ubuntu server安装hadoop和spark,并设置集群
Posted _luckylight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ubuntu server安装hadoop和spark,并设置集群相关的知识,希望对你有一定的参考价值。
安装server请看本人的上一篇博客
Ubuntu Server 20.04.2 安装
先前准备工作
创建 hadoop用户
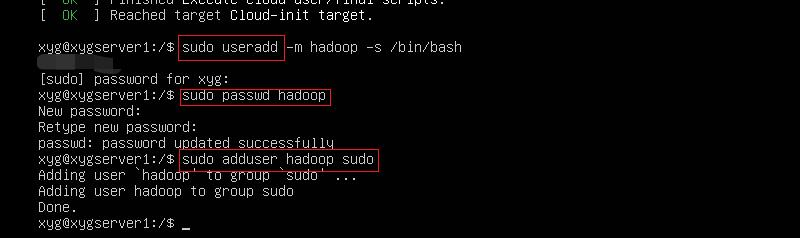
创建用户之后,输入一下指令重启
shutdown -r now
登录 hadoop 用户
安装 ssh 和 vim
首先更新一下 apt 工具
sudo apt-get update
然后安装vim
sudo apt-get install vim
安装ssh server
sudo apt-get install openssh-server
安装 ssh 之后,使用 ssh localhost 命令,查看是否ok
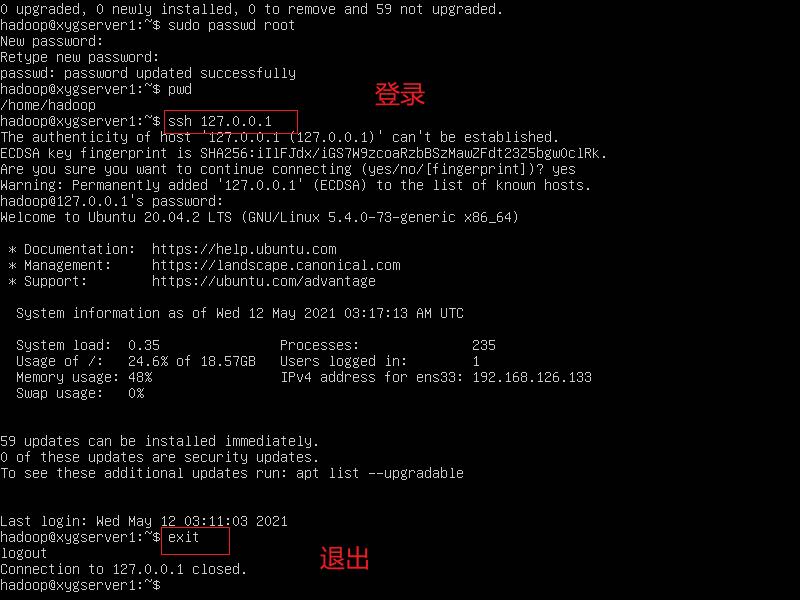
过一会在设置免密登陆
apt-get install network-manager
查看 ip
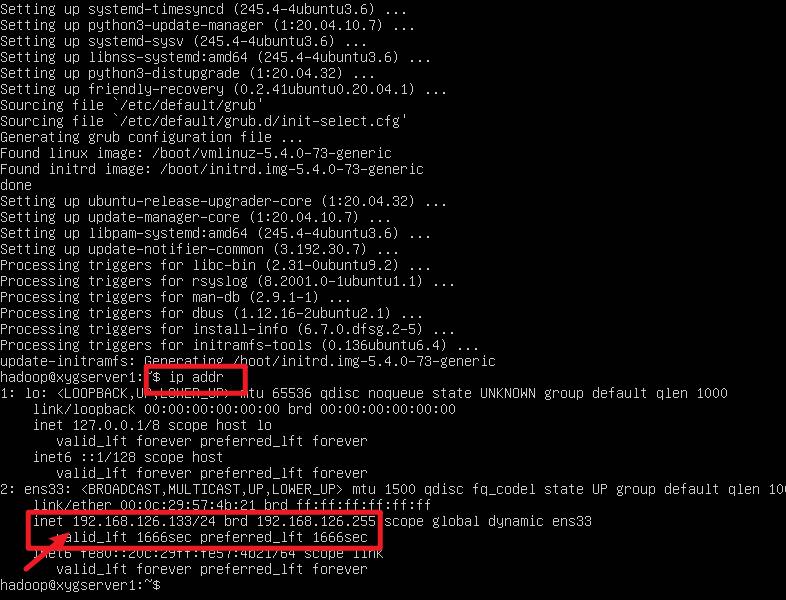
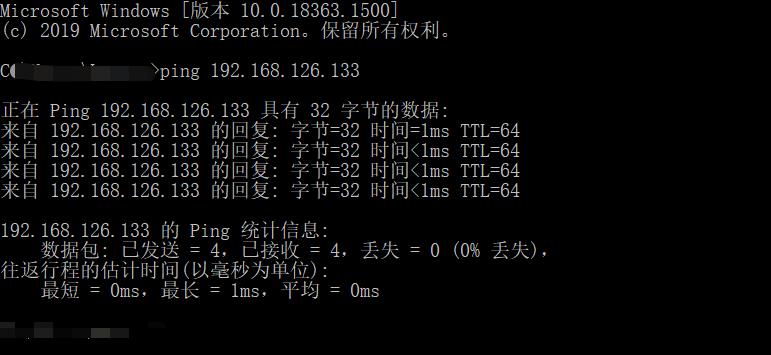
并利用 cmd ping 一下,看看是否正确
查看和修改网络配置信息。
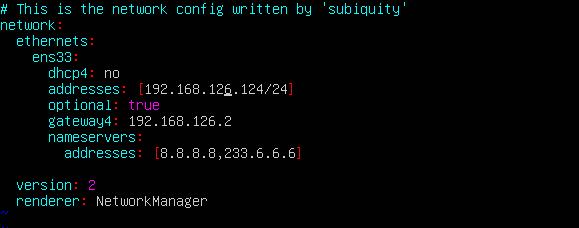
编辑 /etc/netplan 下的 .yaml 文件(注意自己的文件名)
vim /etc/netplan/***.yaml

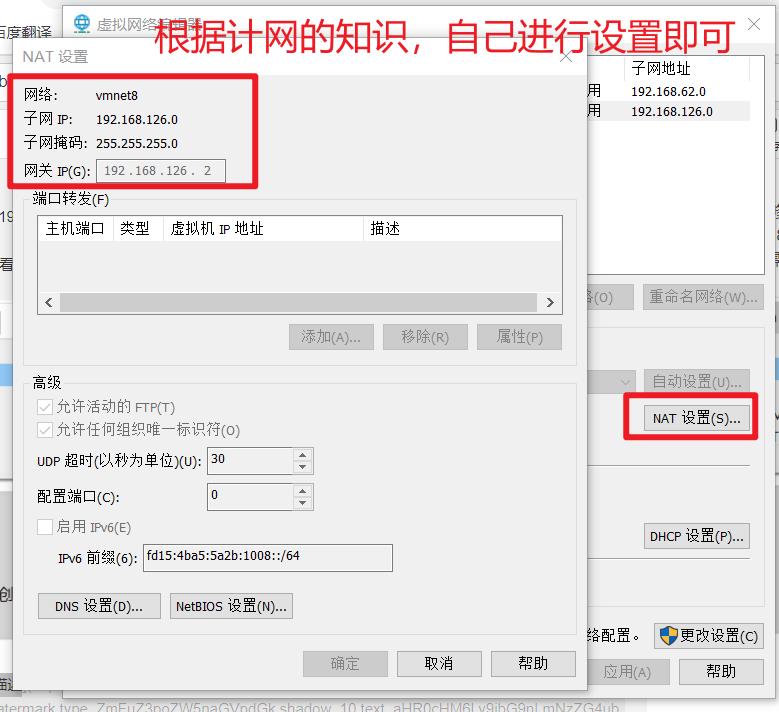
假设IP地址修改为192.168.126.124,子网掩码24位即255.255.255.0,网关设置为192.168.126.2,DNS1:8.8.8.8。
这个部分,需要查看自己虚拟机的设置,来确定自己的ip,不要乱设置,否则会连不上网(非法ip)
然后输入一下命令,
sudo netplan apply
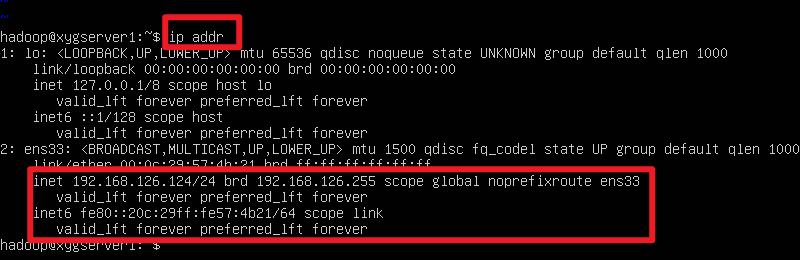
ip addr
测试一下是否可行
windows ping 一下虚拟机
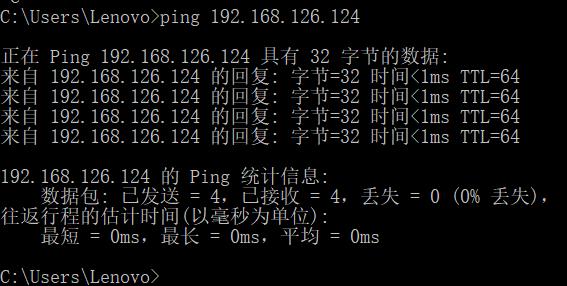
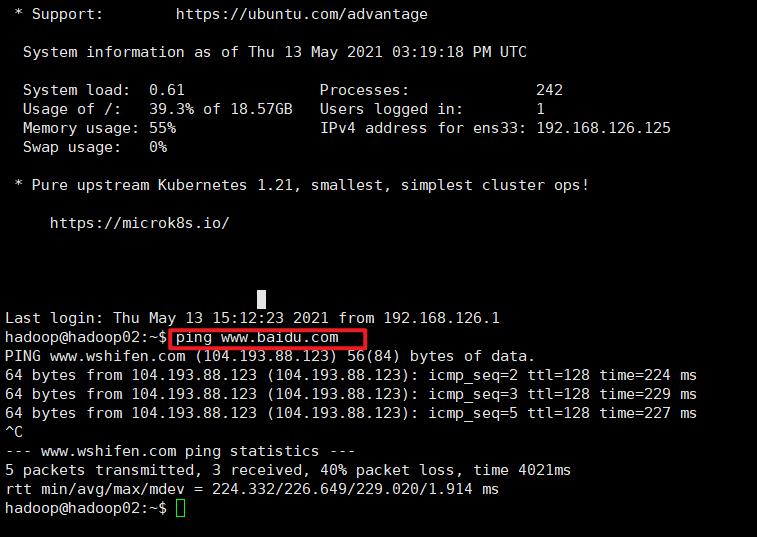
linux server 自己 ping 一下 www.baidu.com
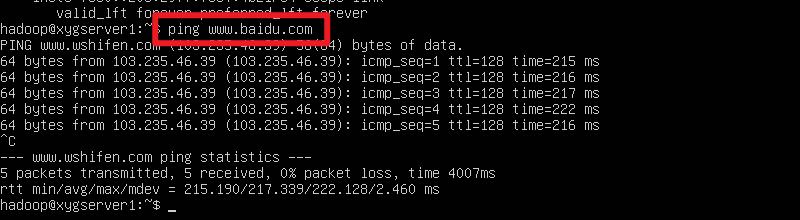
一切正常
修改主机名与IP的映射
搭建一个三台机器的集群,分配的ip如下:
| 主机名称 | 对应 ip地址 |
|---|---|
| hadoop01 | 192.168.126.124 |
| hadoop02 | 192.168.126.125 |
| hadoop03 | 192.168.126.126 |
修改相应的配置文件
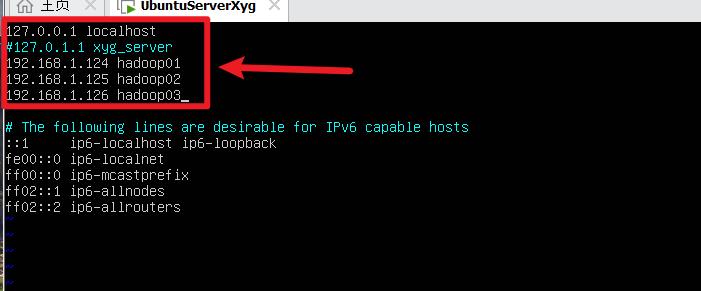
sudo vim /etc/hosts
在该配置文件后加入
192.168.126.124 hadoop01
192.168.126.125 hadoop02
192.168.126.126 hadoop03
并注释掉
#127.0.1.1 hadoop01
# 安装hadoop
为了方便我们的下一步安装(主要是复制主机的信息),我们选择使用 XShell 来辅助完成,详情请参考我的上一篇博客 XShell的破解安装与连接
启动ssh 客户端
查看是否启动 ssh 客户端,客户端是用于连接其他从机,服务端是用于向其他客户端提供链接自己的方式
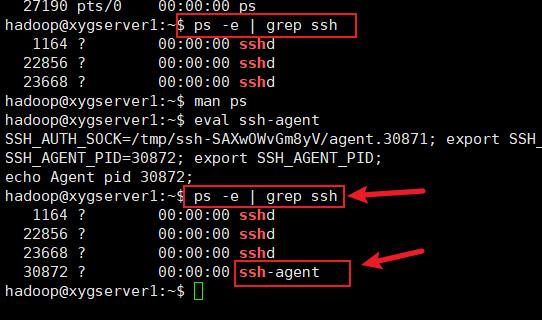
ps -e | grep ssh # 查看当前 ssh 的进,-e 表示every,利用管道线精确查找
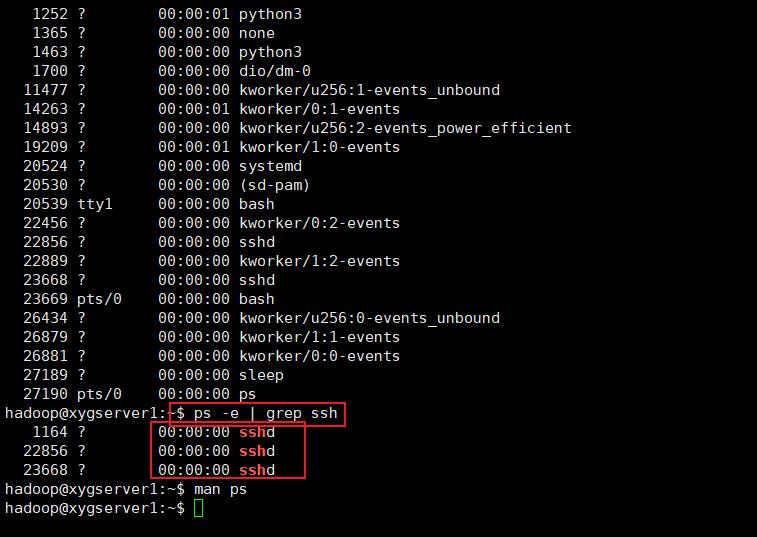
倘若没有 ssh -agent 则需要使用 eval ssh-agent 启动客户端
安装 java
# 先更新更新apt
sudo apt update
sudo apt upgrade
输入下面的命令使用 apt 工具安装 java
# 安装 java
sudo apt install default-jdk default-jre
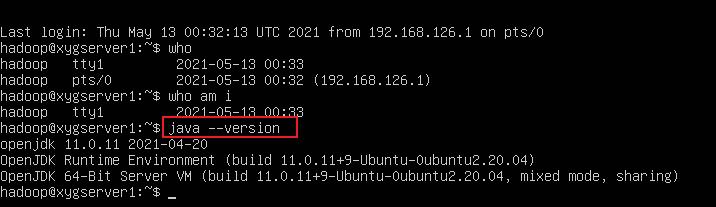
安装完成之后,查看 java 版本,检验是否安装成功
java --version
ssh 免密登陆
想要深入了解,查看我的另一篇博客
输入 ssh localhost 发现 ssh 远程登陆还需要密码,下面我们进行生成秘钥,免密登陆

生成 rsa 秘钥(公钥和私钥)
ssh-keygen -t rsa
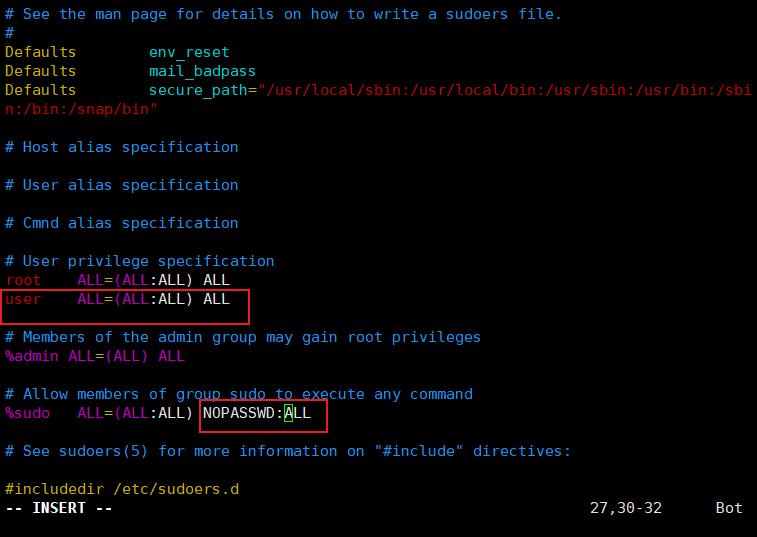
设置root权限
我们创建的普通用户权限不足,不能修改网络配置信息,要先为普通用户赋予root权限,这需要切换到root用户下。首先为root用户设置一个密码并切换到root用户:
安装 hadoop
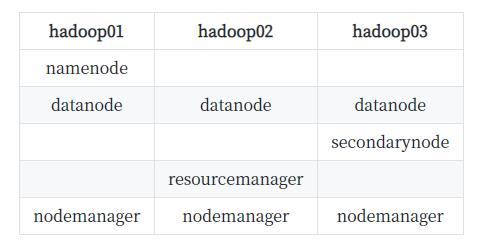
下面对hadoop进行初步的配置。
首先计划集群做一个功能的分配:
现在,我们下载Apache Hadoop的最新稳定版本。
本文所写内容引用Hadoop版本为2021年9月更新的3.2.2版本(虽然不知道为啥这个版本是最近更新的)。如有更新版本,请点击Binary download一栏下面的binary链接,进入下载页面获取到下载链接,作为下述代码的依据。
本文所提供的下载链接来自北京外国语大学的镜像站,速度++。镜像站所有Hadoop的下载地址:Index of /apache/hadoop/common (bfsu.edu.cn);另附上清华大学的镜像站地址:Index of /apache/hadoop/common (tsinghua.edu.cn)
使用非常好使的 wget 命令获取网络资源,wget不加参数,会下载到你当前的目录下
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
tar -xvzf hadoop-3.2.2.tar.gz
接下来将解压后的目录移动到: /usr/local
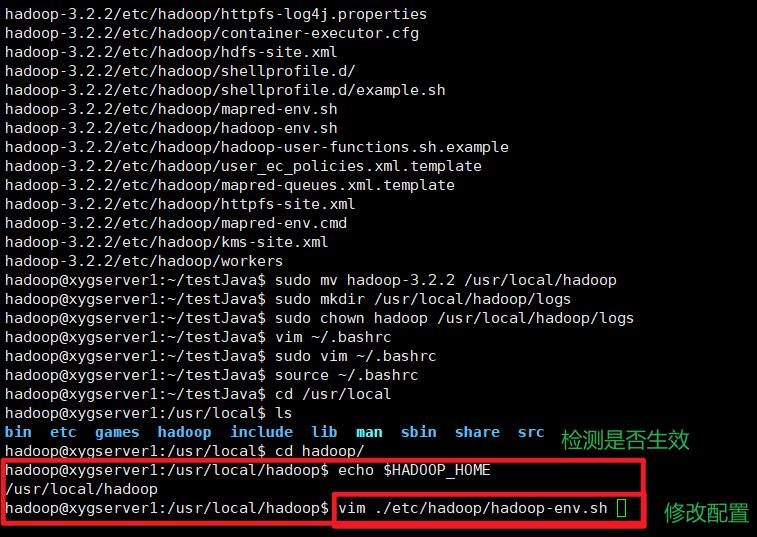
sudo mv hadoop-3.2.2 /usr/local/hadoop
sudo mkdir /usr/local/hadoop/logs
sudo chown hadoop /usr/local/hadoop/logs
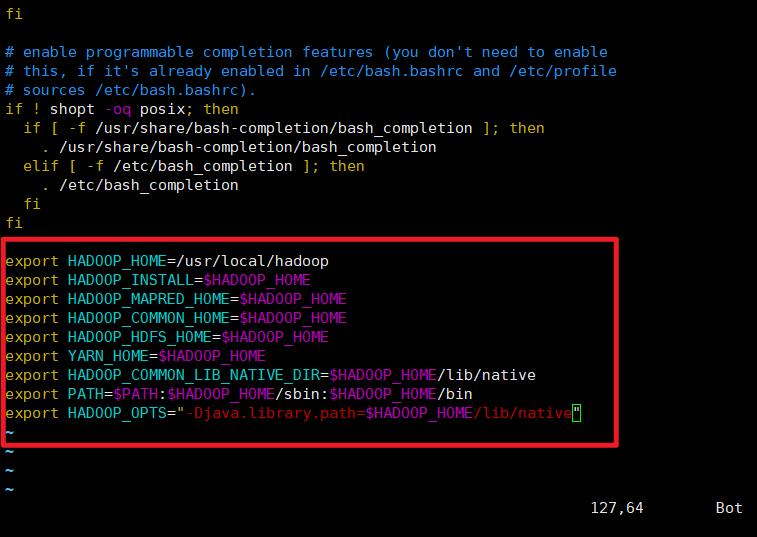
配置环境文件
编辑 ~/.bashrc 文件
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
然后
source ~/.bashrc
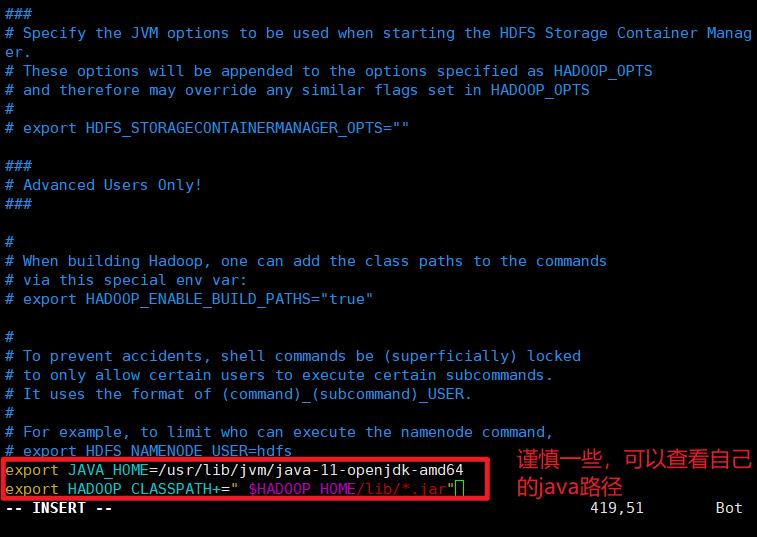
接下来,您需要在hadoop-env.sh中定义Java环境变量,以配置YARN、HDFS、MapReduce和Hadoop相关项目设置。
上一个加上 sudo
下面开始修改hadoop的配置文件:
进入配置文件目录
cd /usr/local/hadoop/etc/hadoop/
修改一下5个文件
- core-site.xml ok
使用命令:vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 告诉 NN 在那个机器,NN 使用哪个端口号接收客户端和 DN 的RPC请求-->
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>user</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
- hdfs-site.xml ok
使用命令:vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
<description>
The secondary namenode http server address and port.
</description>
</property>
</configuration>
- mapred-site.xml
使用命令:vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.</description>
</property>
<!-- MR运行时,向10020端口请求存放历史日志-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<!-- 在浏览器上使用19888可以看历史日志-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description> </property>
</configuration>
- yarn-site.xml ok
使用命令:vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<description>A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>$yarn.resourcemanager.hostname:8088</value>
</property>
<!-- 日志聚集功能,这里原本默认false-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
-
workers
使用命令:vim workers
将内容全部清除掉,并更换为你的三台从机的主机名。
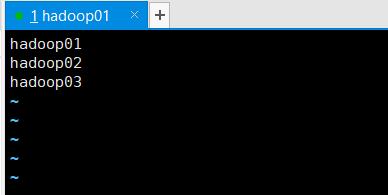
-
xsync(虚拟机之间传送文件,传送至相同文件下)
写一个脚本用于虚拟机之间通过scp传送文件
#!/bin/bash
#校验参数是否合法
if(($#==0))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`; pwd -P)
filename=`basename $1`
echo 要分发的文件的路径是:$dirpath/$filename
#循环执行rsync分发文件到集群的每条机器
for((i=1;i<=3;i++))
do
echo ---------------------hadoop0$i-------------------- # 注意更换为自己的主机名称
rsync -rvlt $dirpath/$filename hadoop0$i:$dirpath
done
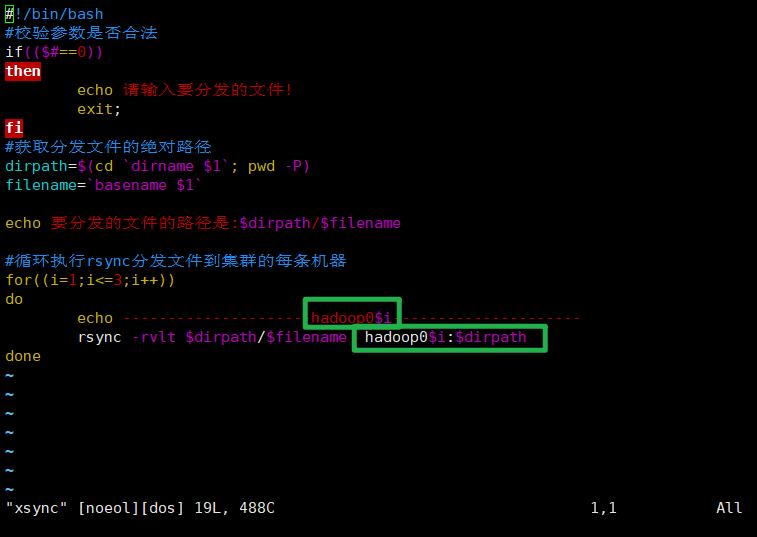
注:各位可以按需将循环中的内容更改为你自己命名的的主机名。如:
你的主机名叫xxx,则去掉循环,依次替换为rsync -rvlt $dirpath/$filename xxx:$dirpath
该命令的含义是 将你主机上的文件复制到 目标主机(/etc/hosts 文件给出了相应的ip,不成功时候,注意查看该文件配置情况)
- xcall
新建一个文件
vim call
#!/bin/bash
#在集群的所有机器上批量执行同一个命令
if(($#==0))
then
echo 请输入要操作的命令!
exit;
fi
echo 要执行的命令是$*
#循环执行此命令
for((i=1;i<=3;i++))
do
echo --------------------hadoop$i--------------------
ssh hadoop$i $*
done
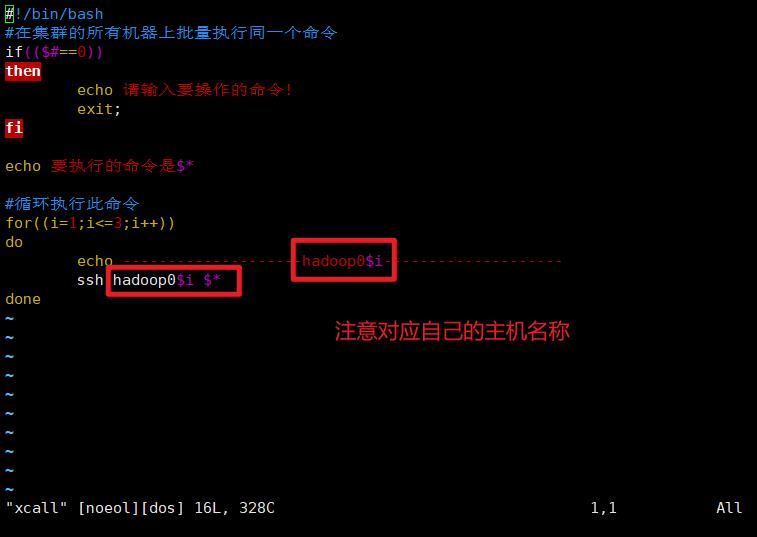
修改权限,并将它们移到 ~/bin/ 目录下
chmod 777 xsync
chmod 777 xcall
mkdir ~/bin # 注意这个bin 是新建的
mv xsync ~/bin
mv xcall ~/bin/
至此,单台虚拟机上所需要的hadoop内容基本上配置完毕,下面开始配置Spark。
安装Spark
获取下载链接、并配置环境
从Downloads | Apache Spark网页中获取您所需的Spark版本(务必按照所安装的Hadoop版本进行选择,撰写之时最新版为3.1.1)。
wget https://mirrors.bfsu.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
tar xvzf spark-3.1.1-bin-hadoop3.2.tgz
sudo mv spark-3.1.1-bin-hadoop3.2/ /usr/local/spark
安装Scala 配置Apache Spark 环境
下载解压之后,我们进行配置环境
vim ~/.bashrc
source ~/.bashrc
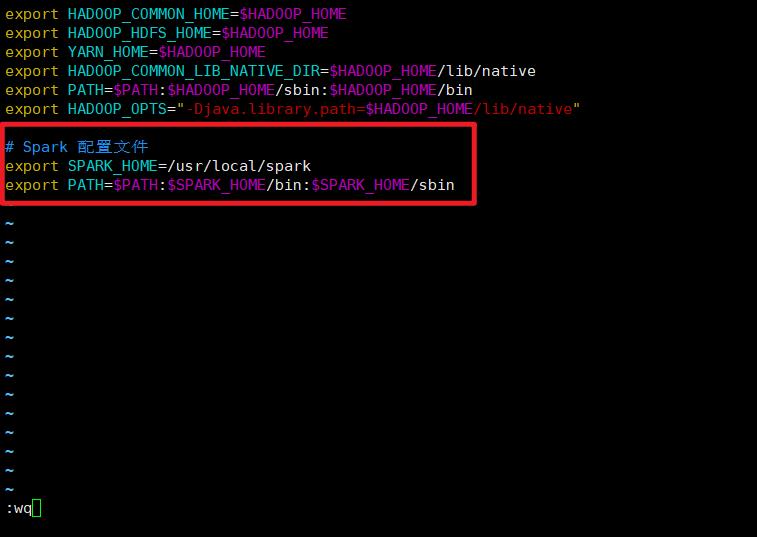
配置的内容如下所示
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
安装scala:
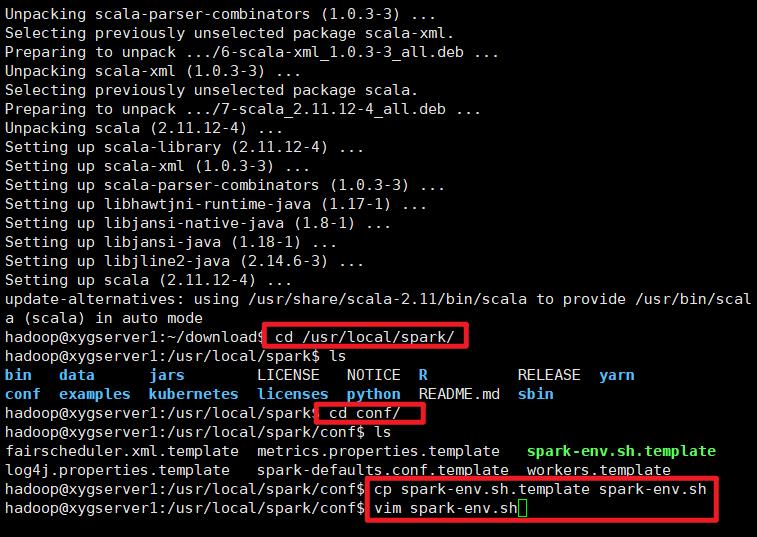
使用命令:sudo apt install scala -y,确认命令执行完毕的最后一行中的安装位置:
更改配置文件
切换到Spark的目录下(cd /usr/local/spark/conf):
将conf文件夹下的spark-env.sh.template重命名为spark-env.sh(mv spark-env.sh.template spark-env.sh),并添加以下内容(vim spark-env.sh):
export SCALA_HOME=/usr/share/scala-2.11
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=hadoop01
export SPARK_LOCAL_DIRS=/usr/local/spark
export SPARK_DRIVER_MEMORY=2g #内存
export SPARK_WORKER_CORES=2 #cpus核心数
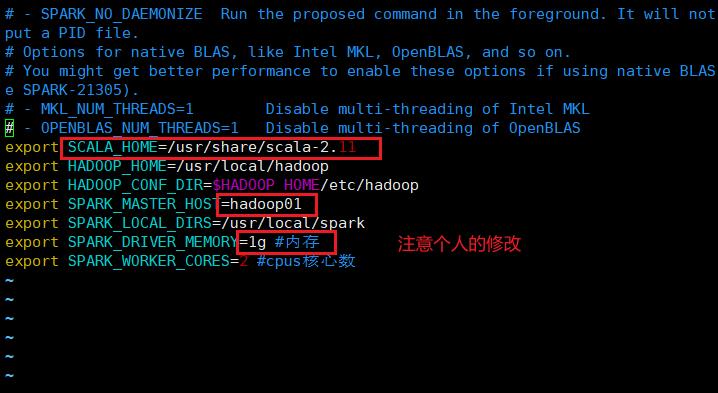
不建议将虚拟机内存全部分配给他
将conf文件夹下的workers.template重命名为workers(mv workers.template workers),并修改为以下内容(vim workers)
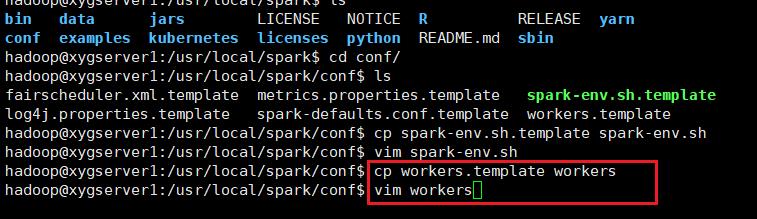
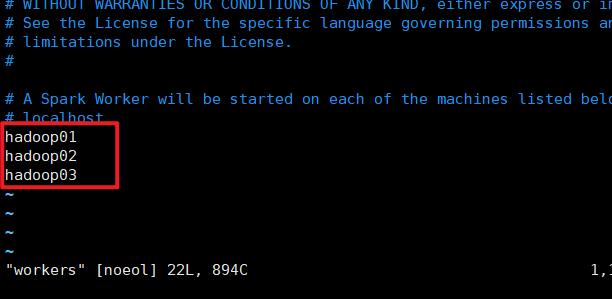
hadoop01
hadoop02
hadoop03
至此,单台虚拟机上所需要的内容基本上配置完毕,我们只需要将虚拟机克隆两台然后配置各自的固定IP、主机名,重新生成ssh密匙即可。
克隆虚拟机
虚拟机的克隆
将虚拟机关机,点击工具栏的虚拟机-管理-克隆。
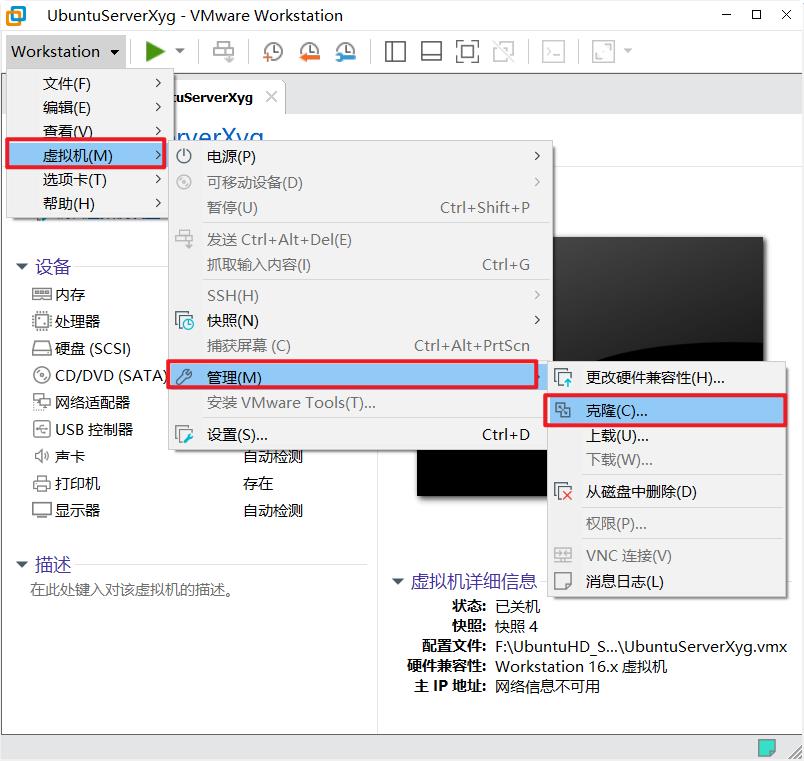
点击下一步
点击下一步
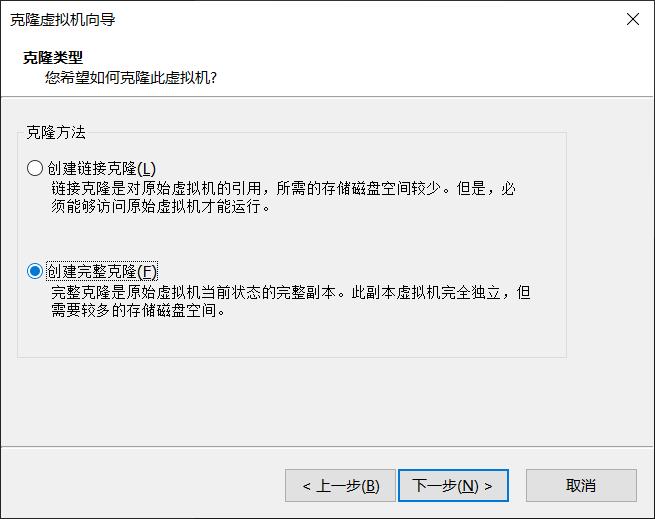
选择创建完整克隆
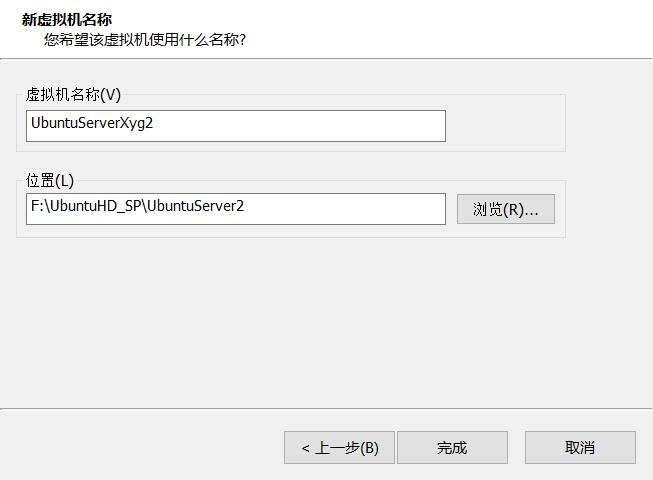
改个名,点完成
我们需要克隆出来两个,重复此步骤。
启动第二个(克隆出来的第一个)虚拟机。
虚拟机需要一个一个启动,因为克隆出来的虚拟机的ip是一样的,会导致冲突。需要一个一个修改启动。由于虚>拟机的ip没有发生改变,所以还可以使用xshell直接进行连接。
使用命令sudo vim /etc/hostname,将文件的内容修改为hadoop02;
编辑网络配置信息文件,使用下述命令查看网络配置文件名称,并使用vim编辑器打开它:
cd /etc/netplan
ls
注意保持里面的基本信息,并修改其中的ip地址到你设计的ip地址;
改完之后sudo netplan apply 进行 应用,ping 一个网址进行测试查看是否ok
然后重启虚拟机,按照文章之前的xshell建立新连接的步骤新建连接到hadoop02主机。同理设置最后一台虚拟机。
ssh 秘钥设置
在三台虚拟机上分别执行:
ssh-keygen -t rsa
这里是生成了rsa密钥
然后将这三个密钥在三台虚拟机上相互传输
首先,在hadoop01上向hadoop01、hadoop02、hadoop03发送
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
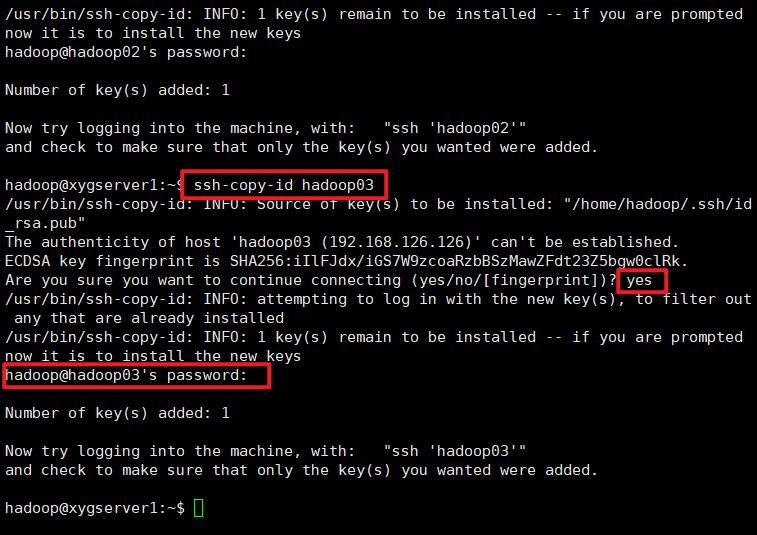
第一个输入yes,第二个输入密码
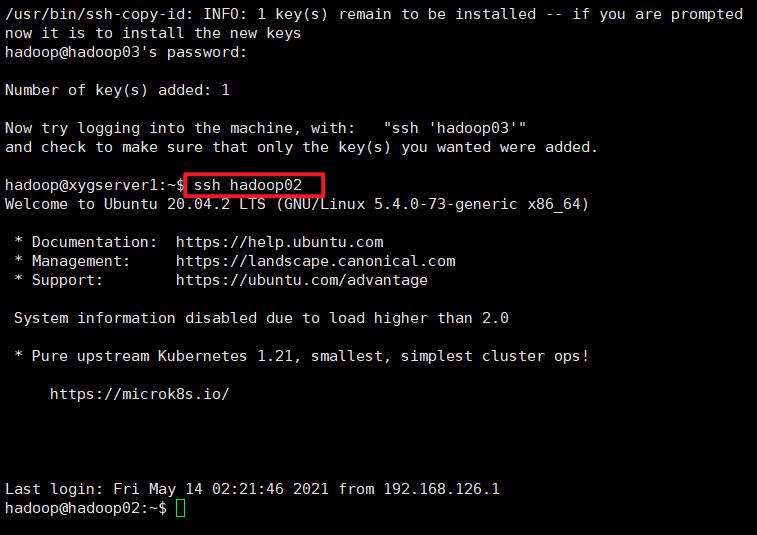
输入ssh查看是否设置成功
重复执行。
下面测试xcall和xsync命令
使用xcall来关闭三台虚拟机上的防火墙,在hadoop01的终端上输入(起始任意一台虚拟机都可以)
xcall sudo ufw disable
倘若出现“/bin/bash^M: bad interpreter“的,博客
解决方案
使用linux命令dos2unix filename,直接把文件转换为unix格式;
然后我们查看 xcall sudo ufw disable 结果
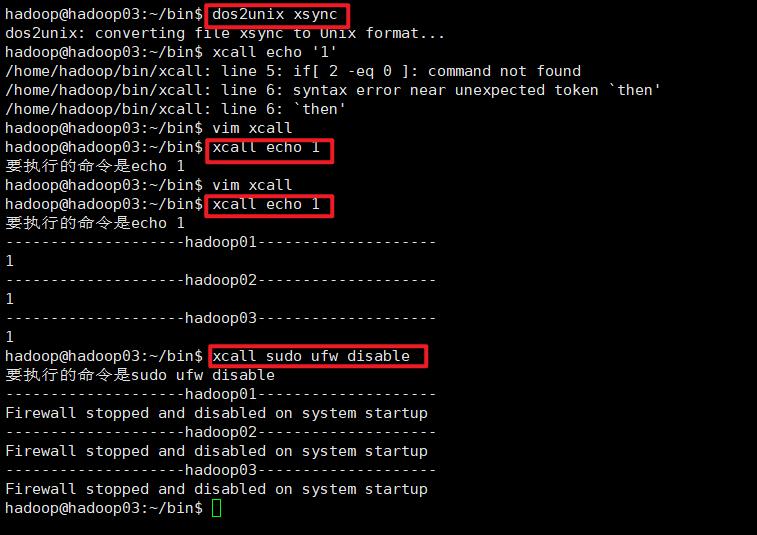
测试发现没毛病
hadoop初次使用
运行hadoop
还之前的那个 hadoop 安装一样,初始化 namenode
hadoop namenode -format
在 /usr/local/hadoop/sbin 中运行
start-all.sh
jsp 查看进程
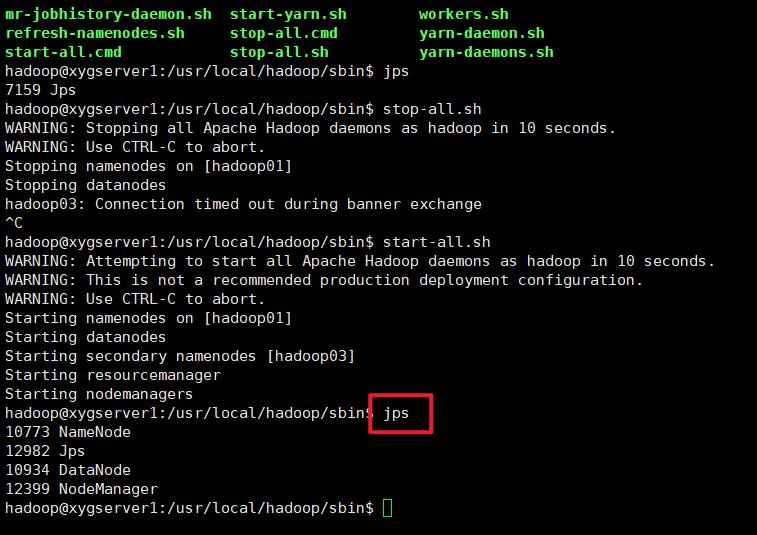
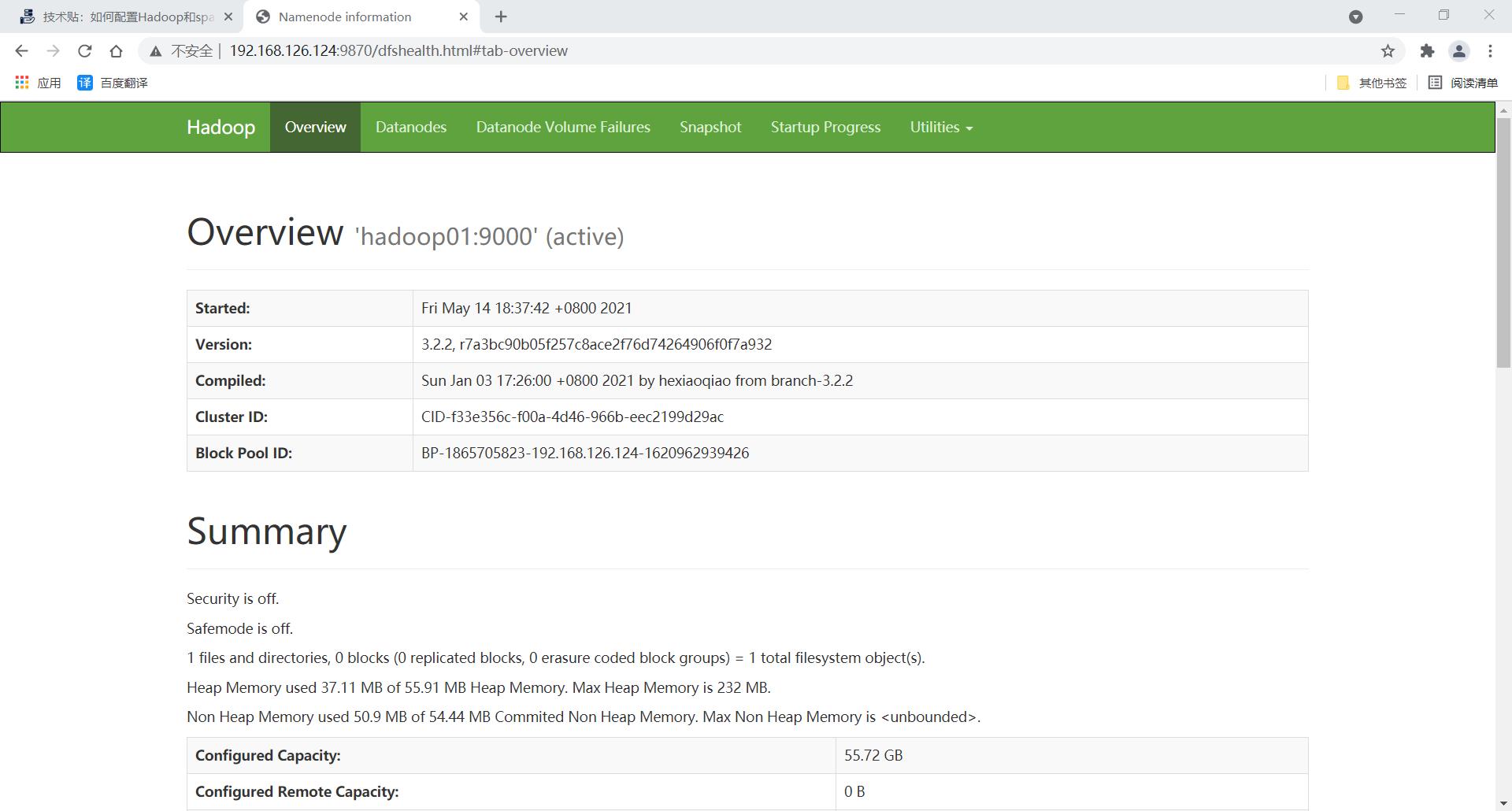
通过 web 访问试一试是否成功
192.168.182.159:9870
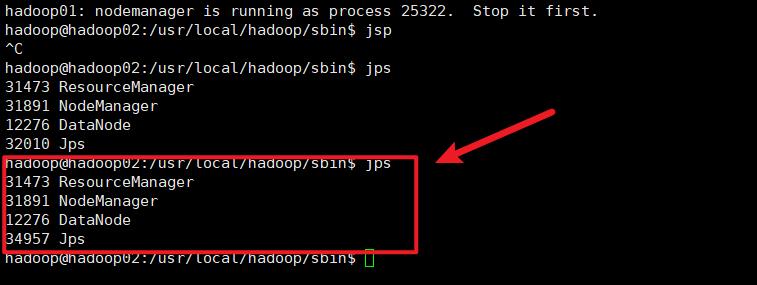
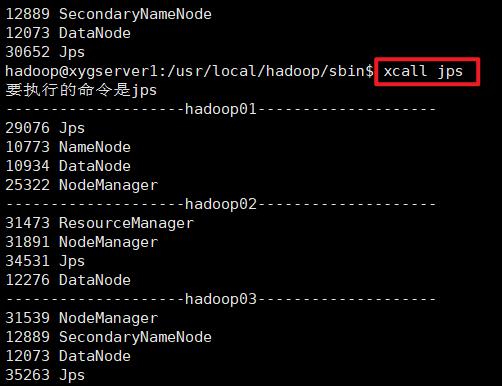
查看JPS情况
hadoop01

hadoop02
hadoop03
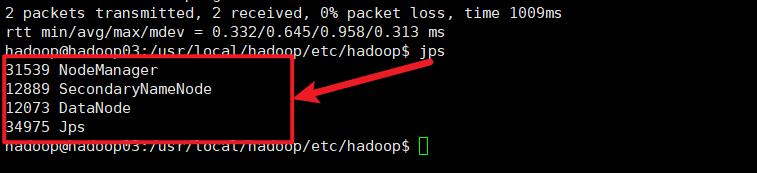
或者是使用 xcall
参考博客
以上是关于ubuntu server安装hadoop和spark,并设置集群的主要内容,如果未能解决你的问题,请参考以下文章