排序算法(02)— 快速排序算法
Posted 崔小花o
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序算法(02)— 快速排序算法相关的知识,希望对你有一定的参考价值。
快速排序算法
一、概述
快速排序(Quick Sort)是由东尼·霍尔(Tony Hoare)所发展的一种排序算法。他在形式化方法理论以及ALGOL60编程语言的发明中都有卓越的贡献。
二、算法思想
2.1 基本思想
快速排序的基本思想是:通过一趟排序,将待排记录分隔成独立的两部分,其中一部分的记录的关键字总是比另一部分记录的关键字小,则可以分别对这两部分记录继续进行排序,直到整个序列有序。
2.2 算法步骤
快速排序使用分治法Divide and conquer策略来把一个串行list分为两个子串行sub-lists。
- 从数列中挑出一个元素,称为 “基准”(pivot)
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
如下图所示:
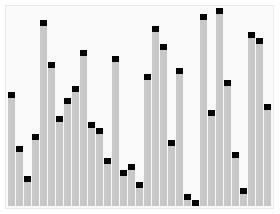
三、代码实现
3.1 排序用到的数据结构和函数
3.1.1 数据结构
为了讲清楚排序算法的代码,我们就先提供一个用于排序的顺序表结构,以后的排序算法也会用到这个结构
#define MAXSIZE 10 //用于要排序数组个数最大值,可根据需要修改
typedef struct
int r[MAXSIZE +1]; //用于存储要排序的数组,r[0]用于哨兵或临时变量
int length; //用于记录顺序表的长度
SqList;
3.1.2 交换函数
由于排序最常用到的函数就是数组交换,所以我们就把它单独提出来作为一个函数
/* 交换 L 中数组r的下标为 i 和 j 的值 */
void swap(SqList *L, int i, int j)
int temp = L->r[i];
L->r[i] = L->r[j];
L->r[j] = temp;
3.1.3 核心实现
假设对顺序表 L = 50,10,90,30,70,40,80,60,20 进行快速排序,只有一句代码,先不要急,我们慢慢来。
/* 对顺序表 L 进行快速排序 */
void QuickSort(SqList *L)
QSort(L, 1, L->length);
因为我们用到了递归调用,所以我们把核心代码做了一个封装,下面我们来看一下QSort的实现。
/* 对顺序表 L 中的子序列 L->r[low..high] 做快速排序 */
void QSort(SqList *L, int low, int high)
int pivot;
if (low < high)
// 找出中间值,根据中间值把列表分为两部分:前小后大
pivot = Partition(L, low, high); // 算出枢轴pivot,并返回
QSort(L, low, pivot - 1); // 对前半部分进行递归排序
QSort(L, pivot + 1, high); // 对后半部分进行递归排序
在上边的函数中,用到了一个非常关键的函数,这个函数可以算作是快速排序的灵魂代码,Partition函数要做的就是,选取一个关键字,比如 50,最终使得 L列表中,左边的数值都比他小,右边的数值都比他大,这样的关键字我们称之为枢轴pivot。
我们继续来看一下Partition函数
/* 交换顺序表 L 中子表的记录,使枢轴记录到位,并返回其坐在的位置 */
int Partition(SqList *L, int low, int high)
int pivotKey;
pivotKey = L->r[low]; // 用子表的第一个数据当做枢轴
while (low < high)
while (low < high && L->r[high] >= pivotKey)
high --;
swap(L, low, high);
while (low < high && L->r[low] <= pivotKey)
low ++;
swap(L, low, high);
return low;
3.1.4 步骤分解
以 L =50,10,90,30,70,40,80,60,20 为例,来分解一下Partition函数
第1次交换

第2次交换
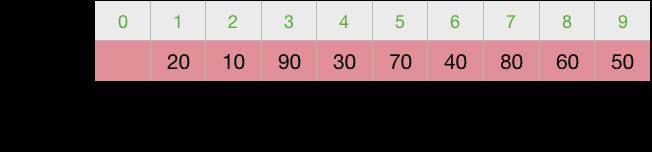
第3次交换
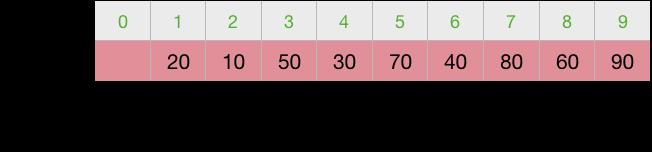
第4次交换
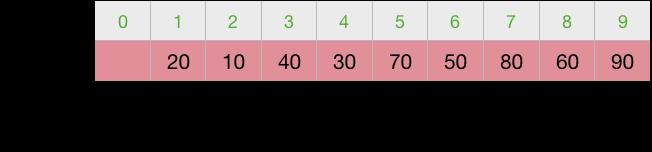
第5次交换
第6次交换
到现在第一遍的排序已经完成,QSort函数后边的递归就是分别对pivotkey 之前的数据20,10,40,30和pivotkey之后的数据70,80,60,90进行递归排序。不知道大家有没有看明白,Partition函数的作用就是,选取pivotkey 不断的变换,将比它小的换到左边,将比它大的换到它的右边,并且在交换中不断的改变自己的位置,直到完全满足这个要求为止。
四、时间复杂度分析
我们来分析一波快速排序算法的性能,快速排序算法的时间性能取决于快速排序递归的深度。
在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环inner loop可以在大部分的架构上很有效率地被实现出来。
然后再给大家讲一个知识点,由于关键字的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
参考文档
[1]严蔚敏、吴伟民. 数据结构(C语言版). 北京:清华大学出版社,1997
[2]程杰. 大话数据结构. 北京:清华大学出版社,2011
以上是关于排序算法(02)— 快速排序算法的主要内容,如果未能解决你的问题,请参考以下文章