XML - 十分钟了解XML结构以及DOM和SAX解析方式
Posted 来世当猪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML - 十分钟了解XML结构以及DOM和SAX解析方式相关的知识,希望对你有一定的参考价值。
引言
NOKIA 有句著名的广告语:“科技以人为本”。任何技术都是为了满足人的生产生活需要而产生的。具体到小小的一个手机,里面蕴含的技术也是浩如烟海,是几千年来人类科技的结晶,单个人穷其一生也未必能掌握其一角。不过个人一直认为基本的技术和思想是放之四海而皆准的,许多技术未必需要我们从头到尾再研究一遍,我们要做的就是站在巨人的肩膀上,利用其成果来为人们的需求服务。
随着移动互联网时代的大潮,越来越多的App不光是需要和网络服务器进行数据传输和交互,也需要和其他 App 进行数据传递。承担App与网络来进行传输和存储数据的一般是XML或者JSON。在移动互联网时代,XML和JSON很重要。
最近一段时间,个人综合了之前对XML、JSON的一些了解,参考了相关资料,再结合视频的代码,把自己的一些思考融入了这篇总结文档中,同时尝试用通俗诙谐的语言风格来阐述,期望能给感兴趣的读者带来帮助。
为了不和时代落伍,我们必须要学习 XML 和 JSON,但同时它们也很容易学习,Let’s start:–)
一、XML
XML即可扩展标记语言(eXtensible Markup Language)。标记是指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。如何定义这些标记,既可以选择国际通用的标记语言,比如html,也可以使用象XML这样由相关人士自由决定的标记语言,这就是语言的可扩展性。XML是从SGML中简化修改出来的。它主要用到的有XML、XSL和XPath等。
上面这段是对XML的一个基本定义,一个被广泛接受的说明。简单说,XML就是一种数据的描述语言,虽然它是语言,但是通常情况下,它并不具备常见语言的基本功能——被计算机识别并运行。只有依靠另一种语言,来解释它,使它达到你想要的效果或被计算机所接受。
记住以下几点就行了:
XML是一种标记语言,很类似HTML
XML的设计宗旨是传输数据,而非显示数据
XML标签没有被预定义。您需要自行定义标签。
XML被设计为具有自我描述性。
XML是W3C的推荐标准
总结:
XML是独立于软件和硬件的信息传输工具。 目前,XML在Web中起到的作用不会亚于一直作为 Web 基石的 HTML。 XML无所不在。XML是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。
1.1 XML属性
1.1.1 XML与HTML的主要差异
XML不是HTML的替代。
XML和HTML为不同的目的而设计。
XML被设计为传输和存储数据,其焦点是数据的内容。
HTML被设计用来显示数据,其焦点是数据的外观。
HTML旨在显示信息,而 XML 旨在传输信息
1.1.2 XML是不作为的。
也许这有点难以理解,但是XML不会做任何事情。XML被设计用来结构化、存储以及传输信息。
下面是John写给George的便签,存储为XML:
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>上面的这条便签具有自我描述性。它拥有标题以及留言,同时包含了发送者和接受者的信息。但是,这个 XML 文档仍然没有做任何事情。它仅仅是包装在XML标签中的纯粹的信息。我们需要编写软件或者程序,才能传送、接收和显示出这个文档。
1.1.3 XML仅仅是纯文本
XML没什么特别的。它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理XML。 不过,能够读懂 XML 的应用程序可以有针对性地处理 XML 的标签。标签的功能性意义依赖于应用程序的特性。
1.1.4 XML允许自定义标签
上例中的标签没有在任何XML标准中定义过(比如和)。这些标签是由文档的创作者发明的。这是因为XML没有预定义的标签。
在HTML中使用的标签(以及HTML的结构)是预定义的。HTML文档只使用在HTML标准中定义过的标签
XML允许创作者定义自己的标签和自己的文档结构。
1.1.5 XML不是对HTML的替代
XML是对HTML的补充。
XML不会替代HTML,理解这一点很重要。在大多数 web 应用程序中,XML用于传输数据,而HTML用于格式化并显示数据。
1.2 XML的语法
XML的语法规则很简单,且很有逻辑。这些规则很容易学习,也很容易使用。
1.2.1 所有元素都必须有关闭标签
在XML中,省略关闭标签是非法的。所有元素都必须有关闭标签。 在HTML,经常会看到没有关闭标签的元素:
<p>This is a paragraph
<p>This is another paragraph在XML中,省略关闭标签是非法的。所有元素都必须有关闭标签:
<p>This is a paragraph</p>
<p>This is another paragraph</p>注释:您也许已经注意到XML声明没有关闭标签。这不是错误。声明不属于XML本身的组成部分。它不是XML元素,也不需要关闭标签。
1.2.2 XML标签对大小写敏感
XML元素使用XML标签进行定义。
XML标签对大小写敏感。在XML中,标签与标签是不同的。
必须使用相同的大小写来编写打开标签和关闭标签:
<Message>这是错误的。</message>
<message>这是正确的。</message>1.2.3 XML标签对大小写敏感
在 HTML 中,常会看到没有正确嵌套的元素:
<b><i>This text is bold and italic</b></i>在 XML中,所有元素都必须彼此正确地嵌套:
<b><i>This text is bold and italic</i></b>在上例中,正确嵌套的意思是:由于元素是在元素内打开的,那么它必须在元素内关闭。
1.2.4 XML文档必须有根元素
XML文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
<root>
<child>
<subchild>.....</subchild>
</child>
</root>1.2.5 XML的属性值须加引号
与 HTML 类似,XML 也可拥有属性(名称/值的对)。 在 XML 中,XML 的属性值须加引号。请研究下面的两个 XML 文档。第一个是错误的,第二个是正确的:
<note date=08/08/2008>
<to>George</to>
<from>John</from>
</note>
<note date="08/08/2008">
<to>George</to>
<from>John</from>
</note>1.2.6 实体引用
在 XML 中,一些字符拥有特殊的意义。 如果你把字符 “<” 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。 这样会产生 XML 错误:
<message>if salary < 1000 then</message>为了避免这个错误,请用实体引用来代替 “<” 字符:
<message>if salary < 1000 then</message>在 XML 中,有 5 个预定义的实体引用:
< < 小于
> > 大于
& & 和号
’ ’ 单引号
" ” 引号
注释:在 XML 中,只有字符 “<” 和 “&” 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
1.2.7 XML中的注释
在 XML 中编写注释的语法与 HTML 的语法很相似:
<!-- This is a comment -->在 XML 中,空格会被保留 HTML 会把多个连续的空格字符裁减(合并)为一个:
HTML: Hello my name is David.输出: Hello my name is David. 在 XML 中,文档中的空格不会被删节。
1.2.8 以 LF 存储换行
在 Windows 应用程序中,换行通常以一对字符来存储:回车符 (CR) 和换行符 (LF)。这对字符与打字机设置新行的动作有相似之处。在 Unix 应用程序中,新行以 LF 字符存储。而 Macintosh 应用程序使用CR来存储新行。
1.3 XML CDATA
所有XML文档中的文本均会被解析器解析。
只有CDATA区段(CDATA section)中的文本会被解析器忽略。
1.3.1 PCDATA
PCDATA指的是被解析的字符数据(Parsed Character Data)。
XML解析器通常会解析XML文档中所有的文本。 当某个XML元素被解析时,其标签之间的文本也会被解析:
<message>此文本也会被解析</message>解析器之所以这么做是因为 XML 元素可包含其他元素,就像这个例子中,其中的元素包含着另外的两个元素(first和last):
<name><first>Bill</first><last>Gates</last></name>而解析器会把它分解为像这样的子元素:
<name>
<first>Bill</first>
<last>Gates</last>
</name>1.3.2 转义字符
非法的XML字符必须被替换为实体引用(entity reference)。
假如您在XML文档中放置了一个类似 “<” 字符,那么这个文档会产生一个错误,这是因为解析器会把它解释为新元素的开始。因此你不能这样写:
<message>if salary < 1000 then</message>为了避免此类错误,需要把字符 “<” 替换为实体引用,就像这样:
<message>if salary < 1000 then</message>在 XML 中有 5 个预定义的实体引用:
< < 小于
> > 大于
& & 和号
' ' 省略号
" " 引号注释:严格地讲,在XML中仅有字符”<“和”&“是非法的。省略号、引号和大于号是合法的,但是把它们替换为实体引用是个好的习惯。
1.3.3 CDATA
术语CDATA指的是不应由XML解析器进行解析的文本数据(Unparsed Character Data)。
在 XML 元素中,”<“ 和 ”&“ 是非法的。
“<” 会产生错误,因为解析器会把该字符解释为新元素的开始。 “&” 也会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 javascript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。 CDATA 部分中的所有内容都会被解析器忽略。 CDATA 部分由 “
<?xml version="1.0" encoding="utf-8"?>
<response>
<header>
<respcode>0</respcode>
<total>1736</total>
</header>
<result>
<album>
<album_id>320305900</album_id>
<title> <![CDATA[ 电影侃侃之初恋永不早 ]]> </title>
<tag> <![CDATA[ 18岁以上 当代 暧昧 华语 ]]> </tag>
<img>http://pic9.qiyipic.com/image/20141016/ec/e0/v_108639906_m_601_120_160.jpg</img>
<img180236>http://pic9.qiyipic.com/image/20141016/ec/e0/v_108639906_m_601_180_236.jpg</img180236>
<img11577>http://pic9.qiyipic.com/image/20141016/ec/e0/v_108639906_m_601_115_77.jpg</img11577>
<img220124>http://pic9.qiyipic.com/image/20141016/ec/e0/v_108639906_m_601_284_160.jpg</img220124>
<category_id>1</category_id>
<score>0.0</score>
<voters>0</voters>
<tv_sets>0</tv_sets>
<duration>00:38:57</duration>
<year> <![CDATA[ 2014 ]]> </year>
<tv_focus>跟爱情片学把妹心经</tv_focus>
<episode_count>1</episode_count>
<directors> <![CDATA[ 关雅荻 ]]> </directors>
<mainactors> <![CDATA[ 关雅荻 ]]> </mainactors>
<actors> <![CDATA[ ]]> </actors>
<vv2> <![CDATA[ 15 ]]> </vv2>
<timeText> <![CDATA[ 今天 ]]> </timeText>
<first_issue_time> <![CDATA[ 2014-10-16 ]]> </first_issue_time>
<up>0</up>
<down>0</down>
<download>1</download>
<purchase_type>0</purchase_type>
<hot_or_new>0</hot_or_new>
<createtime>2014-10-16 12:25:08</createtime>
<purchase>0</purchase>
<desc> <![CDATA[
本期节目主持人介绍新近上映的口碑爱情片,。主持人轻松幽默的罗列出胡鳄鱼导演拍摄的爱情片越来越接地气,博得观众的认同和追捧,更提出“初恋永远不嫌早”的口号。观众可以跟着爱情片学习把妹心经。
]]> </desc>
<ip_limit>1</ip_limit>
<episodes/>
</album>
</result>
</response>这是展示一部电影的具体数据,包括标题、介绍、内容、导演、演员、时长、上映年份等很多内容。
1.5 XML树结构
XML文档形成了一种树结构,它从“根部”开始,然后扩展到“枝叶”。
1.5.1 一个XML文档实例
XML使用简单的具有自我描述性的语法:
<?xml version="1.0" encoding="ISO-8859-1"?>
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>第一行是XML声明。它定义XML的版本(1.0)和所使用的编码(ISO-8859-1=Latin-1/西欧字符集)。
下一行描述文档的根元素(像在说:“本文档是一个便签”):
<note>接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body):
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>最后一行定义根元素的结尾:
</note>从本例可以设想,该XML文档包含了John给George的一张便签。
XML具有出色的自我描述性,你同意吗?
XML文档形成一种树结构
XML文档必须包含根元素。该元素是所有其他元素的父元素。
XML文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有元素均可拥有子元素:
<root>
<child>
<subchild>.....</subchild>
</child>
</root>父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
所有元素均可拥有文本内容和属性(类似HTML中)。
1.6 XML DOM
这是解析XML的两种解析方式
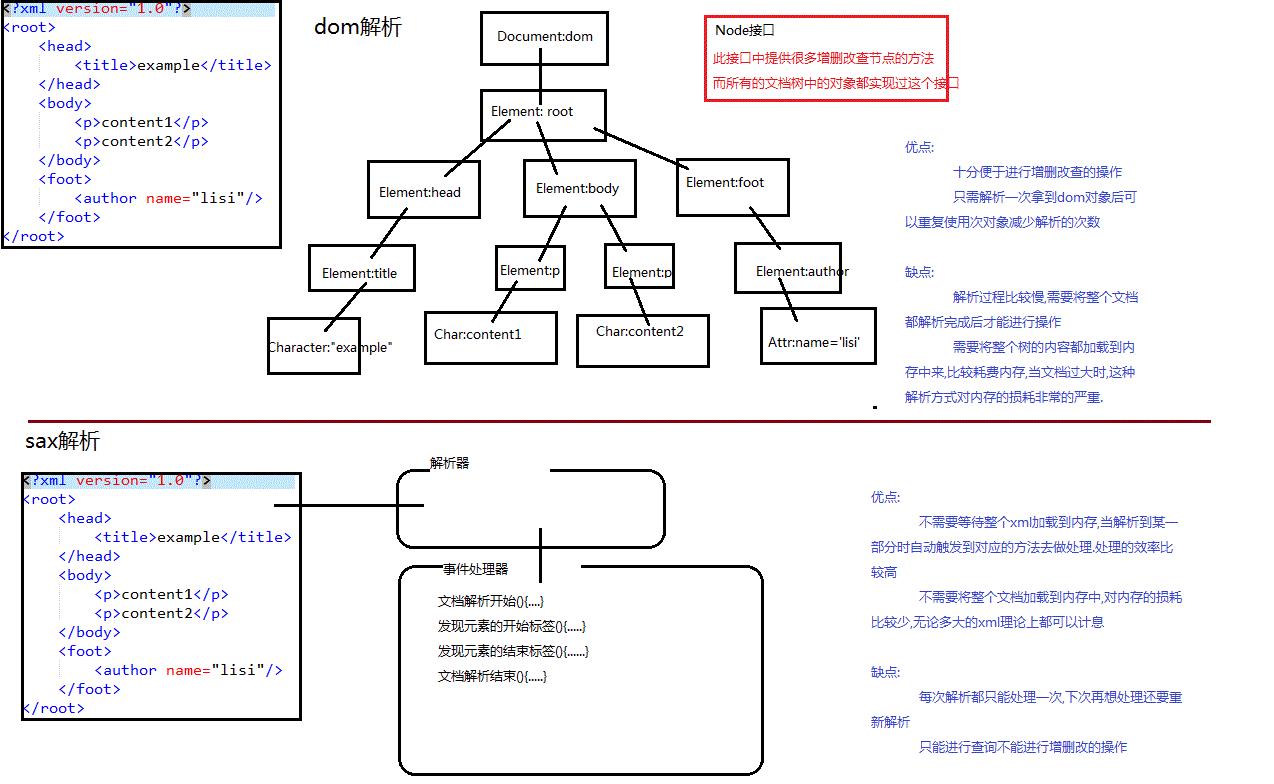
想到这里,大家都有点迫不及待了,XML 文件到底如何解析呢?
但是,别急,让子弹先飞会儿:–)
在XML解析之前,我们必须系统性的学习一下 XML DOM 知识:
1.6.1 定义
XML DOM(XML Document Object Model) 定义了访问和操作XML文档的标准方法。
DOM把XML文档作为树结构来查看。能够通过DOM树来访问所有元素。可以修改或删除它们的内容,并创建新的元素。元素,它们的文本,以及它们的属性,都被认为是节点。
XML DOM是:
- 用于XML的标准对象模型
- 用于XML的标准编程接口
- 中立于平台和语言
- W3C的标准
XML DOM定义了所有XML元素的对象和属性,以及访问它们的方法(接口)。
换句话说:
XML DOM是用于获取、更改、添加或删除XML元素的标准
DOM将XML文档作为一个树形结构,而树叶被定义为节点。
1.6.2 总结
XML DOM其实比较复杂,在这么短的篇幅里也无法一一进行讲解。想详细了解XML DOM可以好好去学习下
实例代码:
book.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>39.00元</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>dom4j解析
package com.itheima.dom4j;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jDemo1
public static void main(String[] args) throws Exception
//1.获取解析器
SAXReader reader = new SAXReader();
//2.解析xml获取代表整个文档的dom对象
Document dom = reader.read("book.xml");
//3.获取根节点
Element root = dom.getRootElement();
//4.获取书名进行打印
String bookName = root.element("书").element("书名").getText();
System.out.println(bookName);
先获取解析器,然后read所要解析的xml,获取到了所有元素,在通过rootElement获取到根节点,获取到根节点过后进行解析
Sax解析方式
//1.获取解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.通过工厂获取sax解析器
SAXParser parser = factory.newSAXParser();
//3.获取读取器
XMLReader reader = parser.getXMLReader();
//4.注册事件处理器
reader.setContentHandler(new MyContentHandler2() );
//5.解析xml
reader.parse("book.xml");class MyContentHandler implements ContentHandler
public void startDocument() throws SAXException
System.out.println("文档解析开始了.......");
public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException
System.out.println("发现了开始标签,"+name);
public void characters(char[] ch, int start, int length)
throws SAXException
System.out.println(new String(ch,start,length));
public void endElement(String uri, String localName, String name)
throws SAXException
System.out.println("发现结束标签,"+name);
public void endDocument() throws SAXException
System.out.println("文档解析结束了.......");
获取到解析器工厂,通过工厂获取sax解析器,获取读取器,注册处理器,并解析xml
解析思想:
dom解析
sax解析
基于这两种解析思想市面上就有了很多的解析api
sun jaxp既有dom方式也有sax方式,并且这套解析api已经加入到j2se的规范中,意味这不需要导入任何第三方开发包就可以直接使用这种解析方式.但是这种解析方式效率低下,没什么人用.
dom4j 可以使用dom方式高效的解析xml.
pull
!!dom4j
导入开发包,通常只需要导入核心包就可以了,如果在使用的过程中提示少什么包到lib目录下在导入缺少的包即可
Schema – xml的约束技术 — 需要掌握名称空间的概念,会读简单的Schema就可以了,不需要大家自己会写
Schema是xml的约束技术,出现的目的是为了替代dtd
本身也是一个xml,非常方便使用xml的解析引擎进行解析
对名称空间有非常好的支持
支持更多的数据类型,并且支持用户自定义数据类型
可以进行语义级别的限定,限定能力大大强于dtd
相对于dtd不支持实体
相对于dtd复杂的多,学习成本比较的高
如何在xml中引入Schema --- !!!!!名称空间的概念:全世界独一无二的名字,用来唯一的标识某个资源,通常是公司的域名,只是名字而已并不真的表示资源的位置.
~~~ Schema的语法---参照Schema的文档,了解即可
以上是关于XML - 十分钟了解XML结构以及DOM和SAX解析方式的主要内容,如果未能解决你的问题,请参考以下文章