline Person1 & 15 & 40 & 45 \\\\ Person2 & 20 & 60 & 35 \\\\ Person3 & 20 & 40 & 25 \\endarray PersonPerson1Person2Person3Task1152020Task2406040Task3453525 - 怎样才能找到一个最优分配,使得完成所有任务花费的代价最小呢?
3.2 匈牙利算法(又叫KM算法)
- 匈牙利算法:就是用来解决分配问题的一种方法,它基于定理:如果代价矩阵的某一行或某一列同时加上或减去某个数,则这个新的代价矩阵的最优分配仍然是原代价矩阵的最优分配
3.2.1 算法步骤(假设矩阵为NxN方阵)
- 对于矩阵的每一行,减去其中最小的元素
- 对于矩阵的每一列,减去其中最小的元素
- 用最少的水平线或垂直线覆盖矩阵中所有的0
- 如果线的数量等于N,则找到了最优分配,算法结束,否则进入步骤5
- 找到没有被任何线覆盖的最小元素,每个没被线覆盖的行减去这个元素,每个被线覆盖的列加上这个元素,返回步骤3
-
step1 每一行最小的元素分别为15、20、20,减去得到:
P e r s o n Task1 Task2 Task3 P e r s o n 1 0 25 30 P e r s o n 2 0 40 15 P e r s o n 3 0 20 5 \\beginarrayc|lcr Person & \\textTask1 & \\textTask2 & \\textTask3 \\\\ \\hline Person1 & 0 & 25 & 30 \\\\ Person2 & 0 & 40 & 15 \\\\ Person3 & 0 & 20 & 5 \\endarray PersonPerson1Person2Person3Task1000Task2254020Task330155 -
step2 每一列最小的元素分别为0、20、5,减去得到:
P e r s o n Task1 Task2 Task3 P e r s o n 1 0 5 25 P e r s o n 2 0 20 10 P e r s o n 3 0 0 0 \\beginarrayc|lcr Person & \\textTask1 & \\textTask2 & \\textTask3 \\\\ \\hline Person1 & 0 & 5 & 25 \\\\ Person2 & 0 & 20 & 10 \\\\ Person3 & 0 & 0 & 0 \\endarray以上是关于SORT+DeepSORT的主要内容,如果未能解决你的问题,请参考以下文章