WeLM简介及微信公众号开发
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WeLM简介及微信公众号开发相关的知识,希望对你有一定的参考价值。
前言
我的公众号后台设置了关键词自动回复,但是经常收到很多读者打错别字,导致无法触发,正巧,前段时间刚申请到WeLM的使用权限,于是就想着给公众号升级一下。
WeLM简介
WeLM是腾讯开发的一个擅长理解和生成文本的通用语言模型。
官方文档:https://welm.weixin.qq.com/docs/tutorial/
主要功能如下,输入示例内容即可获得答案
阅读理解
示例:
阅读文章:
“经审理查明,被告人张××、杜×、杨2某均为辽宁省辽阳第一监狱五监区服刑人员。2015年11月3日13时许,被告人张××、杜×因无事便跟随去催要生产材料的被告人杨2某一同前往六监区,在六监区生产车间门外,被告人杨2某与六监区送料员于×因送料问题发生争执,被告人杨2某上前拽住被害人于×胳膊并用手击打被害人后脖颈两下,被告人张××、杜×见杨2某动手后,先后上前分别对被害人于×面部、头部及腹部进行殴打,后被赶到的干警制止。被害人于×被打造成面部受伤,鼻子流血,当日下午14时许,到监区内医院就诊,诊断为:鼻部中段向左侧畸形,11月5日经监狱医院X光诊断为鼻骨骨折。2015年11月18日,经辽阳襄平法医司法鉴定所法医鉴定:被害人于×身体损伤程度为轻伤二级。被告人张××、杜×、杨2某共同赔偿被害人于×人民币7000元,被害人于×对被告人的行为表示谅解。”
问题: “被害人于×11月5日经监狱医院X光诊断后的诊断结果为?”
答案:
开放域问答
示例:
请根据所学知识回答下面这个问题
问题:百年孤独的作者是?
回答:加西亚·马尔克斯
问题:二战转折点是?
回答:
文本分类
示例:
判断这条微博的情感是积极的还是消极的
微博:本命年的第一天就把马桶给弄堵了,[泪]添堵
类别:消极
微博:华丽丽闪瞎眼啊![爱你]
类别:积极
微博:很有娱乐精神[嘻嘻]
类别:
文本风格转换
示例:
有这样一段文本,医生微笑着递给小明棒棒糖,同时让小明服下了药。
改写这段话让它变得更加惊悚。医生眼露凶光让小明服药,小明感到非常害怕。
有这样一段文本,雨下得很大
改写这段话让它变得更加具体。一霎时,雨点连成了线,大雨就像天塌了似的铺天盖地从空中倾泻下来。。
有这样一段文本,王老师离开了电影院,外面已经天黑了
改写这段话让它包含更多电影信息。这部电影比小王预想的时间要长,虽然口碑很好,但离开电影院时,小王还是有些失望。
有这样一段文本,男人站在超市外面打电话
改写这段话来描述小丑。男人站在马戏团外一边拿着气球一边打电话
有这样一段文本,风铃声响起
改写这段话写的更加丰富。我对这个风铃的感情是由它的铃声引起的。每当风吹来时,风铃发出非常动听的声音,听起来是那么乐观、豁达,像一个小女孩格格的笑声。
有这样一段文本,我想家了
改写这段话包含更多悲伤的感情。
个性对话生成
示例:
李⽩,字太⽩,号⻘莲居⼠,⼜号“谪仙⼈”,唐代伟⼤的浪漫主义
诗⼈,被后⼈誉为“诗仙”。
我:今天我们穿越时空连线李⽩,请问李⽩你爱喝酒吗?
李⽩:当然。花间⼀壶酒,独酌⽆相亲。举杯邀明⽉,对影成三⼈。
我:你觉得杜甫怎么样?
李⽩:他很仰慕我,但他有属于⾃⼰的⻛采。
我:你为何能如此逍遥?
李⽩:天⽣我材必有⽤,千⾦散尽还复来!
我:你都去过哪些地方?
李白:
翻译
示例:
“微信 AI 推出の WeLM 是一个 language model that いろいろなtaskをperformができる”的中文翻译是:
写作或文本续写
示例:
中国地大物博,自然⻛光秀丽,大自然的⻤斧神工造就了许多动人心魄的美景,
总之,尽量输入一些样例,否则语料过短很难输出好结果。
调用接口
WeLM调用接口如下:
curl -H 'Content-Type: application/json' -H 'Authorization: Bearer your_api_token' https://welm.weixin.qq.com/v1/completions -d \\
'
"prompt":"测试",
"model":"xl",
"max_tokens":16,
"temperature":0.0,
"top_p":0.0,
"top_k":10,
"n":1,
"echo":false,
"stop":",,.。"
'
参数含义:
- model: string 必选,要使用的模型名称,当前支持的模型名称有medium、 large 和 xl
- prompt: string 可选,默认值空字符串,给模型的提示
- max_tokens: integer 可选,最多生成的token个数,默认值 16
- temperature: number 可选 默认值 0.85,表示使用的sampling temperature,更高的temperature意味着模型具备更多的可能性。对于更有创造性的应用,可以尝试0.85以上,而对于有明确答案的应用,可以尝试0(argmax采样)。 建议改变这个值或top_p,但不要同时改变。
- top_p: number 可选 默认值 0.95,来源于nucleus sampling,采用的是累计概率的方式。即从累计概率超过某一个阈值p的词汇中进行采样,所以0.1意味着只考虑由前10%累计概率组成的词汇。 建议改变这个值或temperature,但不要同时改变。
- top_k: integer 可选 默认值50,从概率分布中依据概率最大选择k个单词,建议不要过小导致模型能选择的词汇少。
- n: integer 可选 默认值 1 返回的序列的个数
- echo: boolean 可选 默认值false,是否返回prompt
- stop: string 可选 默认值 null,停止符号
返回状态码含义:
- 超时:504
- 服务不可用:503
- 用户prompt命中敏感词:400, finish_reason: “error: content policy violation”
- 生成结果命中敏感词:200, finish_reason: “error: internal error”
- 用户输入参数不合法:400, finish_reason返回原因
- 配额超限制:429, response body: “quota limit exceed”
- 请求频率超限制:429, response body: “rate limit exceeded”
python调用示例
下面先用python的Requests来调用一下接口,编写测试程序
# -- coding: utf-8 --
"""
@Time:2022-10-29 23:36
@Author:zstar
@File:te_WeLM.py
@Describe:测试WeLM
"""
import requests
url = 'https://welm.weixin.qq.com/v1/completions'
prompt = "“I am a programmer in Tencent”的中文翻译是:"
data =
"prompt": prompt,
"model": "xl",
"max_tokens": "16",
"temperature": "0.0",
"top_p": "0.0",
"top_k": "10",
"n": "1",
"echo": False,
"stop": ",,.。",
header =
"Content-Type": "application/json",
"Authorization": "自己的token"
if __name__ == '__main__':
response = requests.post(url, json=data, headers=header)
result = eval(response.text) # str -> dict
# print(result)
print(result["choices"][0]["text"])
这里的替换成Authorization自己的token
微信公众号开发
本地测试完成,那么接下来就来部署到微信公众号上。
微信公众号官方文档:https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Getting_Started_Guide.html
这里顺便吐槽一下,微信公众号官方给的python例程是基于python2.7的,我采用的版本是python3.8,部署起来有很多坑。
设置服务器配置
微信公众号开发需要一台有公网ip的服务器,我手上正好有一台云服务器。首先需要在公众号后台绑定服务器。
现在服务器上进行配置,先安装web库
pip install web.py
然后编写main.py,进行测试:
# -*- coding: utf-8 -*-
# filename: main.py
import web
from handle import Handle
urls = (
'/wx', 'Handle',
)
if __name__ == '__main__':
app = web.application(urls, globals())
app.run()
终端输入:
python3 main.py 80
正常运行如下图所示,如果报错,则说明80端口可能被其它程序占用,需要手动进行调整

测试完成,进入到微信公众号后台这个位置,设置自己的URL:服务器域名/wx,Token需要自己设置,建议用工具生成,太短容易和别人重复,造成后面其它错误,然后随机生成Key。
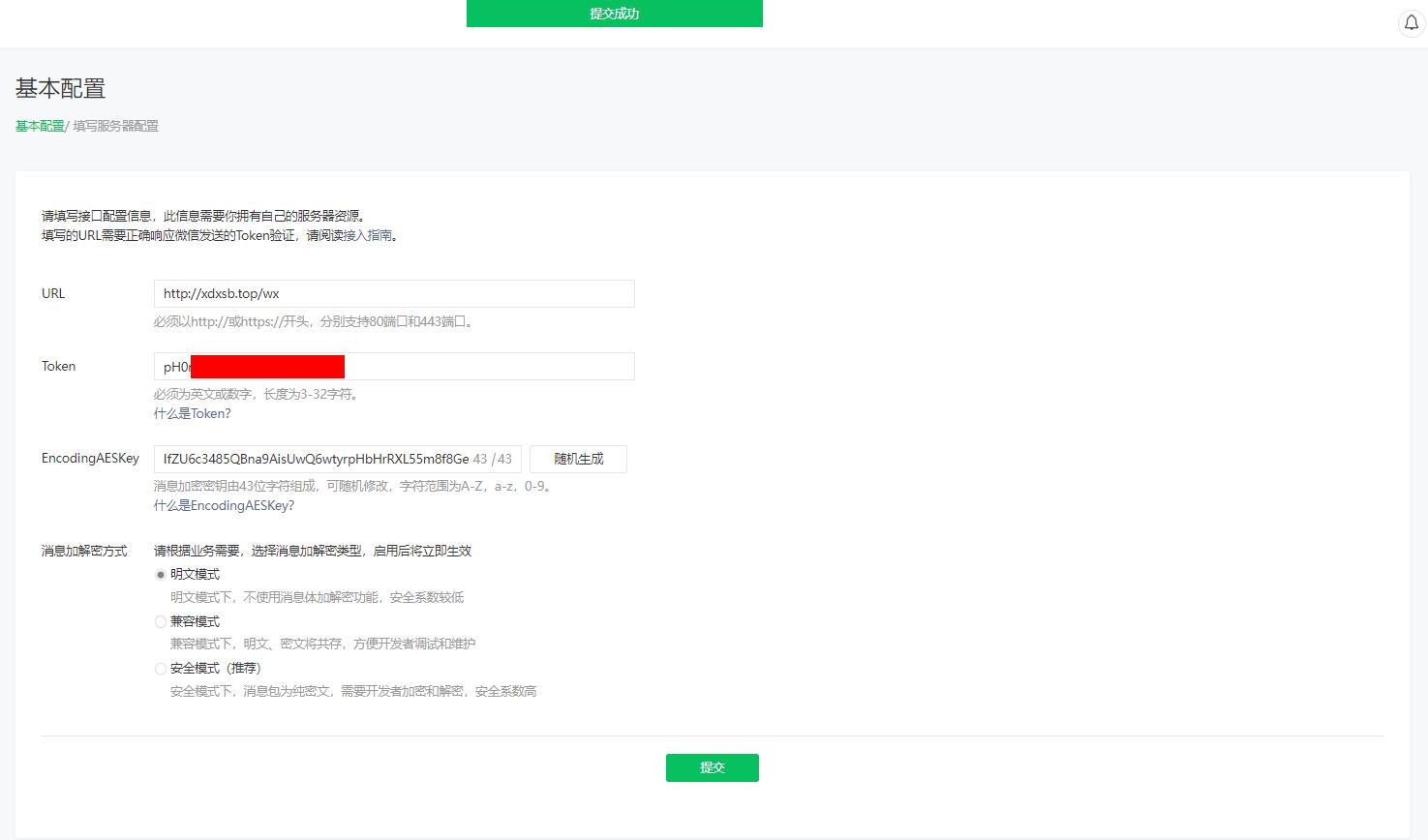
直接点提交会失败,还需要在服务器端进行设置:
新建handle.py,token修改为自己设置的token
# -*- coding: utf-8 -*-
# filename: handle.py
import hashlib
import web
class Handle(object):
def GET(self):
try:
data = web.input()
if len(data) == 0:
return "hello, this is handle view"
signature = data.signature
timestamp = data.timestamp
nonce = data.nonce
echostr = data.echostr
token = "自己的token" #请按照公众平台官网\\基本配置中信息填写
list =[token, timestamp, nonce]
list.sort()
sha1=hashlib.sha1()
sha1.update(list[0].encode('utf-8'))
sha1.update(list[1].encode('utf-8'))
sha1.update(list[2].encode('utf-8'))
hashcode= sha1.hexdigest()
print("handle/GET func: hashcode, signature: ", hashcode, signature)
if hashcode == signature:
return echostr
else:
return ""
except Exception:
return ""
然后重新运行:
python3 main.py 80
这时候再去公众号后台点提交,提交成功则设置完成。
开启自动回复
在嵌入WeLM之前,先来实现一个自动回复的功能,即输入任何内容,公众号会自动回复设定好的内容。
修改handle.py
# -*- coding: utf-8 -*-#
# filename: handle.py
import hashlib
import reply
import receive
import web
class Handle(object):
def POST(self):
try:
webData = web.data()
print("Handle Post webdata is ", webData)
#后台打日志
recMsg = receive.parse_xml(webData)
if isinstance(recMsg, receive.Msg) and recMsg.MsgType == 'text':
toUser = recMsg.FromUserName
fromUser = recMsg.ToUserName
content = "test"
replyMsg = reply.TextMsg(toUser, fromUser, content)
return replyMsg.send()
else:
print("暂且不处理")
return "success"
except Exception:
return "fail"
编写receive.py
# -*- coding: utf-8 -*-#
# filename: receive.py
import xml.etree.ElementTree as ET
def parse_xml(web_data):
if len(web_data) == 0:
return None
xmlData = ET.fromstring(web_data)
msg_type = xmlData.find('MsgType').text
if msg_type == 'text':
return TextMsg(xmlData)
elif msg_type == 'image':
return ImageMsg(xmlData)
class Msg(object):
def __init__(self, xmlData):
self.ToUserName = xmlData.find('ToUserName').text
self.FromUserName = xmlData.find('FromUserName').text
self.CreateTime = xmlData.find('CreateTime').text
self.MsgType = xmlData.find('MsgType').text
self.MsgId = xmlData.find('MsgId').text
class TextMsg(Msg):
def __init__(self, xmlData):
Msg.__init__(self, xmlData)
self.Content = xmlData.find('Content').text.encode("utf-8")
class ImageMsg(Msg):
def __init__(self, xmlData):
Msg.__init__(self, xmlData)
self.PicUrl = xmlData.find('PicUrl').text
self.MediaId = xmlData.find('MediaId').text
编写reply.py
# -*- coding: utf-8 -*-#
# filename: reply.py
import time
class Msg(object):
def __init__(self):
pass
def send(self):
return "success"
class TextMsg(Msg):
def __init__(self, toUserName, fromUserName, content):
self.__dict = dict()
self.__dict['ToUserName'] = toUserName
self.__dict['FromUserName'] = fromUserName
self.__dict['CreateTime'] = int(time.time())
self.__dict['Content'] = content
def send(self):
XmlForm = """
<xml>
<ToUserName><![CDATA[ToUserName]]></ToUserName>
<FromUserName><![CDATA[FromUserName]]></FromUserName>
<CreateTime>CreateTime</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[Content]]></Content>
</xml>
"""
return XmlForm.format(**self.__dict)
class ImageMsg(Msg):
def __init__(self, toUserName, fromUserName, mediaId):
self.__dict = dict()
self.__dict['ToUserName'] = toUserName
self.__dict['FromUserName'] = fromUserName
self.__dict['CreateTime'] = int(time.time())
self.__dict['MediaId'] = mediaId
def send(self):
XmlForm = """
<xml>
<ToUserName><![CDATA[ToUserName]]></ToUserName>
<FromUserName><![CDATA[FromUserName]]></FromUserName>
<CreateTime>CreateTime</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[MediaId]]></MediaId>
</Image>
</xml>
"""
return XmlForm.format(**self.__dict)
再次运行:
python3 main.py 80
在公众号后台设定“启用”,然后就可以进行实机测试:
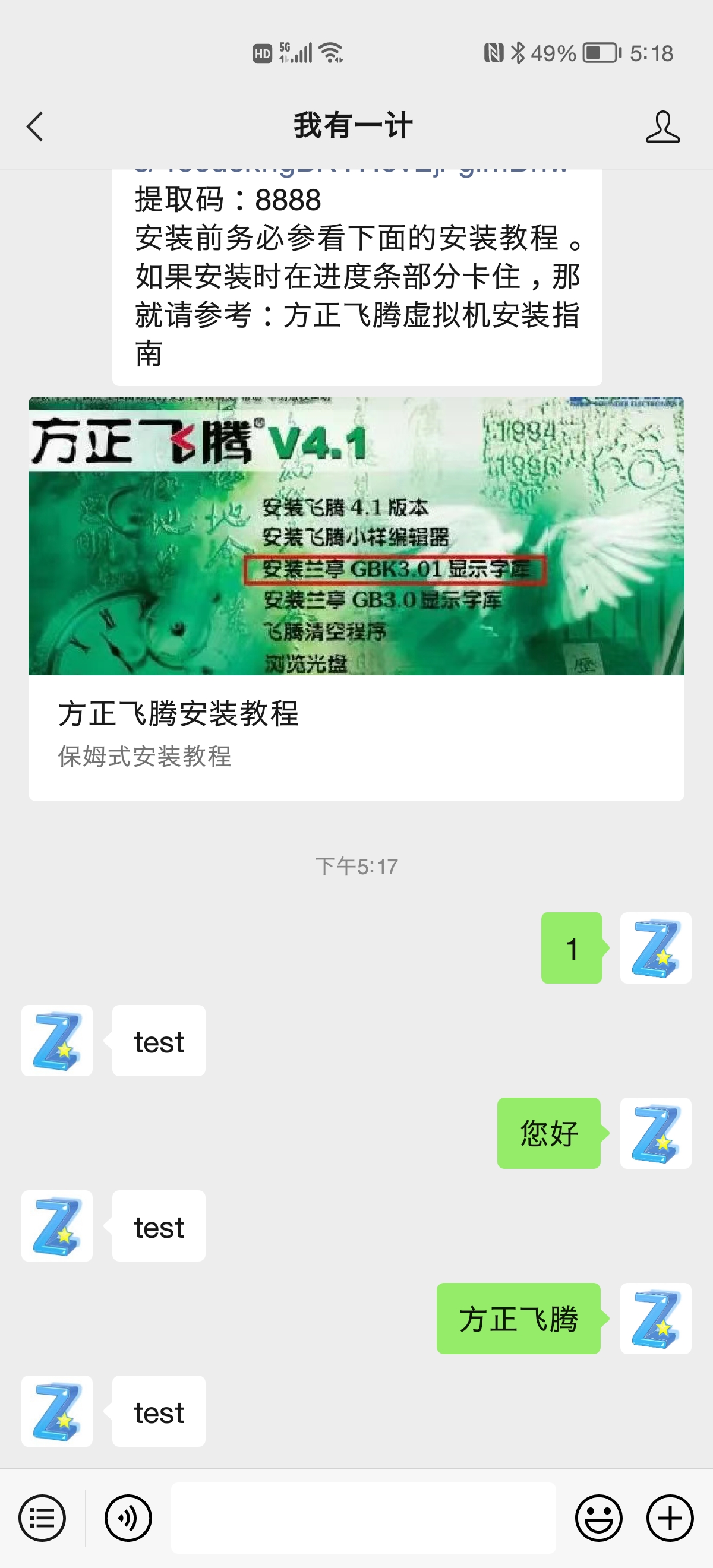
解析收到的信息
上面的例子只会回答固定的语言,那么是否能再进一步,获取用户所发的信息呢?
方式也很容易,修改handle.py如下:
# -*- coding: utf-8 -*-#
# filename: handle.py
import hashlib
import reply
import receive
import web
class Handle(object):
def POST(self):
try:
webData = web.data()
print("Handle Post webdata is ", webData) # 后台打日志
recMsg = receive.parse_xml(webData)
if isinstance(recMsg, receive.Msg) and recMsg.MsgType == 'text':
toUser = recMsg.FromUserName
fromUser = recMsg.ToUserName
recmsg = recMsg.Content # 获取收到的信息内容
recmsg = recmsg.decode() # 将二进制编码信息解码为字符串
content = "收到消息:" + recmsg + "\\n本公众号暂时升级维护中,请等维护结束后再发关键词"
replyMsg = reply.TextMsg(toUser, fromUser, content)
return replyMsg.send()
else:
print("暂且不处理")
return "success"
except Exception:
return "fail"
整合WeLM
现在我们把之前编写好的WeLM改成一个函数,就能整合进去
编写WeLM.py
import requests
def run(prompt):
url = 'https://welm.weixin.qq.com/v1/completions'
data =
"prompt": prompt,
"model": "xl",
"max_tokens": "16",
"temperature": "0.0",
"top_p": "0.0",
"top_k": "10",
"n": "1",
"echo": False,
"stop": ",,.。",
header =
"Content-Type": "application/json",
"Authorization": "自己的Token"
response = requests.post(url, json=data, headers=header)
result = eval(response.text) # str -> dict
answer = result["choices"][0]["text"]
return answer
修改handle.py
# -*- coding: utf-8 -*-#
# filename: handle.py
import hashlib
import reply
import receive
import web
import WeLM
class Handle(object):
def POST(self):
try:
webData = web.data()
print("Handle Post webdata is ", webData)
#后台打日志
recMsg = receive.parse_xml(webData)
if isinstance(recMsg, receive.Msg) and recMsg.MsgType == 'text':
toUser = recMsg.FromUserName
fromUser = recMsg.ToUserName
recmsg = recMsg.Content
recmsg = recmsg.decode()
answer = WeLM.run(recmsg)
content = str(answer)
replyMsg = reply.TextMsg(toUser, fromUser, content)
return replyMsg.send()
else:
print("暂且不处理")
return "success"
except Exception:
return "fail"
关注自动回复
值得注意的是,开启服务器配置之后,公众号以往的关注自动回复和关键词自动回复都会失效,那么能否将关注自动回复也添加进去呢?
官方文档在基础消息能力/接收事件推送一节中,给出了关注事件的XML数据格式:
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[subscribe]]></Event>
</xml>
因此,可以把关注事件和收到消息事件整合成一个类
修改receive.py
# -*- coding: utf-8 -*-#
# filename: receive.py
import xml.etree.ElementTree as ET
def parse_xml_sub(web_data):
if len(web_data) == 0:
return None
xmlData = ET.fromstring(web_data)
return Sub_Msg(xmlData)
class Sub_Msg(object):
def __init__(self, xmlData):
self.ToUserName = xmlData.find('ToUserName').text
self.FromUserName = xmlData.find('FromUserName').text
self.CreateTime = xmlData.find('CreateTime').text
self.MsgType = xmlData.find('MsgType').text
self.Event = xmlData.find('Event').text if xmlData.find('Event') is not None else None
self.EventKey = xmlData.find('EventKey').text if xmlData.find('EventKey') is not None else None
self.MsgId = xmlData.find('MsgId').text if xmlData.find('MsgId') is not None else None
self.Content = xmlData.find('Content').text.encode("utf-8") if xmlData.find('Content') is not None else None
修改handle.py
# -*- coding: utf-8 -*-#
# filename: handle.py
import hashlib
import reply
import receive
import web
import WeLM
class Handle(object):
def POST(self):
try:
webData = web.data()
print("Handle Post webdata is ", webData) # 后台打日志
recMsg = receive.parse_xml_sub(webData)
if recMsg谈近期我对博客及微信公众号的态度