关于Texture Cache简单总结
Posted wolf96
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Texture Cache简单总结相关的知识,希望对你有一定的参考价值。
Texture Cache是一个存储图片数据的只读cache
按照正常uv顺序读贴图tex cache有高命中率
Texture Cache在 shader processor附近,所以它有高吞吐率,并且低延迟
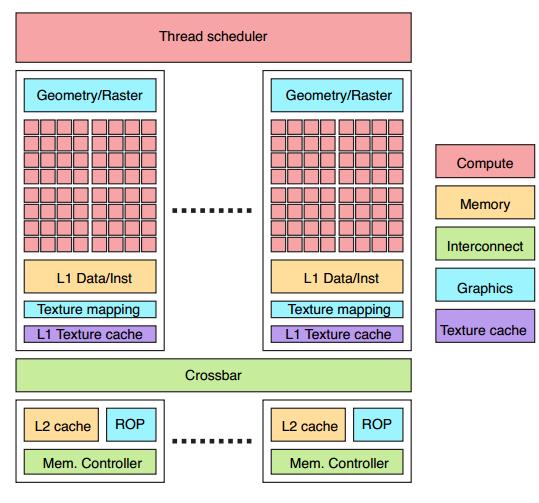
上图可见有许多 shader core
texture units may be grouped together with one texture unit per shader core, or one texture unit shared among two or three shader cores, depending on the GPU.
The whole chip shares a single L2 cache, but the different units will have individual L1 caches.
每个shader core一个texture unit,或者在两个或三个shader core之间共享一个texture unit
整个chip共享一个L2 cache,每个单元自己用一个L1cache
Texture units operate independently and asynchronously from shader cores. When a shader performs a texture read, it sends a request to the texture unit across a little bus between them; the shader can then continue executing if possible, or it may get suspended and allow other shader threads to run while it waits for the texture read to finish.
Texture units与shader cores的运算相独立,Texture units是异步运算,当shader执行一次纹理读取时,会通过Texture units与shader cores之间的总线向Texture units发送请求,shader可能继续执行也可能被挂起等待返回的结果
The texture unit batches up a bunch of requests and performs the addressing math on them—selecting mip levels and anisotropy, converting UVs to texel coordinates, applying clamp/wrap modes, etc. Once it knows which texels it needs, it reads them through the cache hierarchy, the same way that memory reads work on a CPU (look in L1 first, if not there then L2, then DRAM). If many pending texture requests all want the same or nearby texels (as they often do), then you get a lot of efficiency here, as you can satisfy many pending requests with only a few memory transactions. All these operations are pipelined, so while the texture unit is waiting for memory on one batch it can be doing the addressing math for another batch of requests, and so on.
Texture units批量处理请求,执行寻址(选择mip级别, 和各项异性, 将uv转换为texel坐标,应用clamp/wrap模式,等等),就可以知道需要哪里的texel,之后在cache hierarchy中读取(如果L1 cache没有命中会通过Crossbar去找L2 Cache,如果也没有找到,就会去找DRAM)
如果许多挂起的纹理请求都想要相同的或附近的texels,那么在这里会有效率提升。
Once the data comes back, the texture unit will decode compressed formats, do sRGB conversion and filtering as necessary, then return the results back to the shader core.
一旦数据返回,纹理单元将解码压缩格式,做sRGB转换和过滤,然后将结果返回到shader core。
When a cache miss occurs and a new cache line must be read in from off-chip memory, a large latency is incurred.
如果没有命中缓存,需要从外部存储读入到新的缓存线,会有很大延迟
computing the values that go into a texture map using the GPU has become common place and is called“render to texture”.all on-chip memory references to that texture must be invalidated and then the GPU can write to the texture. A simpler brute force method which flushes all caches in the GPU, can also be used.
TextureCache是只读的,如果有render to texture操作的话,存储器上对该图片的引用都会无效,或者flushes all caches
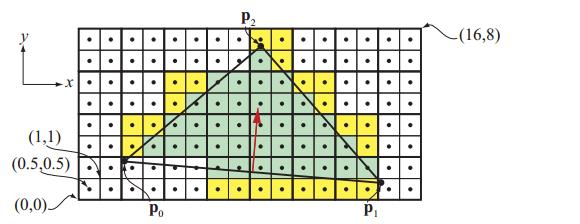
the pixel grid is divided into groups of 2 × 2 pixels, called quads.
光栅化绘制是以quads为单位的,如果三角形太小,只包含一个像素,那么会画上多余的三个空的像素,效率低
传统光栅化会有两个问题:
The order of texels accessed in a texture map can have any orientation with respect to the rasterization order. If the texels in a texture map are stored in memory in a simple linear row major ordering, and the texture is mapped horizontally,then cache lines will store long horizontal lines resulting in a high hit rate. But if the texture is mapped at a 90 degrees rotation, then every pixel will miss and require a new cacheline to be loaded.
https://computergraphics.stackexchange.com/questions/357/is-using-many-texture-maps-bad-for-caching
Although I suspect most textures these days will be stored in either a tiled or Morton-like (aka Twiddled/Swizzled) order (or even a combination of both), some textures might still be in scan-line order, which means that rotation of the texture is likely to lead to a significant number of cache misses/page breaks. Unfortunately, I don't really know how to spot if a particular format is arranged in such a way.
1.贴图中纹素的访问顺序由光栅化顺序决定,如果cache中存储的方向与光栅化方向不同,就会导致命中率下降,会加载新的cacheline
For very large triangles a texture cache could fill up as pixels are generated across a horizontal span and on returning to the next line find that the texels from the previous line have been evicted from the cache.
2.如果三角形过大,水平绘制完一行,Texture Cache全被填充,当绘制下一行时上一行已经被cache消除
Tiled Rasterization 会解决上面两个问题。
To avoid this orientation dependency textures are stored in memory in a tiled higher cache hit rates are achieved when the tile size is equal to cache line size for cache sizes of 128KB and 256KB and tile sizes of 8×8 and 16×16.
Tiled rasterization divides the screen into equally sized rectangles, typically powers of two , and completes the rasterization within each tile before moving to the next tile.
将屏幕分成格子,逐个格子进行栅格化
The texture unit requires 4 texels in parallel in order to perform one bilinear operation, so most texture caches are designed to feed these values in parallel in order to maintain full rate for bilinear filtering.
因为texture unit需要4个texel来进行bilinear过滤,所以大多texture cache被设计成并行来保持bilinear filtering全速进行。
Most GPUs have multiple texture filtering units running in parallel, and the texture cache must supply these with texels. To do this the texture cache uses multiple read ports, or else replicates the data in the cache.
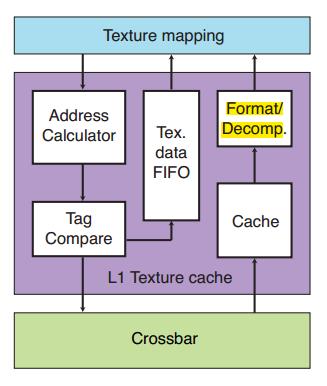
纹理压缩可以减少纹理带宽,解压缩发生在读取压缩的纹理和准备 texture filter之间
texture accesses that hit in the cache must wait in the FIFO behind others that miss. A FIFO is used because the graphics pipeline ensures that triangle submission order is maintained
因为先入先出的队列数据流,排在后面的尽管被缓存命中也要等待排在前面的没有命中的部分
关于Texture Cache的优化
The easiest way to break the texture cache is to do lots of dependent texture reads and what I mean by dependent texture reads is to generate a texture coordinate in the fragment shader and then go fetch it instead of the interpolated texture coordinate.
This is going to start fetching texels from areas that are very different in your actual texture map, which is going to cause the cache to be thrashed often.
1.不是按照顶点shader插值的uv读取贴图
会破坏tex缓存导致cache经常thrashed,因为基本不会命中,还会导致缓存经常被刷新。
2.贴图不能过大
贴图太大,导致贴图cache超载,使得cache不能命中
3.贴图格式尽量小
原因同上
4.Tiled Rasterization
会有助于在光栅化时命中Cache,避免三角形过大和光栅化与贴图方向不同产生的cache miss/page break问题
5.使用mipmap
https://blogs.msdn.microsoft.com/shawnhar/2009/09/14/texture-filtering-mipmaps/
Remember our example of a tiled 256x256 texture, where each repeat is being scaled down to 1x1 (a common situation in things like terrain rendering). Without mipmaps, every destination pixel will sample a radically different location in the source texture, so the GPU must jump around fetching colors from different areas of memory. GPUs typically have very small texture caches, relying on the fact that textures tend to be accessed sequentially, so this access pattern will thrash the cache and can bring even a high end card to its knees. But with mipmaps, the GPU can simply load a small mip level which will easily fit in the cache, and can then render many destination pixels without having to go back to main memory.
6.压缩贴图
可以节省带宽
并且因为cache中存储的是压缩的texel,所以能增加tex cache中存储texel的数量,因为解压缩是在数据出tex cache后在tex unit中进行的。
指定的压缩格式在指定的硬件中解压缩很容易
https://computergraphics.stackexchange.com/questions/357/is-using-many-texture-maps-bad-for-caching
Perhaps a bit of an obvious option, but if you can use texture compression (e.g. DXTn|ETC*|PVRTC*|etc) targeting from 8bpp(Bits Per Pixel) down to, say, 2bpp, you can greatly increase the effectiveness of the memory bandwidth/cache by factors of 4x through to 16x. Now I can't speak for all GPUs, but some texture compression schemes (e.g. those listed above) are so simple to decode in hardware, that the data could stay compressed throughout the entire cache hierarchy and only be decompressed in the texture unit, thus effectively multiplying the size of those caches.
关于压缩格式详细信息:
https://docs.unity3d.com/550/Documentation/Manual/class-TextureImporterOverride.html
7.少用trilinear filtering和anisotropic filtering
----by wolf96 2019/2/22
参考:
1.Texture Caches
http://fileadmin.cs.lth.se/cs/Personal/Michael_Doggett/pubs/doggett12-tc.pdf
2. Optimising the Graphics Pipeline
https://www.nvidia.com/docs/IO/10878/ChinaJoy2004_OptimizationAndTools.pdf
4.https://blogs.msdn.microsoft.com/shawnhar/2009/09/14/texture-filtering-mipmaps/
5.https://computergraphics.stackexchange.com/questions/357/is-using-many-texture-maps-bad-for-caching
以上是关于关于Texture Cache简单总结的主要内容,如果未能解决你的问题,请参考以下文章