Seata框架详解
Posted 敲代码的小小酥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Seata框架详解相关的知识,希望对你有一定的参考价值。
前言
一直想学习Seata分布式事务框架。查阅了B站课程,都不是太满意,因此自己查阅Seata官网进行学习。本篇文章记录学习官网的过程和心得:对官网讲解顺序进行调整和整合,更好理解Seata框架整体和细节。
中文官网地址:SEATA中文官网
SEATA原理
术语
TC (Transaction Coordinator) - 事务协调者: 维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器: 定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器: 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
**理解:**首先来看TM,是定义分布式事务范围的作用。类似于本地事务的begin…commit…rollback的作用。只不过其定义的是全局的分布式事务范围,这就需要知道有几个分布式分支的事务完成后才commit。
然后看TC,TC是具体的协调和执行者。它监控每个分布式分支事务执行成功与否,然后判断整体分布式事务是提交还是回滚。TM定义范围,TC用于联络各分支与TM的范围,推动总体分布式事务进程
RM是各分布式分支的监控器。监控各分支本地事务执行情况,然后通知给TC,同时驱动各分支本地事务的推进,是提交还是回滚。
总体概括就是:TM是一个分布式事务的发起者和终结者,TC负责维护分布式事务的运行状态,而RM则负责本地事务的运行
分布式事务执行流程

官网扒下来的图,借助此图解释一下SEATA执行分布式事务的流程,同时体会TC、TM和RM之间的关系和作用。
在上图中,涉及到四个微服务系统,分别是Business系统、Stock系统、Order系统和Account系统。当执行某个业务时,Business系统远程调用了Stock系统和Order系统,Order系统又远程调用了Account系统,相当于发生了三次远程调用,才执行完这个业务操作。而且这几个远程调用的方法要求具有原子性,即出现了分布式事务场景。
一:使用Seata框架,在Business系统发生的远程调用,所以Business是TM角色,定义分布式事务的范围,并向TC申请开启一个全局事务。TC生成一个全局事务并生成一个全局唯一的XID返回给TM。
二:TM获取到XID后,携带XID进行远程调用,XID在微服务链路中进行传递。
三:各分支事务获取到XID后,与TC进行通信,注册各分支本地事务,并执行本地事务,将执行结果(提交/回滚)提交给TC。
四:TM根据TC中记录的各分支事务的提交状态,发起全局事务的提交或回滚。
五:TC调度XID下所有分支事务进行提交或回滚操作。
以上就是SEATA执行分布式事务整体流程。
问题:
理解了上述过程后,会有几个问题在脑海中出现,
1,由上图可看到,TM和RM都与TC进行通信,那么TC到底是个什么东东?
2.RM执行各自分支的事务,加入有的分支事务提交了,有的分支事务回滚了,那么在第五步中,TC是要对所有分支事务进行回滚的,而执行成功的分支事务,如果再回滚回去呢?
这两个疑问会在下面的学习中得到解惑。
SEATA事务模式
Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
下面分别学习这几种事务模式特性和区别。
AT模式
AT模式是默认模式。
整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
提交异步化,非常快速地完成。
回滚通过一阶段的回滚日志进行反向补偿。
可以看到,AT模式通过回滚日志,来回滚提交成功后的事务。这也解答了上面问题中的第二条问题。具体是如何通过回滚日志回滚的呢?看下面的工作机制。
工作机制
seata为我们提供了日志回滚表,不同的数据库回滚表结构有差异,mysql数据日志回滚表结构如下:

建表语句:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
将这个表加入到各个分支事务系统的数据库中。
下面以product微服务系统为例,介绍seata中提交和回滚过程:
假设某个分布式事务业务中某个分支需要更改product表中数据,执行以下sql语句:
update product set name = 'GTS' where name = 'TXC';
一阶段:
一、首先,seata框架解析sql,得到 SQL 的类型(UPDATE),表(product),条件(where name = ‘TXC’)等相关的信息。
二、然后,根据要更新的数据,查询该条数据查询前的数据镜像,如下sql:
select id, name, since from product where name = 'TXC';
这样就得到了更改的这条数据更改之前的镜像,如下图:

三、执行业务sql语句,即update语句,更新数据
四、查询更改后的数据镜像,因为获取到数据的id,可以根据id查询更改后的数据:
select id, name, since from product where id = 1;
得到更新后的镜像:
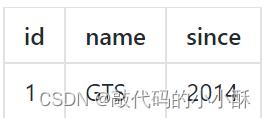
五、插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
"branchId": 641789253,
"undoItems": [
"afterImage":
"rows": [
"fields": [
"name": "id",
"type": 4,
"value": 1
,
"name": "name",
"type": 12,
"value": "GTS"
,
"name": "since",
"type": 12,
"value": "2014"
]
],
"tableName": "product"
,
"beforeImage":
"rows": [
"fields": [
"name": "id",
"type": 4,
"value": 1
,
"name": "name",
"type": 12,
"value": "TXC"
,
"name": "since",
"type": 12,
"value": "2014"
]
],
"tableName": "product"
,
"sqlType": "UPDATE"
],
"xid": "xid:xxx"
可以看出,里面记录了xid、branchId等事务相关的信息,还记录了sqlType、tableName等数据操作相关的信息,还记录了afterImage和beforeImage这些数据变化前后的信息。以此来保证后续回滚操作的正常执行。
六、向TC注册分支,申请product表中id为1的数据的全局锁。
七、本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。 在此前,本地数据一直没有提交,在这里才提交本地事务。undo log表数据也在事务内提交,如果提交不成功,也会回滚。
八、将本地事务执行结果汇报给TC。
这里一阶段就执行完毕了。一阶段主要做的工作是执行本地事务和undo 表数据,并将本地事务状态汇报给TC,是本地事务提交阶段。
二阶段:
二阶段即TC根据所有分支的本地事务的状态,决定全局分布式事务是提交还是回滚,然后通知各分支分布式事务的状态,让本地事务根据全局事务是提交还是回滚,来对各自本地事务执行后续的操作。这里分全局事务回滚和提交两种情况来看二阶段本地事务是如何执行的:
回滚:
加入在其他分支中,某个本地事务进行了回滚,则全局事务回滚。虽然product表事务执行成功了,但是也需要回滚,具体流程如下:
一、 product收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
二、通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
三、数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
四、根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
update product set name = 'TXC' where id = 1;
五、提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
提交:
如果全局事务执行成功,则TC也会给各分支发送提交的消息,此时,各分支主要是将undo log表中相关的日志数据删除操作。
问题:
在回滚操作的第三步,数据检查中,会检查现在的数据和本次事务中修改后的数据是否一致,如果一致,说明没有其他事务操作这条数据,如果不一致,说明其他事务修改过这条数据。此时,回滚操作就很复杂了。具体seata有哪些策略,在官网没介绍,这里先不深入研究,等实战中真遇到了,再研究。
写隔离
AT模式的写隔离是指,在第一阶段提交时,多个事务对同一条数据的写操作,是安全的。不会出现并发问题。而在第二阶段,其他事务或线程是可以对第一阶段的操作过的数据进行修改的,此时就没有隔离机制了。这种情况其实就是上面提到的回滚阶段的数据检查那个步骤的原因。
下面看一下第一阶段写隔离的机制是如何设计的:
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
这里出现了本地锁和全局锁。本地锁是指某个微服务实例中内部对某个资源的锁。如果是集群,则是对某个资源的分布式锁。这个本地锁是某个微服务对某个资源的锁定,都称之为本地锁。
全局索是seata框架为资源提供的锁。其主要是用于不同全局事务之间的锁定。本地锁锁的是某个资源。全局锁锁的是不同的全局事务。
下面举例说明:

如上图所示,两个分布式事务tx1和tx2都对同一个表的m列进行操作。tx1的线程先抢到数据库锁(执行update操作会有锁),此时的数据库锁就是本地锁。tx1执行完update语句后,会向TC申请一个全局锁,用于锁住这个事务。
申请完全局锁后,提交本地事务,数据库锁(本地锁)释放。
与此同时,tx2事务也要操作m列。因为tx1抢到了数据库锁,所以tx2一直无法执行update操作,知道tx1释放了数据库锁,tx2才会抢到这个数据库锁。
抢到数据库锁之后,执行tx2自己的update语句。执行完后,tx2也要申请这个数据的全局锁,才能提交本地事务。但是这个数据的全局锁,之前已经被tx1抢到了,所以tx2无法抢到这把锁,tx2就一直尝试抢锁。
直到tx1全局事务都提交了,那么tx1才会释放这个全局锁,此时,tx2才会获取到这把全局锁,然后继续往下执行tx2的本地事务:提交本地事务,释放数据库锁,等到tx2全局事务提交后,释放全局锁。
由上面的过程可知,不同分布式事务操作同一个数据,需要等前面的分布式事务执行成功,后面的分布式事务才能操作这条数据。这看起来就像单机事务一样,不会在事务没执行完之前改变数据库的数据。实现机制就是加入了全局锁的概念,用于锁住不同的全局事务,避免交叉修改数据。
说到这里,又有疑问了,既然前一个全局事务整体提交了,第二个全局事务才能修改这条数据。那前一个全局事务没提交,而是回滚了,那第二个全局事务肯定也没修改这条数据呀,为啥在回滚的时候还需要进行第三步操作,进行数据校验呢?
原因就是全局锁只是锁住了分布式事务之间对同一个数据的修改。如果有一个单机事务来修改这条数据,压根就没有注册全局锁这个过程,只有本地锁。那么这时就可以修改这条数据,不管全局事物的全局锁释放没释放。这时就出现了数据校验所说的那种情况。
接着上面的写隔离继续说,上图讲到的是前一个全局事务提交了的情况。如果前一个全局事务最终回滚了,写隔离又是如何实现的呢?看下图:
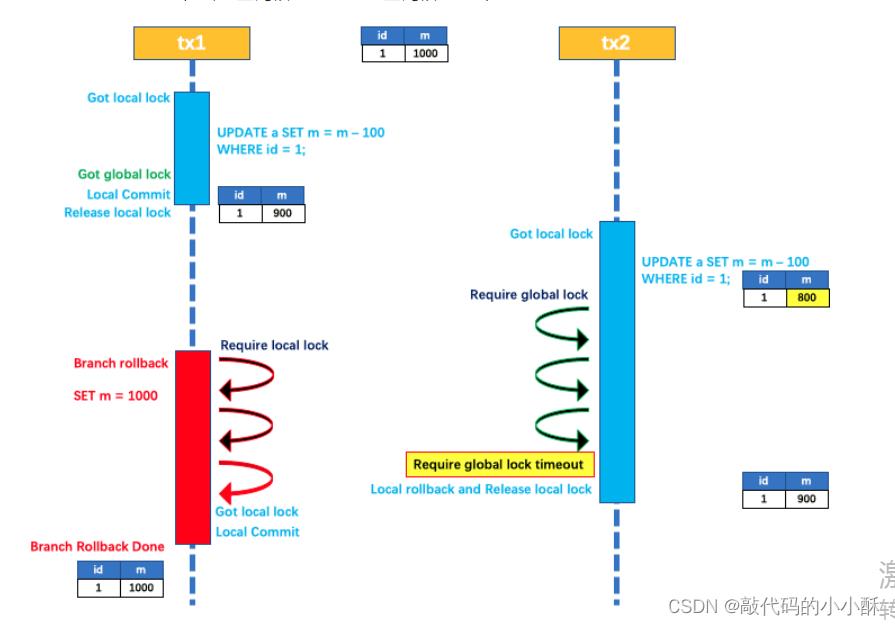
tx1抢到了本地锁,执行update语句,然后抢到全局锁,释放本地锁,提交本地事务。
tx1释放本地锁后,tx2抢到本地锁,执行update语句,并尝试获取全局锁,因为tx1持有全局锁,所以tx2一直尝试获取全局锁。
tx1全局事务最终回滚了,那么tx1对m列的操作也需要回滚,回滚m列就需要对m列进行update,需要持有m列的本地锁。但是m列的本地锁此时tx2持有的,所以tx1一直在尝试获取m列的本地锁。
现在的现象就是,tx2持有m列本地锁,但是没有全局锁,一直尝试获取全局锁。
tx1持有全局锁,但是没有m列的本地锁,一直尝试获取本地锁。很明显,这就形成了死锁问题。
针对这个问题,seata设计了获取全局锁重试次数机制,重试获取全局锁一定次数没有成功后,就会回滚本地事务,事务回滚了,本地锁也就释放了。即tx2一直尝试获取全局锁,到达次数后,tx2对m列的操作这个本地事务就回滚,释放了本地锁。
此时tx1就可以获取到本地锁,然后执行回滚操作。这样tx1就可以成功回滚了。
由此可以看出,当出现死锁时,seata框架优先让持有全局锁的事务进行数据的操作。这也符合事务的操作逻辑。因为先执行的事务先抢到全局锁,肯定保证先执行的全局事务完成后,再执行后面的全局事务。
总结:
由上面描述可知,AT模式是强一致性模式,相应性能会有一定影响。例如在前一个事务回滚时,加入第二个事务抢占了本地锁,那么第二个全局事务一直无法抢占全局锁导致事务回滚。这也会造成一定的使用上的影响。
TCC模式
对TCC的一个实现,需要手动定义三个接口,来实现分布式事务,详情可看TCC相关知识
Saga 模式
Saga模式是大牛提出的一篇论文,seata框架对其进行了实现。比较高深,看不太懂,这是一个弱一致性事务模式。
XA模式
XA模式是借助了数据库层面的XA协议实现的分布式事务机制。seata只是 在上面包装了一层,本质还是借助XA协议进行分布式事务控制。这里不再过多赘述,在分布式事务详解的博客中,已经讲解了XA协议。
其他
剩余seata具体使用和如何配置,部署等操作,在实操中参考官网即可。现在学了意义也不大。实操时又会忘了。
以上是关于Seata框架详解的主要内容,如果未能解决你的问题,请参考以下文章