Flink 的键组 KeyGroup 与 缩放 Rescale
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 的键组 KeyGroup 与 缩放 Rescale相关的知识,希望对你有一定的参考价值。
序
参考:
Flink状态的缩放(rescale)与键组(Key Group)设计_LittleMagics的博客-CSDN博客
【Flink】Flink key 应该分配到哪个 KeyGroup 以及 KeyGroup 分配在哪个subtask_九师兄的博客-CSDN博客_flink key
总览:
共计2k字,阅读时间10min。
前言
在 Flink 中,有很多数据需要进行保存,而且以及集群的方式进行保存以及重现。在分布式中的保存以及回复是很难实现的。那么我们先看看 Flink 是怎么进行保存的。
State
State 是 Flink 进行状态保留,那么具体定义如下:
When it comes to stateful stream processing, state comprises of the information that an application or stream processing engine will remember across events and streams as more realtime (unbounded) and/or offline (bounded) data flow through the system.
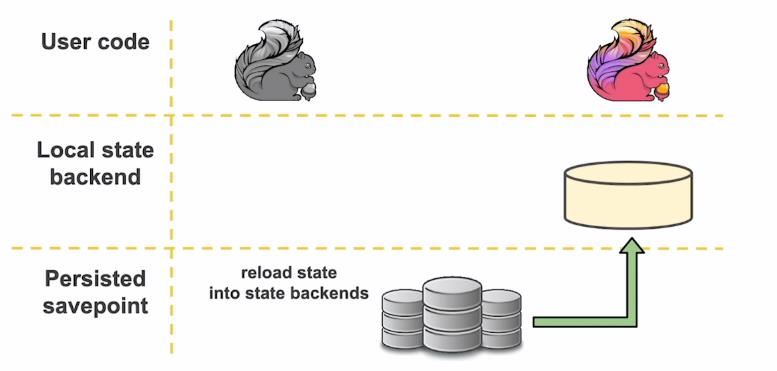
这句话的主要意思就是,State 是流处理过程中需要记住的数据的快照,而这些数据既可以包括业务数据,也可以包括元数据(比如 各种 JDBC、Connecter)。以最常用的 RocksDB 状态后端为例子,状态数据的流动可以抽象为三层,分别是:User code、Local state backend、Persisted savepoint。

用户代码产生的状态实时地存储在本地文件中,并且随着 Checkpoint 的周期异步地同步到远端可靠的分布式文件系统中。这样皆可以保证100%的本地性,各个 Sub-Task 只需要负责自己所属的那一部分 State 的保存,不需要通过网络互相传输 State,也不需要频繁的读写 HDFS,减少网络开支。
这里主要说明的是,我们 Flink 任务通过 yarn 运行在 dataManager 上,这个节点一般也是我们 dataNode 节点,那么保存在 hdfs 上的数据,这个 dataNode 也是有的,从而实现本地化。
在 Flink 需要作业重启的时候,从 HDFS 取回状态数据到本地,即可恢复运行。
而且在 Flink 中,有两种状态: Keyed State & Operator State。前者与每个键相关联,后者与每个算子的并行实例(Sub-Task)相关联。然后主要讨论的是关于 Keyed State 的缩放。
Keyed State 缩放
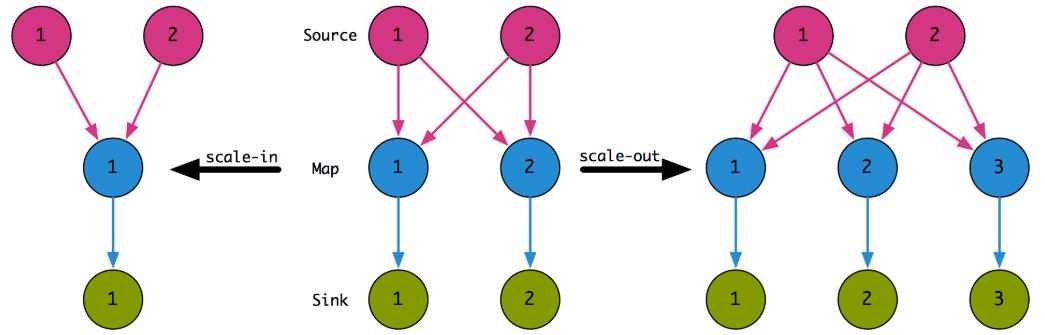
在实际使用 Flink 程序的时候,我们可能会更改某些算子的并行度(可能是因为计算的太慢、可能是上游的并行度调整、可能是其他某些原因),我们都要保存当前 State,然后修改代码的并行度,再从 Savepoint 处恢复。如果没有 State的话,我们进行 并行度修改是很方便的,只需要进行数据流的重新分配就行:
但如果加上了 State,我们就必须考虑怎么进行 State 的恢复:
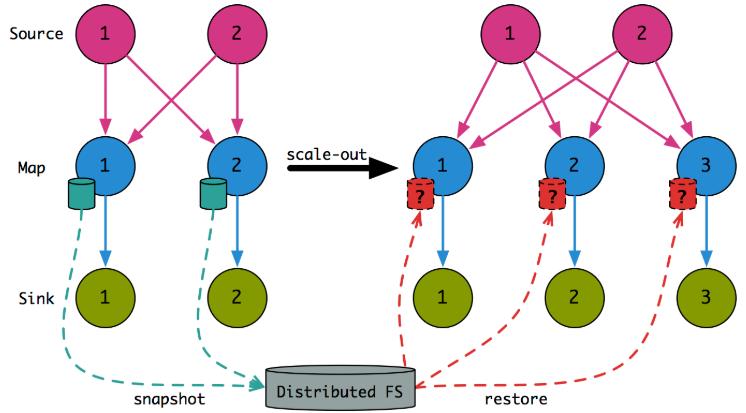
思考一下最开始的 Flink 分配 key 是通过 hash 取并发的余数进行(hash(key) % parallelism),然后分配到各个 SubTask 上去,但如果放缩后根据新的计算方式势必会有以下的问题:

根据对应图可以看出来,状态恢复基本就是随机读写了,这样会跨磁盘、跨网路,效率低下。并且放缩后,各个 SubTask 处理的 key 也发生了改变,降低了本地性。为了解决这个问题,FLINK-3755 对 Keyed State 专门引入了 KeyGroup & KeyGroupRange。
KeyGroup & KeyGroupRange
keyGroup
在上一章,其实我们讨论 Timer 的存储的时候,在 InternalTimeTimerManagerImpl 中提起过 KeyGroup & KeyGroupRange,我们说 KeyGroup 是 Keyed State 原子单位,而且 Flink 作业内 Key Group 的数量与 maxParallelism 相同,也就是说 keyGroup 的索引在 [ 0, maxParallelism - 1 ] 的区间范围内。 每个 subTask 都会处理一个到多个 KeyGroup,这些都会保存到 KeyGroupRange 中(subTask 中存储了 KeyGroupRange,也就是这个 subTask 需要处理哪些 keyGroupRange):
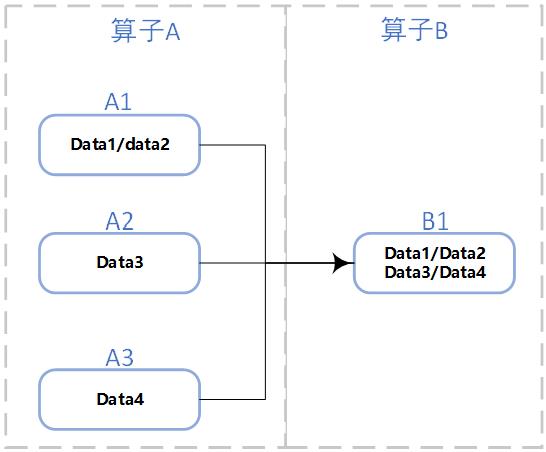
比如上图算子A可能是通过keyed后的数据,如果我当前的 maxParallelism 是3(现实不可能),那么意味着我有3个 keyGroup,对应的A1处理一个,A2处理一个,A3处理了一个;而算子B的B1处理的是三个 KeyGroup。

KeyGroupRange
KeyGroupRange 被创建在每个 subTask 中,记录着这个 subTask 需要处理哪些数据。
查看源码结构如下:
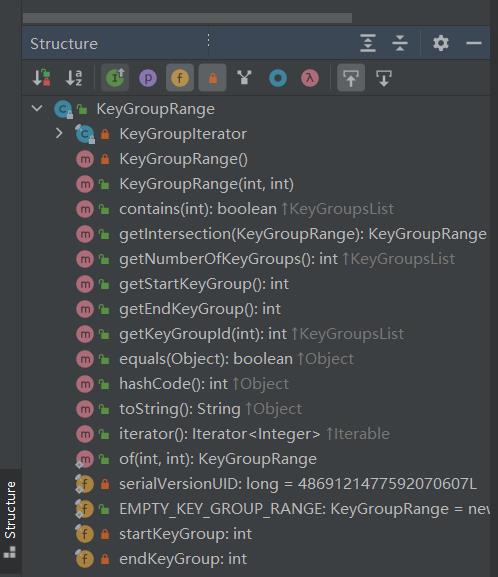
startKeyGroup 和 endKeyGroup 实际上是指 keyGroup的索引区间,而且是闭区间。所以我们可以知道 subTask 获取数据是通过连续的一段值来进行获取的。
那么:
- 如果决定一个 key 该分配在哪个 KeyGroup 中?
- 如果决定一个 SubTask 应该处理哪些 KeyGroup?
KeyGroupRangeAssignment
那就观察观察代码,然后讲解吧。
computeDefaultMaxParallelism()
这个类以前我们也有讲到过,在计算默认最大并行度的时候,就是通过这个类的 computeDefaultMaxParallelism 计算得出:

具体规则就是 将算子的并行度*1.5后,向上取整,到2的N次幂。如果范围在 2**7 到 2**15 之间,那么就中。如果超出范围,小了就取 128,大了就取32768。
所以 Flink 生成的 maxParallelism 位于128到32768之间,如果任务特别巨大,最好手动再加一点,如果后期升级超出 maxParallelism 的话,可能会导致无法从 Savepoint 处恢复。
computeKeyGroupForKeyHash()
获取当前元素所对应的 KeyGroup
根据 Key 取 hash 值,进行 murmurHash后,对 maxParallelism 进行求余,就是对应的 KeyGroup。
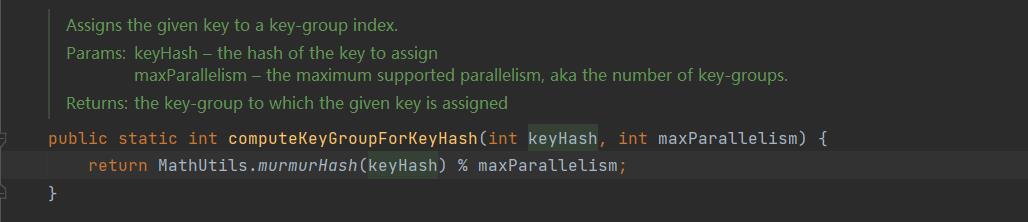
客官们可就迷糊了,这还不是已经取了一次 hashcode,为什么还要取 murmurhash呢?
通过源码可以看到 computeKeyGroupForKeyHash() 被两个地方所调用,从 assignToKeyGroup() 过来时已经进行了一次hashcode取值,是直接通过 object.hash 获得;另一个是通过 KeyGroupRangePartitioner.partition() ,传入是 key,为 int。
所以强词夺理的解释可以为,传入一个 Int 后再 reHash 的结果计算并行度。
computeOperatorIndexForKeyGroup()
获取 KeyGroup 所对应的 subTaskIndex,通过 KeyGroup * 当前并行度 / 最大并行度。
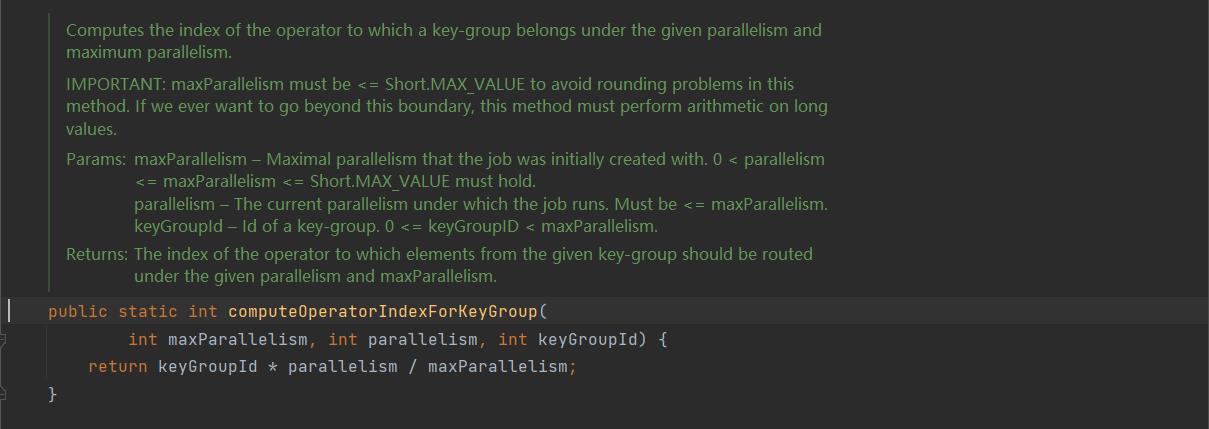
比如我们一般的 maxParallelism 为128,那么 keyGroupId 为 0~127,根据公式计算:
(0~127) * parallelism / 128 = [0, parallelism)
这里的 keyGroupId 也是对 maxParallelism 取余得到的,所以一定得到的结果是 [0, parallelism) 内的整数。
(n-1) * m / n = [0, m)
但是像以往所说,我们是通过 keyGroup 和 keyGroupRange 来进行存储的,所以还有另外一个计算。
computeKeyGroupRangeForOperatorIndex()
获取 subTask 的 KeyGroupRange。
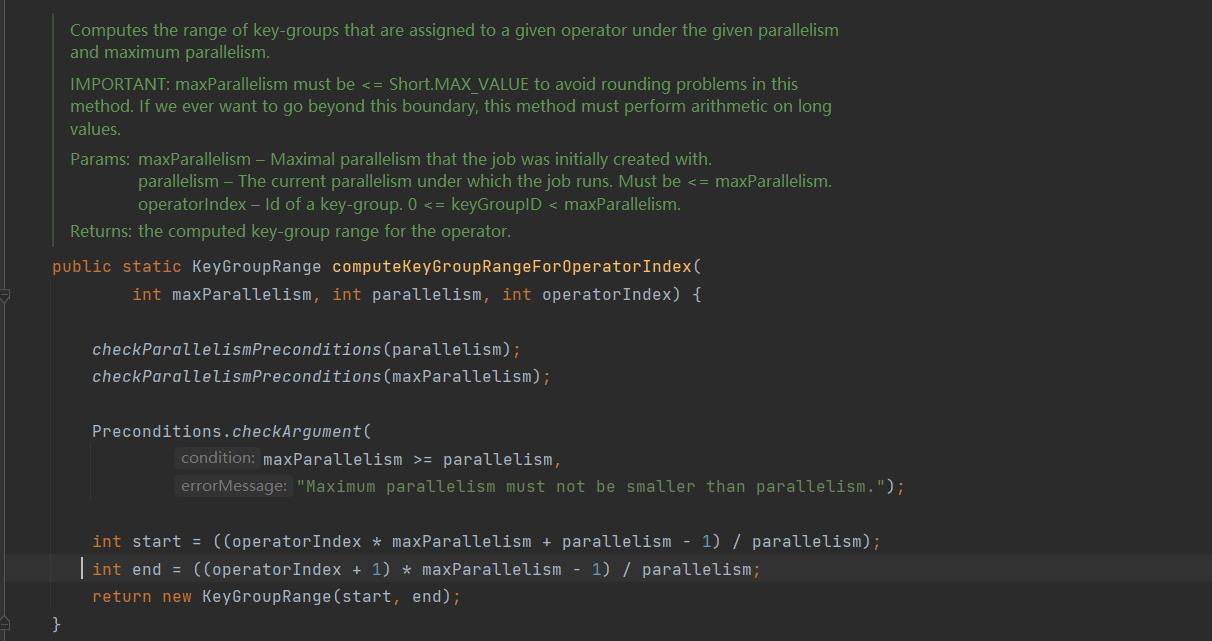
通过 maxParallelism 、 parallelism 、 operatorIndex 来计算这个 operator 对应的 keyGroupRange。
KeyGroupRange 主要的就是 start 与 end,所以计算出这两个就可以了:
start = ((operatorIndex * maxParallelism + parallelism - 1) / parallelism);
end = ((operatorIndex + 1) * maxParallelism - 1) / parallelism;
在进行注册调用的时候会进行 Operation KeyGroupRange 的计算,就会调用这个方法。
Rescale
在上述代码可以看到,我们连续的 hash 数据更可能由一个 Operator 进行使用,也更可能存储在本地上。如果我们重启 Flink 程序,并且将并发由3改成4,那么变化如下图:
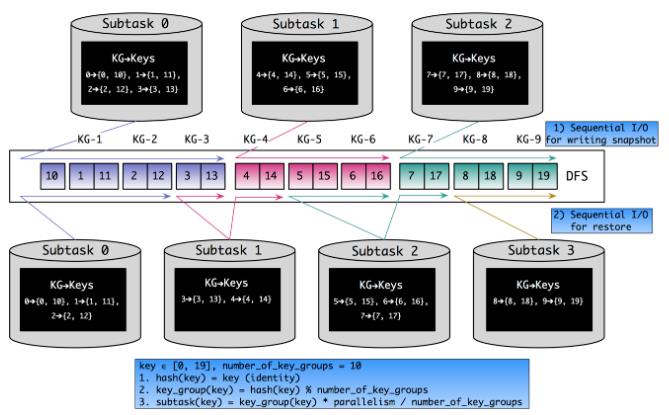
可以看到,将 KeyGroup 作为 Keyed State 的基本分配单位后,我们的本地性和随机读写、网络IO等问题都得到了不同程度的解决。而且必须要注意 maxParallelism 对于一个 Flink 程序的重要性。
总结
画图:
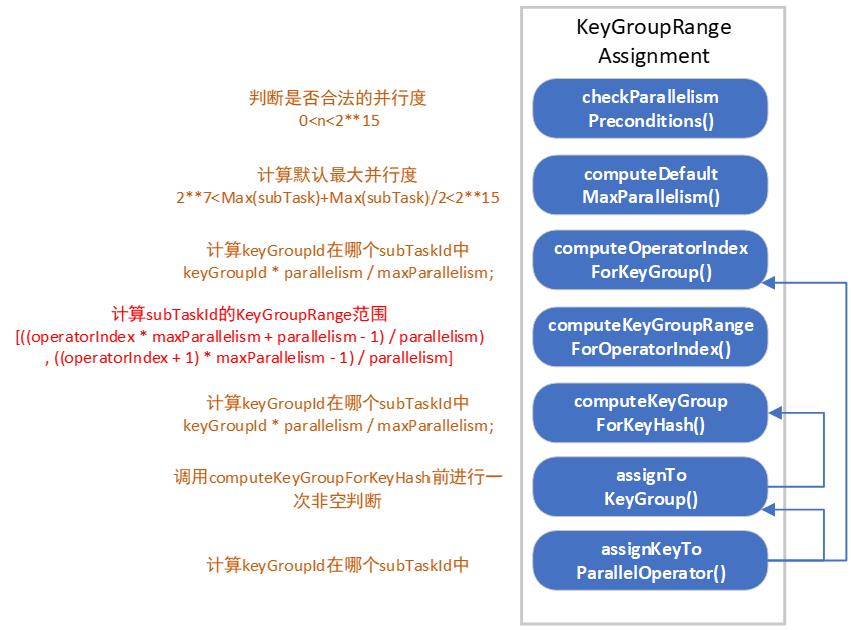
看完了,但貌似还是心有余悸,KeyGroupRangeAssignment 确实可以用来计算并行度、KeyGroupRange什么的,但在哪些地方进行注册的,keyed State 怎么跟随的?
done, keep on.
以上是关于Flink 的键组 KeyGroup 与 缩放 Rescale的主要内容,如果未能解决你的问题,请参考以下文章