定时器实现原理——时间轮
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了定时器实现原理——时间轮相关的知识,希望对你有一定的参考价值。
时间轮
时间轮算法是通过一个时间轮去维护定时任务,按照一定的时间单位对时间轮进行划分刻度。然后根据任务延时计算任务落在该时间轮的第几个刻度上,如果任务时长超出了刻度数量,则需要增加一个参数记录时间轮需要转动的圈数。
简单时间轮
时间轮类似于我们的钟表,当指针指到刻度上,我们就去执行对应的任务列表。例如,我们需要统计每个小时的登录用户数。
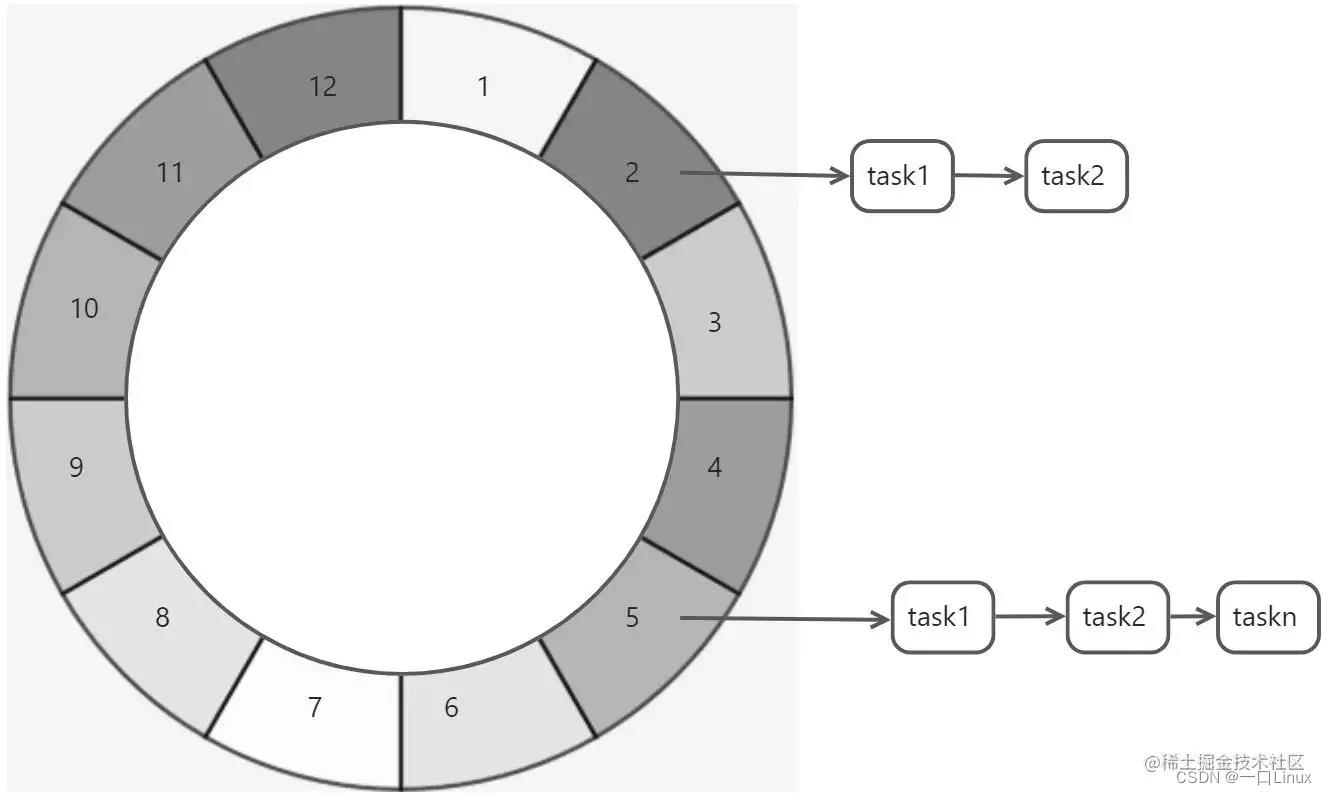
时间轮算法中,轮询线程遍历到某一个时间刻度后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理),而不再需要遍历检查所有任务的时间戳是否达到要求(不用每次从小顶堆堆顶,取数据来和时间比较,然后堆化这些操作)。
现在我们即使有n个任务,轮询线程也没有必要,每轮遍历n次,我们只需要按照时间刻度来轮训即可。
不过,小时作为时间单位粒度太大,我们有时候往往会希望基于分钟、秒等作为时间刻度。最直接的方式是增加时间刻度,通过增加时间刻度,我们可以基于更精细的时间单位(分钟)来进行定时任务的执行。但是,这种实现方式有如下的缺陷:
当我们刻度增多时,而任务相对较少,效率就会下降,假如我们只有以秒为刻度,一天 24 * 60 * 60 = 86400秒,我们可能只占用几十或几百个刻度,大部分时间刻度所占用的内存空间是没有任何意义的。
round时间轮算法
我们发现,时间轮的时间刻度随着时间精度而增加并不是一个好的问题解决思路。现在,我们将时间轮的精度设置为秒,时间刻度个数固定为 60。每一个任务拥有一个 round 字段。
轮询线程的执行逻辑是:每隔一秒处理一个时间刻度上任务队列中的所有任务,任务的 round 字段减 1,接着判断如果 round 字段的值变为 0,那么将任务移出任务队列,交给异步线程池来执行对应任务。如果是重复执行任务,那么再将任务添加到任务队列中。
轮询线程遍历一次时间轮需要 60 秒。如果一个任务需要间隔 x 秒执行一次,那么其 round 字段的值为 x/60(整除),任务位于第 (x%60)(取余)个刻度对应的任务队列中。例如任务需要间隔 130 秒执行一次,那么 round 字段的值为 2,此任务位于第 10 号时间刻度的任务队列中。
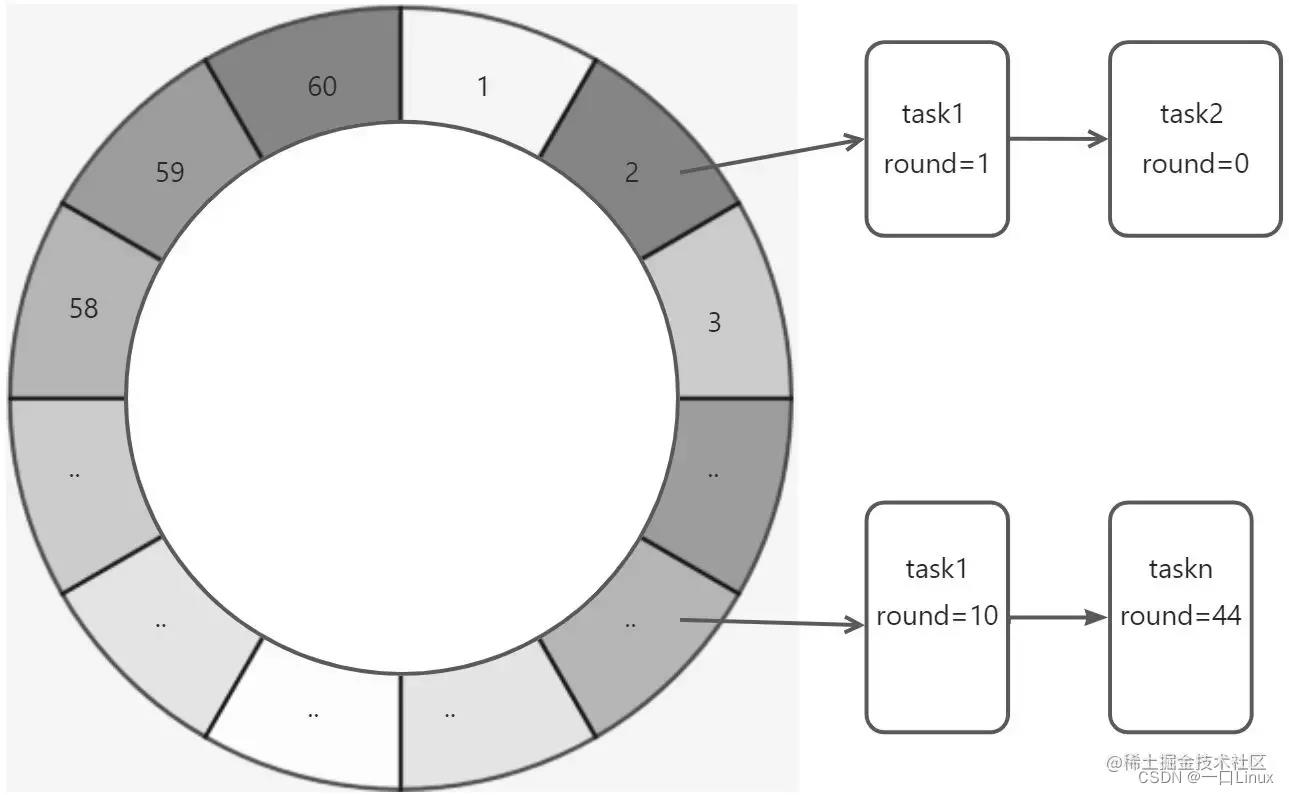
这种方式虽然简化了时间轮的刻度个数,但是并没有减少轮询次数,效率还是相对较低。时间轮每次处理一个时间刻度,就需要处理其上任务队列的所有任务。其运行效率甚至与基于普通任务队列实现的定时任务框架没有区别。
分层时间轮
分层的时间轮算法在生活中有对应的模型,那就是水表:

我们可以将一天类似水表一样,分为多个轮,时、分和秒三个级别的时间轮,每一个轮的刻度分别为24、60、60个刻度。分层时间轮如下:
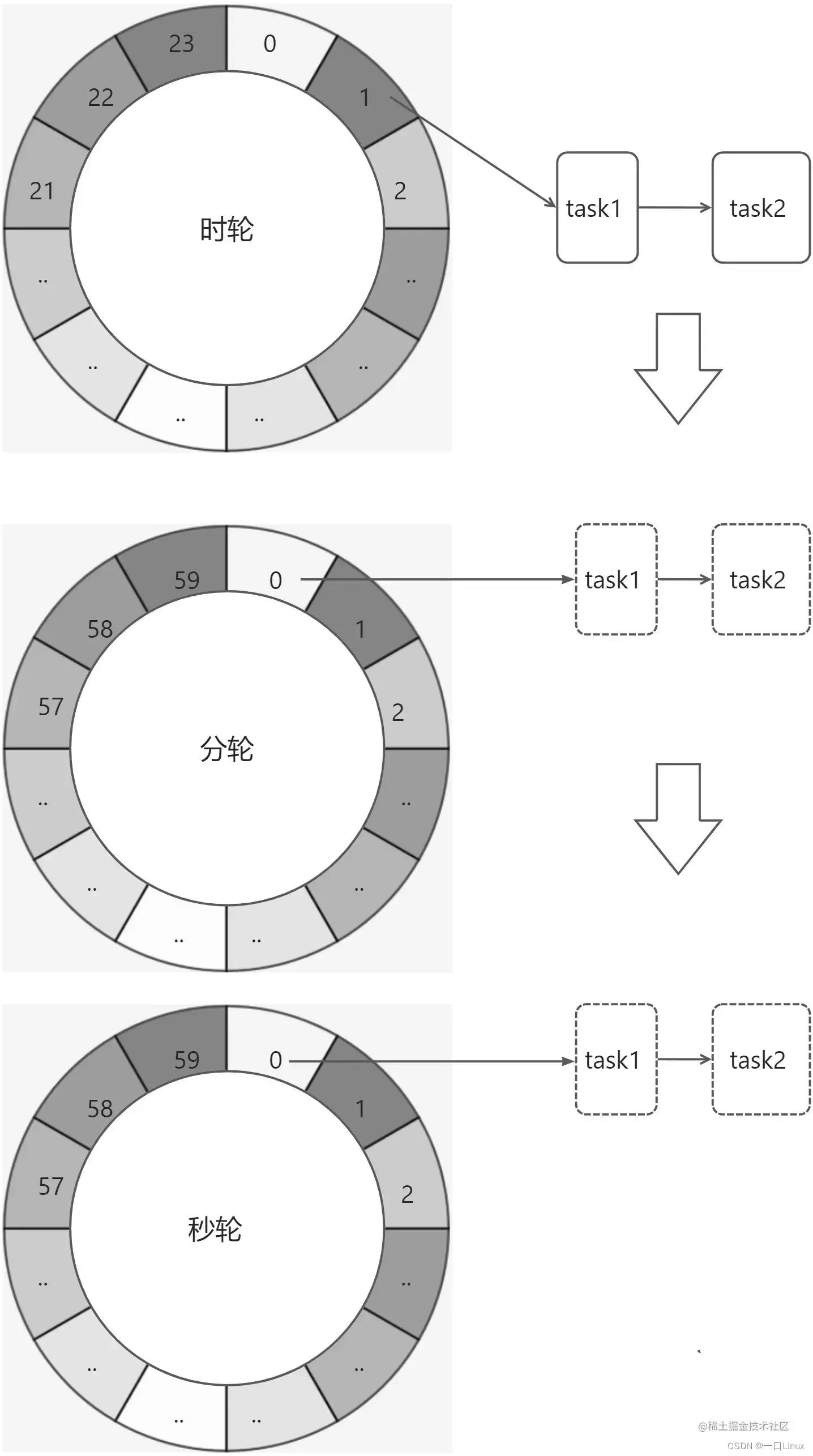
假设我们有2个任务是每天的1:00:00执行一次,任务首先添加到时轮第1刻度上,当时轮到达第1刻度时,任务转移到分轮上的第0刻度,当分轮达到第0刻度,任务转移到秒轮,当秒轮达到第0刻度,任务一次执行。
优点:
- 轮询效率变高:不需要计算round值,其次任务队列中的任务一旦被遍历,就是需要被处理的(没有空轮询问题);
- 线程并发好:虽然引入了并发线程,但是线程数仅仅和时钟轮的级数有关,并不会随着任务的增长而变多
分层时间轮的任务从一个时间轮转移到另一个时间轮,有点像水表中小单位的表转一圈进位到大单位一样(但是分层时间轮是从大到小,因为从小到大的话,小单位的表轮询判断次数过多)
应用:
时间轮的使用在各大框架与中间件中有使用,xxl-job,netty都对时间轮都自己的实现。思路基本上与分层的时间轮策略一致。
以上是关于定时器实现原理——时间轮的主要内容,如果未能解决你的问题,请参考以下文章