提取内容摘要
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了提取内容摘要相关的知识,希望对你有一定的参考价值。
本篇文章主要介绍文章摘要提取的方法,将从抽取式摘要提取和生成式摘要提取两种思路介绍。
一,背景介绍
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。
自动摘要(Automatic Summarization)的方法主要有两种:
- Extraction 是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;
- Abstraction 是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。
- 由于自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。抽取式摘要成为现阶段主流,它也能在很大程度上满足人们对摘要的需求。
二,抽取式摘要提取
抽取式的方法基于一个假设,一篇文档的核心思想可以用文档中的某一句或几句话来概括。那么摘要的任务就变成了找到文档中最重要的几句话,也就是一个排序的问题。怎么排序有很多方法:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用 LDA,HMM
- 基于线路规划:将摘要问题转为线路规划,求全局最优解。
本篇文章主要介绍基于图模型的方法-TextRank。其他方法可以参考:使用Python自动提取内容摘要
1,TextRank架构介绍:
基本思想就是利用文本句子之间的相似度构建图结构,在使用谷歌的 PageRank 算法对句子进行排序。
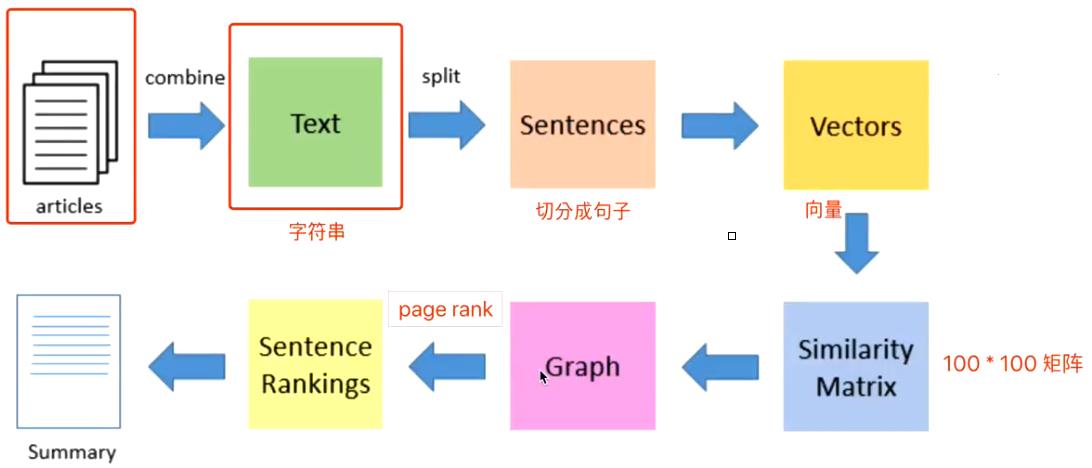
a.预处理:分句
将拿到的文本做分句,这里有两种可能性,一是用句点或者其他可以表达一句话结尾的符号作为分隔,另外一种是用逗号作为分隔符获取句子。
b.句向量:向量化
句子向量化有很多方式了,这里就不展开介绍。包括Bag Of Words、TFIDF、LDA/LSI、SIF模型、自编码方式训练、以及最近的BERT、skip-thought模型等。
c.句子的相似矩阵
n个句子得到n*n大小的相似矩阵。
d.排序
利用相似矩阵构建句子的图结构,并运行PageRank算法排序。如果不了解PageRank算法,可以简单理解为一个排序算法,比如google如何从众多的网页中选出重要的网页展现。
e.输出
- 重新排序:排序之后的结果只考虑了相关性并没有考虑新颖性,非常有可能出现排名靠前的几句话表达的都是相似的意思。所以需要引入一个惩罚因子,将新颖性考虑进去。对所有的句子重新打分,如下公式:
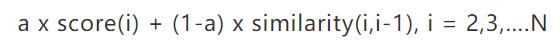
序号i表示排序后的顺序,从第二句开始,排第一的句子不需要重新计算,后面的句子必须被和前一句的相似度进行惩罚。 - 输出:摘要一般是取排序后的前N句话,但是,因为各个句子都是从不同的段落中选择出来的,如果只是生硬地连起来生成摘要的话,很难保证句子之间的衔接和连贯。保证可读性是一件很难的事情。(常用方法:将排序之后的句子按照原文中的顺序输出,可以在一定程度下保证一点点连贯性。)
2,语料
a.DUC
这个网站提供了文本摘要的比赛,2001-2007年在这个网站,2008年开始换到这个网站TAC。这里提供的数据集都是小型数据集,用来评测模型的。
b.Gigaword
该语料非常大,大概有950w篇新闻文章,数据集用headline来做summary,即输出文本,用first sentence来做input,即输入文本,属于单句摘要的数据集。
c.CNN/Daily Mail
该语料就是我们在机器阅读理解中用到的语料,该数据集属于多句摘要。
d.Large Scale Chinese Short Text Summarization Dataset(LCSTS)
这是一个中文短文本摘要数据集,数据采集自新浪微博。
三,生成式摘要
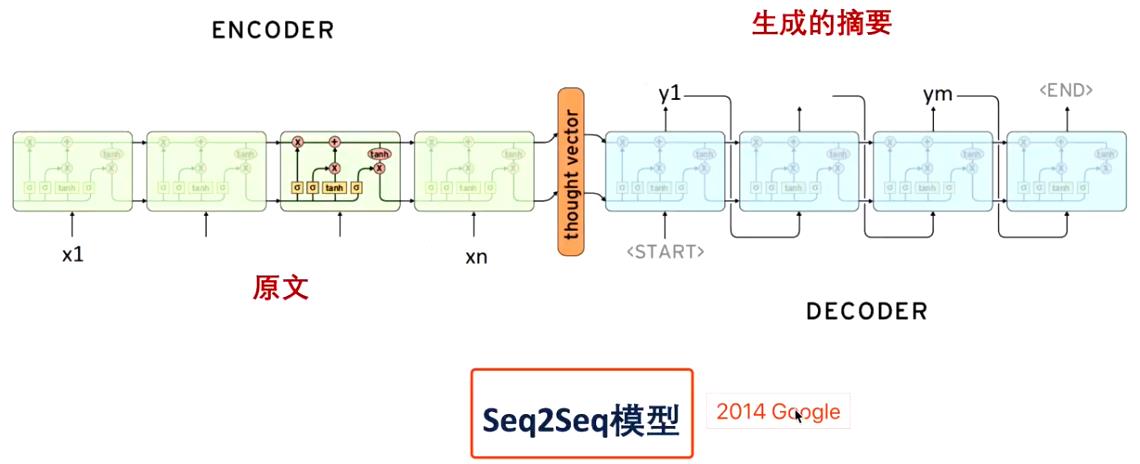
到这里本篇文章的主要内容就完了,这部分主要是想补充一下摘要的生成式方法。目前为止生成方法大都是基于seq2seq模型进行改进的,一般也会利用attention机制。下图展现的是一般的seq2seq模型,更多的生成式改进模型参考:自动摘要综述
以上是关于提取内容摘要的主要内容,如果未能解决你的问题,请参考以下文章