英雄联盟数据分析专题
Posted Babyface Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英雄联盟数据分析专题相关的知识,希望对你有一定的参考价值。
写在前面的话

本次的主题是关于英雄联盟的Tribunal法庭系统国服也叫做议事大厅。英雄联盟议事大厅是为了解决骚扰投诉而设计的,让所有拥有资格的玩家去评估每个被投诉者的案子。英雄联盟议事大厅会提供每一位被举报玩家的相关数据,审判者需要对内容进行仔细的判断后,决定“惩戒”或“宽恕”被举报的玩家。(摘自英雄联盟国服官网)
在游戏中我们难免会遇到一些不太友好的玩家使用语言攻击对手或队友,而在结束游戏后针对言行过激的玩家大部分玩家都会使用举报系统进行举报。其中一些被举报的案例会统一交由参与议事大厅的玩家来投票决定对被举报采取何种处罚方式。本篇将使用的数据集正是这些有举报行为的对局中的聊天记录,虽然该数据集来自北美服务器,但我认为不同服务器玩家之间存在较大的共性,希望在阅读过本文后读者们对英雄联盟中的玩家行为有更深刻的理解同时也能规范自己在游戏中的言行来创造更好的游戏环境。
背景介绍
该数据集包含了超过一万场被举报对局的聊天记录,其中包含每场对局中十个玩家全部聊天记录。且该数据集中的字段也非常丰富,共有9个字段,分别为:
message: 聊天记录内容
association_to_offender: 与被举报人的关系,分为敌方,队友以及被举报人
time: 聊天记录发生时的游戏对局内时间
case_total_reports: 在该被举报人被提交到议事大厅之前共被举报次数
allied_report_count: 队友中举报该玩家人数
enemy_report_count: 对方中举报该玩家人数
most_common_report_reason: 在最近5次被举报对局中该玩家最常被举报原因
chatlog_id: 聊天记录对应ID(也可做为每场游戏对局的ID,相同游戏对局的每条聊天记录ID相同)
champion_name: 每条聊天记录对应的英雄名称
从上面的介绍中可以看到该数据集的信息量非常大,有了丰富的数据集我们就可以从不同的维度来进行分析。
探索性数据分析
#导入本文中所有需要的库
import pandas as pd
from nltk.tokenize import RegexpTokenizer
from collections import Counter
import operator
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import BernoulliNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
首先我们载入数据集并对数据集做一些基本的处理。
#载入数据集
data=pd.read_csv('chatlogs.csv')
data=data.iloc[:,1:]
#查找数据集中缺失值
data.isnull().sum()

从结果中可以看到message这一项有29个缺失值,association_to_offender中有104个缺失值, champion_name中有104个缺失值。因为我们关心的是被举报人的聊天记录所以association_to_offender这一项的缺失值对数据分析的影响最大,要先对该字段中的缺失值进行处理。在后面对数据集的应用中会针对每种情况对不同缺失值做相应的处理。
#删除缺失值
data['association_to_offender'].dropna(inplace=True)
#打印数据框前十条记录
data.head(10)
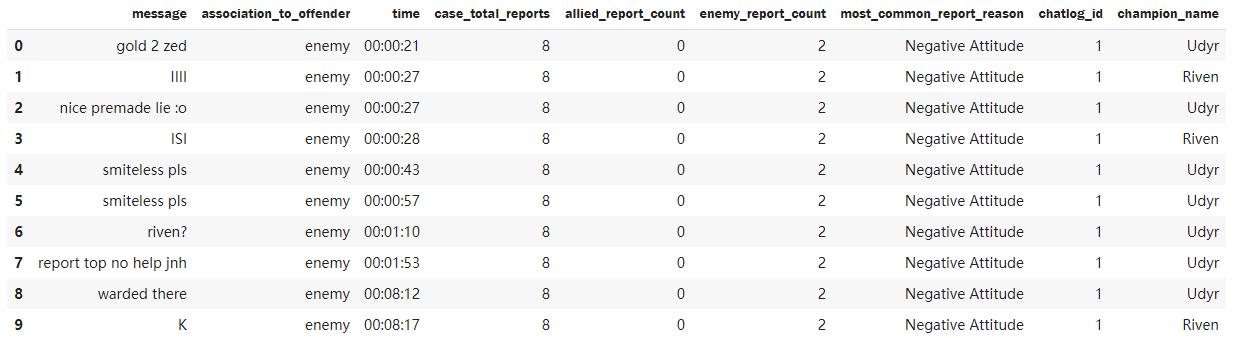
#打印总游戏对局数
print('Number of chatlogs: '.format((data['chatlog_id'].nunique())))
#打印总聊天记录数
print('Number of records: '.format(data.shape[0]))


该数据集中共包含10058场游戏对局其中有近170万条聊天记录。到这里读者应该就对我们的数据集有了一个大致的了解。
因为我们拿到该数据集,最感兴趣的还是被举报玩家的行为,所以我们首先要把被举报玩家的聊天记录单独提取出来。然后我首先想到的一个问题就是使用哪些英雄的玩家被举报的次数更多呢?
#把被举报玩家的聊天记录提取出来
offender_df=data[data['association_to_offender']=='offender']
#计算每个英雄被举报的次数
champion_counts=offender_df.groupby('champion_name')['chatlog_id'].nunique()
champion_counts=pd.DataFrame(champion_counts)
#对结果进行降序排列
champion_counts=champion_counts.sort_values(by='chatlog_id',ascending=False)
#打印排名前五的英雄和被举报次数
print('5 most offensive champions:')
print(champion_counts.iloc[:5,:])
#打印排名最后五名的英雄和被举报次数
print('5 least offensive champions:')
print(champion_counts.iloc[-5:,:])

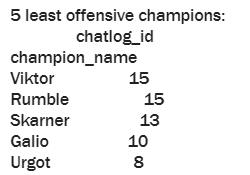
通过结果可以看出,最常被举报的英雄为盲僧,薇恩,伊泽瑞尔,锐雯和女警而最不常被举报的英雄为维克托,兰博,蝎子,加里奥和厄加特。但是英雄联盟的老玩家可能会发现英雄被举报的次数似乎和英雄本身的热度有关,也就是说热门的,人人都喜欢玩的英雄就会有更高的被举报次数而一些比较冷门的英雄相对被举报的次数就会变得很低。而且该数据集仅使用了约一万场游戏来进行分析,所以具有一定的局限性和时效性。但是该结果也能说明一些问题,被举报次数最多的前五名英雄都是一些操作上限较高的英雄,而相对应的使用这些英雄的玩家就有更高的可能因为队友或对手的一些失误而攻击他们。
下面我们再来看看使用哪些英雄的玩家是话痨大王。
#计算每个英雄对应的聊天记录数
chat_counts=offender_df.groupby('champion_name')['chatlog_id'].count()
chat_counts=pd.DataFrame(chat_counts)
#对结果进行降序排列
chat_counts=chat_counts.sort_values(by='chatlog_id',ascending=False)
#打印最话痨的五个英雄
print('5 most talktive offenders:')
print(chat_counts.iloc[:5,:])
#打印话最少的五个英雄
print('5 least talktive offenders:')
print(chat_counts.iloc[-5:,:])


这个结果和之前的排序稍有变动但英雄一致,在这里排序同样受之前所提到的因素影响。但是值得注意的是,被举报的盲僧玩家的聊天记录数几乎比第二名的薇恩玩家多出了3000条。我对国服的玩家不太了解但具我对美服玩家的了解这一结果还是很具有代表性的。这说明盲僧玩家不仅敢打敢操作而且在和队友互动上也不落下风。
下面我们对被举报玩家的聊天记录内容来做分析。我很想知道那些被举报的玩家最常说的词是什么,也许就是这些词导致了这些玩家被举报。
#把message, chatlog_id, champion_name三个字段单独提取出来做分析
offender_message_df=offender_df.loc[:,['message','chatlog_id','champion_name']].reset_index()
offender_message_df=offender_message_df.iloc[:,1:]
#删除缺失值
offender_message_df.dropna(inplace=True)
#自定义一个函数
#该函数可输出出现次数最多的k个词
def getTopK(df, kwords, operation=operator.eq):
counter = Counter()
stop = set(stopwords.words('english'))
messages=df['message'].values
for message in messages:
counter.update([word.lower()
for word
in re.findall(r'\\w+', message)
if word not in stop and len(word) > 2])
topk = counter.most_common(kwords)
return topk
#打印出被举报玩家聊天记录中出现频率最高的20个词
getTopK(offender_message_df, 20)

由于在自定义函数中已经删去了停用词所以结果中出现的词都是具有一定代表性的有实际意义的词。出现频率最高的两个词’report’ 和 ‘noob’是美服中非常具有代表性的两个词。‘report’一般出现在当一名玩家对自己的队友表现不满意的时候就会发动队友和对方来举报自己的这名队友,而’noob’这个词是本来是菜鸟的意思但在美服英雄联盟玩家的’口‘中这个词的程度还要比菜鸟更深,有点类似于国服中经常指责队友菜时出现的词语,读者可以自行脑补。而且这个结果中还有一个非常有意思的一点就是’mid’, ‘bot’, 'top’这三个单词,出现的次数相差不大而且排列在一起,这是不是说明打野玩家指责队友的概率更大呢?
对整体的情况做了分析之后我突然想到如果对被举报次数最多和最少的英雄分别做以上分析,会不会发现一些有趣的东西呢?
#提取出被举报的盲僧玩家的聊天记录
leesin_message_df=offender_message_df[offender_message_df['champion_name']=='Lee Sin']
#打印出前十个最常出现的词语
getTopK(leesin_message_df, 10)

#提取出被举报的兰博玩家的聊天记录
rumble_message_df=offender_message_df[offender_message_df['champion_name']=='Rumble']
#打印出前十个最常出现的词语
getTopK(rumble_message_df, 10)

通过对上面两个结果的比较我们可以发现,被举报的盲僧玩家最常使用的词语和整体结果非常类似而被举报的兰博玩家因为样本量较少所以和整体结果还是有一定的差异性。但是这个结果是不是也从侧面说明了被举报的盲僧玩家对于所有被举报的玩家来说是一群非常有代表性的样本呢?
数据建模
在这一部分我的想法是既然被举报的玩家使用的词语有高度的相似性,那么能不能通过分类器来把被举报玩家和普通玩家分类开呢?同时为了使本篇文章增添一点知识性我决定使用两种分类模型:逻辑回归分类器和朴素贝叶斯分类器,来比较两种分类器的表现。
#把与分类有关的字段提取出来
classification_df=data.loc[:,['message','association_to_offender','chatlog_id']]
#删除缺失值
classification_df.dropna(inplace=True)
#定义一个转换函数
#把association_to_offender这一字段中的offender转换为1其他类型转换为0
#这样就得到了二元分类的目标值
def transfer(x):
if x == 'enemy':
x=0
elif x == 'ally':
x=0
else:
x=1
return x
#对association_to_offender这一字段进行转换并把转换后的值填入class字段
classification_df['class']=classification_df['association_to_offender'].apply(transfer)
#打印转换后的数据框
classification_df.head()

下面我们要对字符串数据进行预处理并且把每场游戏中class为0或class为1的字符串合并在一起.
#定义分词器
tokenizer=RegexpTokenizer(r'\\w+')
#对message字段中的字符串进行分词
word_list=[tokenizer.tokenize(x) for x in classification_df['message']]
#对分词后的单词进行小写转换
for i in range(0,len(word_list)):
word_list[i]=[word.lower() for word in word_list[i]]
#把转换后的词合并在一起
for i in range(0,len(word_list)):
word_list[i] = ' '.join([str(word) for word in word_list[i]])
classification_df['message']=word_list
#对同一场对局的同一个class的字符串进行聚合
processed_classification_df=classification_df.groupby(['chatlog_id','class'],as_index=False).agg('message': ' '.join)
#打印处理后的数据框
processed_classification_df.head()

可以看到经过处理后的数据框中,同一场对局中非被举报玩家的聊天记录与被举报玩家的聊天记录已经分别合并在一起,也就是说现在数据集中50%为普通玩家的聊天记录,50%为被举报玩家的聊天记录。
在使用分类模型之前,要对字符串进行转换,对文本数据转换的方法有很多,本文为了简便使用的是sklearn中自带的TF-IDF转换器,并使用sklearn中的LogisticRegression和BernoulliNB来进行分类。
corpus=processed_classification_df['message']
vectorizer=TfidfVectorizer(lowercase=True,max_features=200,stop_words='english')
#转换后的聊天记录数据为X
X=vectorizer.fit_transform(corpus)
#目标值class为y
y=processed_classification_df['class']
#把数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
train_accuracy_list=[]
test_accuracy_list=[]
C_value_list=[]
#遍历逻辑回归分类不同超参数C的取值
for C in range(1,11):
C_value=C/10
C_value_list.append(C_value)
clf = LogisticRegression(C=C_value).fit(X_train, y_train)
y_train_predict = clf.predict(X_train)
y_test_predict = clf.predict(X_test)
train_accuracy = accuracy_score(y_train, y_train_predict)
test_accuracy = accuracy_score(y_test, y_test_predict)
train_accuracy_list.append(train_accuracy)
test_accuracy_list.append(test_accuracy)
#绘制不同超参数C对应的训练集和测试集准确率曲线
plt.plot(C_value_list,train_accuracy_list,label='Training Accuracy')
plt.plot(C_value_list,test_accuracy_list,label='Testing Accuracy')
plt.legend()
plt.xlabel('C value')
plt.ylabel('Accuracy')
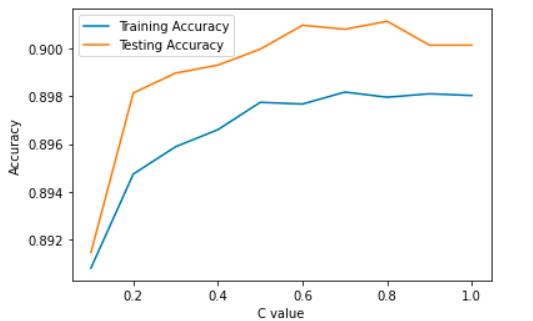
从这个结果可以看到,逻辑回归分类器对于这个问题的表现还是很不错的。测试集和训练集的准确率都在90%左右且二者相差不大,说明没有过拟合的问题,使用逻辑回归来分辨被举报者和普通玩家是完全可行的。那下面我们再来看看使用朴素贝叶斯分类器的效果。
clf = BernoulliNB().fit(X_train, y_train)
y_train_predict = clf.predict(X_train)
y_test_predict = clf.predict(X_test)
train_accuracy = accuracy_score(y_train, y_train_predict)
test_accuracy = accuracy_score(y_test, y_test_predict)
print('Training accuracy of Naive Bayes: '.format(train_accuracy))
print('Testing accuracy of Naive Bayes: '.format(test_accuracy))


可以看到使用朴素贝叶斯分类器时,准确率与逻辑回归分类器相比稍差,其原因是朴素贝叶斯分类器的必要假设为特征之间是条件性独立的关系,在本数据集中就表现为假设转换后的TF-IDF数据框中每个单词的出现与其他单词无关,显然该假设对于大多数的文本类型数据都是不成立的,但在大多数情况下朴素贝叶斯分类器依然可以有很好的表现。但对于一些比较复杂且特征之间存在强关联性的分类问题,使用朴素贝叶斯分类器并不是一个很好的选择。
写在最后的话
本文为作者看到数据集后临时起意,因此文中难免出现疏漏,希望各位读者可以及时指出
若各位读者对于本文内容有好的想法和建议可以与我交流
希望各位可以对本篇提出宝贵意见
转载请注明出处
以上是关于英雄联盟数据分析专题的主要内容,如果未能解决你的问题,请参考以下文章