Spark2.1.0安装和配置
Posted 会编程的李较瘦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.1.0安装和配置相关的知识,希望对你有一定的参考价值。
一、scala的安装与配置
1.scala的下载
下载地址为:scala下载地址
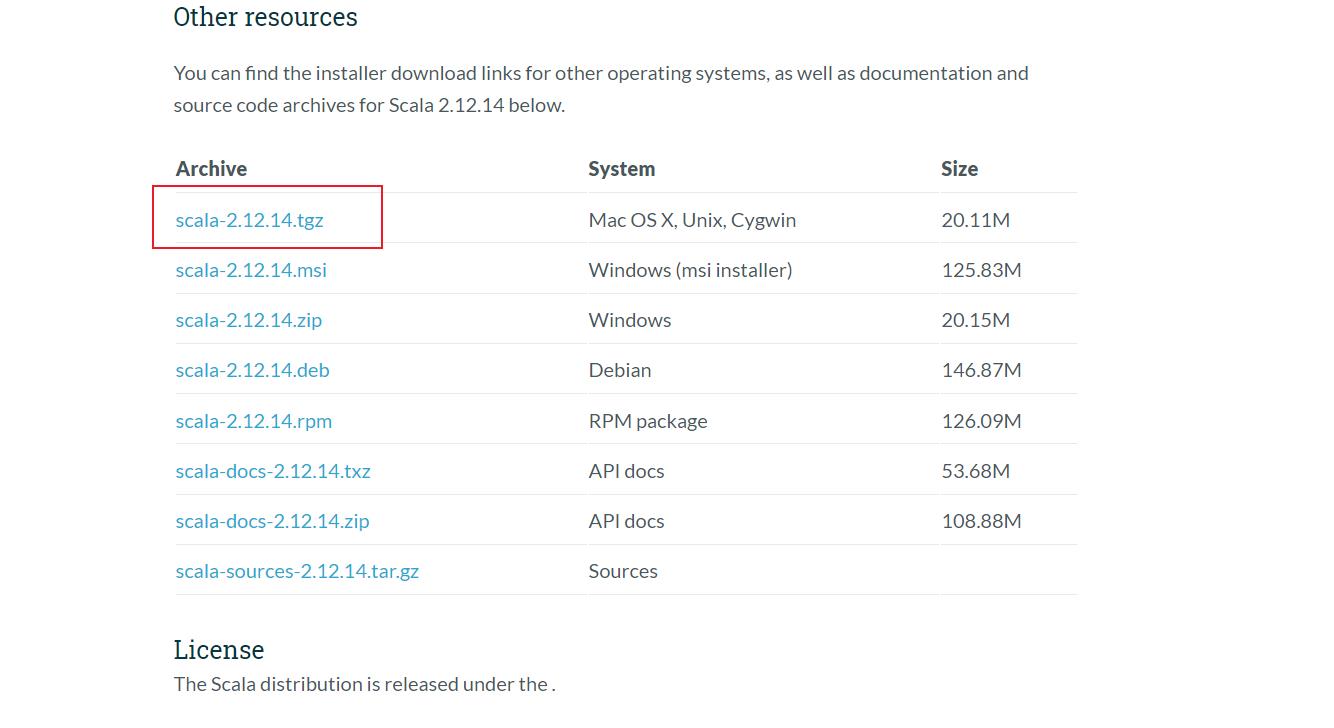
2.scala的安装与配置
(1)安装包的解压
tar -zxvf scala-2.12.14.tgz
mv scala-2.12.14 /export/software/
(2)环境变量的配置
在命令行中输入如下命令,打开profile配置文件
vi /etc/profile
打开profile文件后在文件末尾加入如下配置语句:

然后再命令行中输入source/etc/profile使环境变量生效。
在命令行输入scala,能进入scala命令行说明安装成功.
 注意!:退出Scala的命令为 :quit
注意!:退出Scala的命令为 :quit
二、spark的安装与配置
1.spark的下载
下载地址为:spark下载地址
下载对应的Hadoop版本的spark,这里我的Hadoop版本为
2.4.1,因此如图选择对应的版本。

2.spark的安装与配置
和Scala的安装与配置一样,先进行解压,然后打开profie文件配置环境变量。
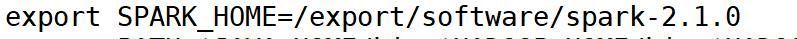
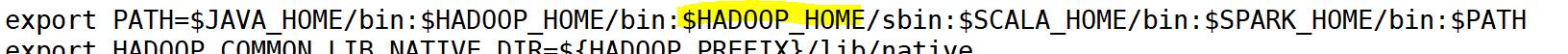
export SPARK_COMMON_LIB_NATIVE_DIR=$SPARK_HOME/lib/native
export SPARK_OPTS="-Djava.library.path=$SPARK_HOME/lib"
3.配置conf/spark-env.sh 文件

进入到conf目录下会发现spark-env.sh为临时文件,须重命名为spark-env.sh
执行如下命令:
mv spark-env.sh.template spark-env.sh

在文件中加入如下内容:
export SCALA_HOME=/export/software/scala-2.12.14
export JAVA_HOME=/export/software/jdk1.8.0_161
export HADOOP_HOME=/export/software/hadoop-2.4.1
export SPARK_WORKING_MEMORY=2g
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export HADOOP_CONF_DIR=/export/software/hadoop-2.4.1/etc/hadoop
参数解释:
- SPARK_WORK_MEMORY 决定在每一个Worker节点上可用的最大内存,增加这个数可以在内存中缓存更多数据,但一定要给Slave的操作系统和其他服务预留足够内存
- SPARK_MASTER_IP 参数可以是具体的IP地址也可以是hostname,系统会更具hosts文件进行解析
- MASTER_PORT 配置端口号
- HADOOP_CONF_DIR指定HDFS配置文件目录,从而整合Spark与HDFS
PS:SPARK_MASTER_IP和MASTER必须配置否则会造成Slave无法注册主机错误
配置conf/slaves 文件 将节点的主机名加入到slaves文件中
slave1
slave2
4.启动Spark集群
在启动前,将scala文件、spark文件以及etc目录下的profile文件传给slave1和slave2,并在slave1和slave2命令行中输入source/etc/profile使环境变量生效
进入spark目录下,输入如下命令:
sbin/start-all.sh

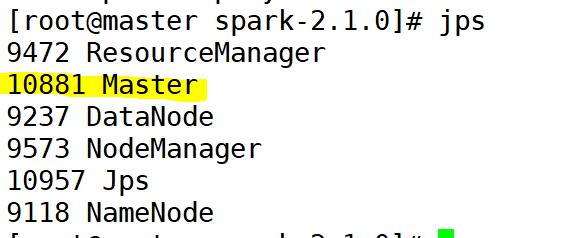
如上图所示说明启动成功,这时候分别在三个节点上通过jps查看进程,则如下图所示:
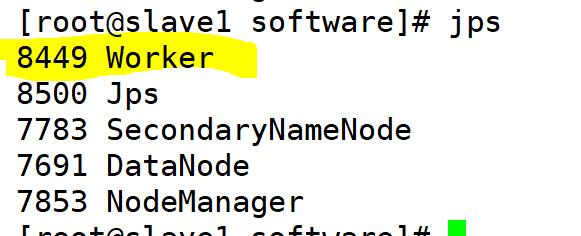
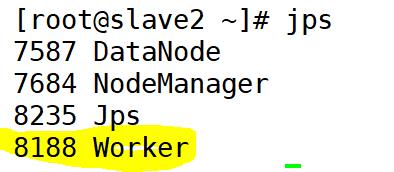
至此spark的安装结束,也已成功启动,如需停止,输入如下命令:
sbin/stop-all.sh
5.浏览Web页面
启动成功后,通过浏览器访问:192.168.233.131:8080来查看集群状态。
!!解决spark无法查看web页面状态
查看主机master的日志文件(/root/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out)

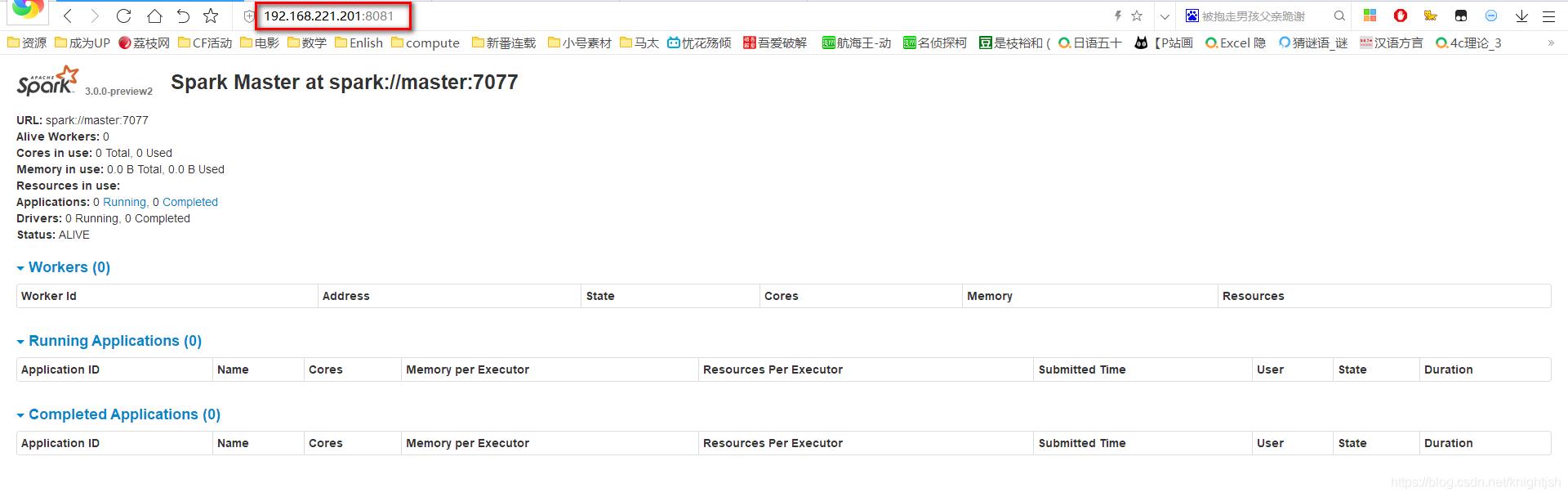
仔细查看日志发现,端口似乎发生了变动(在WARN中),具体为什么会这样,希望有大神指点【博主还是小白】。看最后一行MasterWebUI,发现这不是访问web页面的有关信息吗?很明显是需要你使用 http://IP地址:8081 来访问。
然后我使用8081端口,果然成功了!!!
以上是关于Spark2.1.0安装和配置的主要内容,如果未能解决你的问题,请参考以下文章
CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装