ML Metadata:ML 的版本控制
Posted TensorFlow 社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML Metadata:ML 的版本控制相关的知识,希望对你有一定的参考价值。

文 / Ben Mathes 和 Neoklis Polyzotis,代表 TFX 团队发布
在编写代码时,您需要追踪代码进行追踪版本控制。那么 ML 的版本控制是什么?如果您正在构建生产 ML 系统,您需要能够回答如下问题:
-
模型是基于哪个数据集进行训练的?
-
使用了哪些超参数?
-
创建此模型时,使用了哪个流水线?
-
创建此模型时,使用了哪个版本的 TensorFlow(和其他库)?
-
是什么导致了此模型失败?
-
上次部署的模型版本是什么?
Google 工程师从多年来之不易的经验中得出,ML 工件的历史与继承关系要远比简单的线性日志复杂。您可以使用 Git(或类似工具)追踪代码;您还需要使用一些工具来追踪模型、数据集等。虽然 Git 可以在很大程度上简化一些工作,但归根结底,您仍需要一个包含了许多内容的图表!由于 ML 代码和工件(如模型、数据集等)的复杂性,您需要采用一种类似的方法。
因此,我们构建了 Machine Learning Metadata (MLMD)。MLMD 库可用于追踪整个 ML 工作流的完整继承关系。完整继承关系是指数据提取、数据预处理、验证、训练、评估、部署等流程中的所有步骤。MLMD 是一个可独立运行的库,但也集成到了 TensorFlow Extended 中。
-
MLMD
https://tensorflow.google.cn/tfx/tutorials/mlmd/mlmd_tutorial -
TensorFlow Extended
https://tensorflow.google.cn/tfx/guide/mlmd
现在,我们还提供了一个演示 Notebook,可帮助您了解如何将 MLMD 集成到 ML 基础架构中。
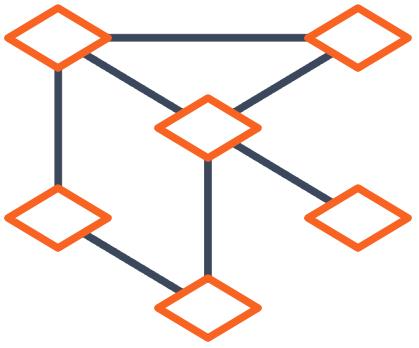
除了对您的模型进行版本控制外,ML Metadata 还会捕获训练流程的完整继承关系,其中包括数据集、超参数和软件依赖关系
以下是 MLMD 可以为您提供的帮助:
-
如果您是一名 ML 工程师:您可以使用 MLMD 从不良模型追溯到其数据集,或从不良数据集追溯到您基于此数据集训练的模型等。
-
如果您正在使用 ML 基础架构:您可以使用 MLMD 记录流水线的当前状态并进行基于事件的编排。您也可以用其进行优化,例如,在输入与代码相同时选择跳过步骤、记忆流水线中的步骤等。您可以将 MLMD 集成到训练系统,以便其为稍后的查询自动创建日志。我们发现,将自动记录完整继承关系作为训练附带的结果是使用 MLMD 的最佳方式。这样,您无需进行任何额外工作便可获得完整的历史记录。
MLMD 不仅仅是 TFX 的研究项目,还是 Google 中多个内部 MLOps 解决方案的重要基础。此外,Google Cloud 还将 MLMD 等工具与其核心 MLOps 平台进行了集成:
所有这些新服务的基础便是 AI Platform 中的全新 ML Metadata Management 服务。此服务支持 AI 团队追踪所有重要工件和所进行的实验,并会提供一份精心整理的操作记录和详细的模型继承关系。还支持客户根据 AI Platform 上训练的模型确定模型的来源信息,从而对其进行调试、审计或协作。AI Platform Pipelines 将自动追踪工件和继承关系,同时 AI 团队也可以将 ML Metadata 服务直接用于自定义工作负载、工件和元数据追踪。
-
核心 MLOps 平台
https://cloud.google.com/blog/products/ai-machine-learning/key-requirements-for-an-mlops-foundation
想要了解你模型的来源?使用了哪些训练数据?是否有其他人已基于此数据集训练模型?他们得到的性能是否更好?是否有任何需要清理的污染数据集?
如果您想要为用户解答这些问题,请访问 GitHub(其上的代码是 TensorFlow Extended 的一部分)或是我们的演示 Notebook 查看 MLMD。
-
TensorFlow Extended
https://tensorflow.google.cn/tfx/guide/mlmd -
Notebook
https://tensorflow.google.cn/tfx/tutorials/mlmd/mlmd_tutorial
想了解 TensorFlow 更多资讯,请访问 TensorFlow 中国官网:tensorflow.google.cn
或扫描下方二维码,关注 TensorFlow 官方微信公众号!
以上是关于ML Metadata:ML 的版本控制的主要内容,如果未能解决你的问题,请参考以下文章