如何使用机器学习自动修复bug: 数据处理和模型搭建
Posted Jtag特工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用机器学习自动修复bug: 数据处理和模型搭建相关的知识,希望对你有一定的参考价值。
如何使用机器学习自动修复bug: 数据处理和模型搭建
上一篇《如何使用机器学习自动修复bug: 上手指南》我们介绍了使用CodeBERT自动修复bug的操作方法。
估计对于很多想了解原理的同学来说,只知道训练的推理的命令太不过瘾了,根本不了解原理,而且也不知道如何去做改进。
这一篇我们开始介绍其中的细节。
一点点BERT模型的基础知识
首先复习一下上篇文章介绍的bug自动修复的原理。
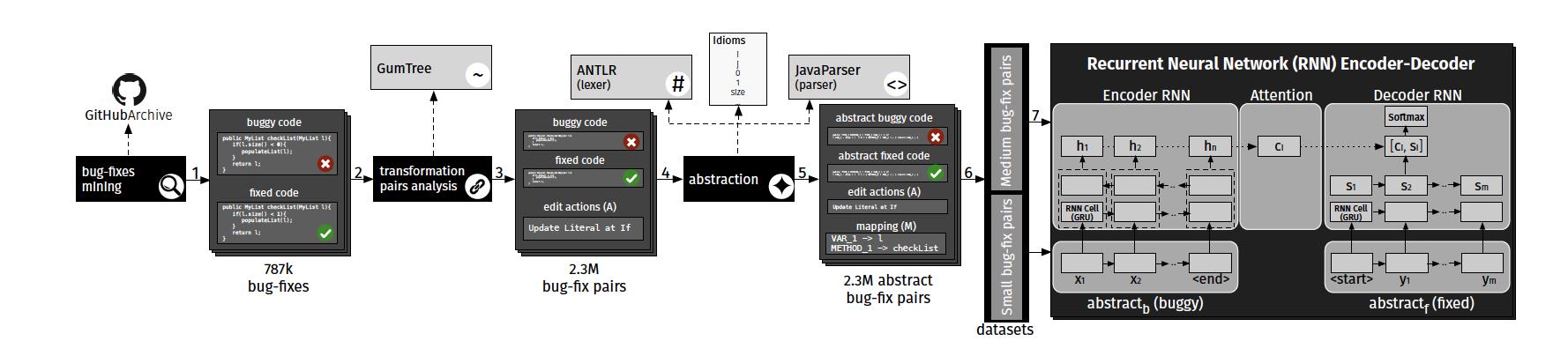
- 收集有bug的代码与修复代码的配对。
- 通过语法解析器变成更通用的抽象bug/修复代码对。
- 通过机器翻译的编码器-解码器结构去进行训练与推理。
原论文《An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation 》中使用的是RNN + Attention的结构。
自从BERT为代表的预训练模型被发明后,编码器一般都换成了预训练模型,解码器使用Transformer。
因为我们自动修复功能使用了CodeBERT模型,而这个模型是在BERT模型的基础上训练出来的。
我们还是简要科普下BERT模型。
在使用BERT模型之前,需要将文本或者代码数据转换成词嵌入的形式,如下图所示:

每一条语句的开始要以一个特殊符号[CLS]开始,几个子句之间以[SEP]来分隔。结束符不用标记。
HuggingFace的Transformers库已经为我们准备好了易用的库。
比如转换词嵌入的工作可以使用tokenizer.tokenize函数来实现。每个模型有自己的tokenizer。
CLS符号可以使用tokenizer.cls_token常量,SEP符号可以使用tokenizer.sep_token常量。
下面我们就可以用BERT的强大功能去解决问题了:
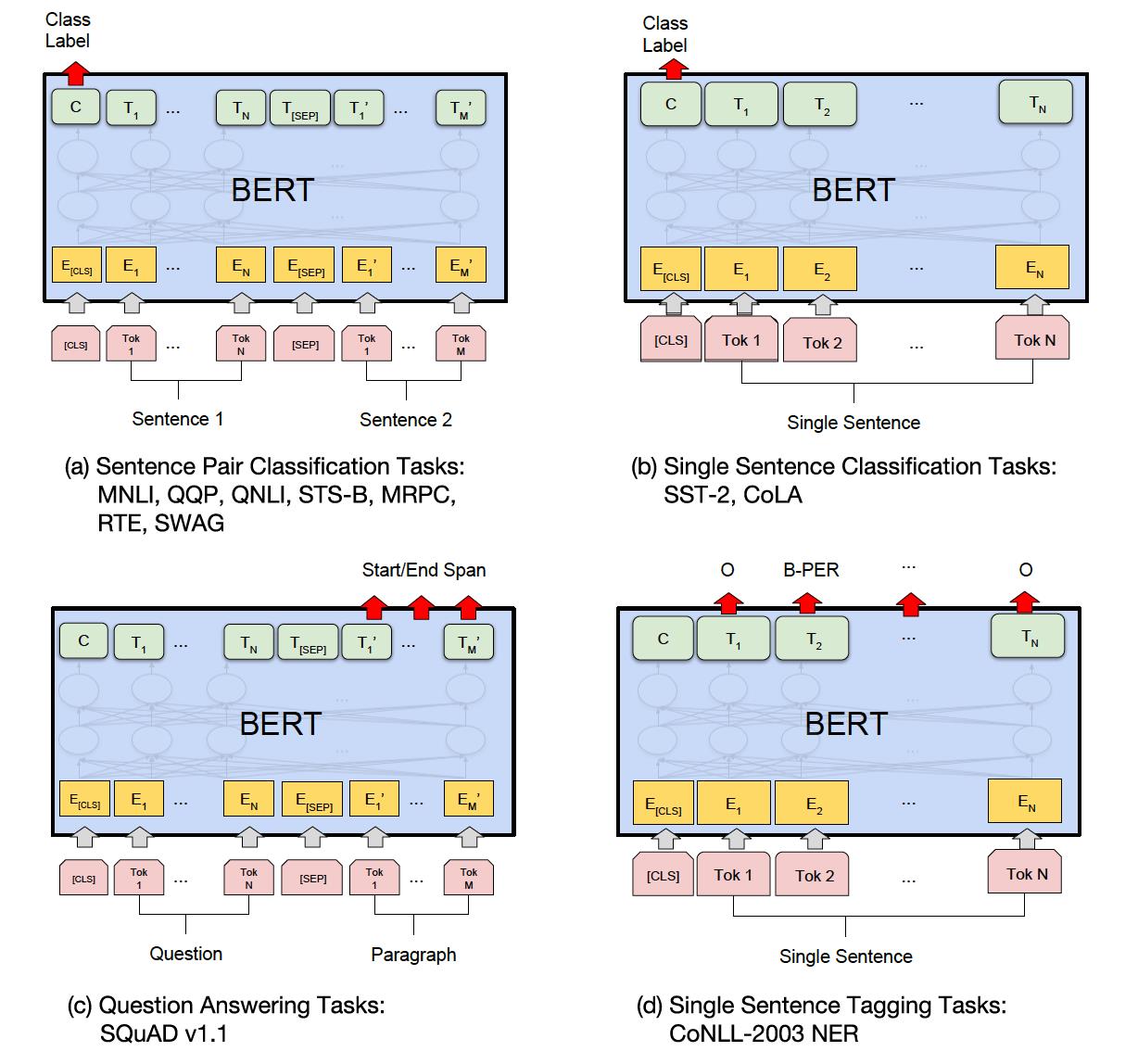
BERT可以用来处理两大类问题:句子对问题和单句问题。
句对问题再分为分类问题和问答类问题。
单句问题再分为分类问题和标签类问题。
句对的分类问题,我们以QQR任务为例,其目标是确定 Quora 上提出的两个问题在语义上是否相同。
问答类更容易理解了,根据训练的问答对,来回答新的问题。
单句分类,比如SST-2,是一个情感分析的问题,就是判断一段话是正面还是负面的情感。
我们把这些问题类比对代码上,比如我们判断两段代码是否相同,这就是代码克隆检测问题。
将源代码转成特征
有了上面一点基础知识之后,我们就可以看看上篇中我们做bug自动修复的原理了。
以上面的原理,我们第一步要做tokenize,我们来看看源代码的tokenize是如何实现的。
上一篇我们学习了训练的命令:
cd code
export pretrained_model=microsoft/codebert-base
export output_dir=./output
python run.py \\
--do_train \\
--do_eval \\
--model_type roberta \\
--model_name_or_path $pretrained_model \\
--config_name roberta-base \\
--tokenizer_name roberta-base \\
--train_filename ../data/small/train.buggy-fixed.buggy,../data/small/train.buggy-fixed.fixed \\
--dev_filename ../data/small/valid.buggy-fixed.buggy,../data/small/valid.buggy-fixed.fixed \\
--output_dir $output_dir \\
--max_source_length 256 \\
--max_target_length 256 \\
--beam_size 5 \\
--train_batch_size 16 \\
--eval_batch_size 16 \\
--learning_rate 5e-5 \\
--train_steps 100000 \\
--eval_steps 5000
不知道大家有没有疑惑,像这样--train_filename ../data/small/train.buggy-fixed.buggy,../data/small/train.buggy-fixed.fixed指定了两个文件作为训练集,模型是如何知道该怎么处理的呢?
答案在代码中:
if args.do_train:
# Prepare training data loader
train_examples = read_examples(args.train_filename)
train_features = convert_examples_to_features(train_examples, tokenizer,args,stage='train')
all_source_ids = torch.tensor([f.source_ids for f in train_features], dtype=torch.long)
all_source_mask = torch.tensor([f.source_mask for f in train_features], dtype=torch.long)
all_target_ids = torch.tensor([f.target_ids for f in train_features], dtype=torch.long)
all_target_mask = torch.tensor([f.target_mask for f in train_features], dtype=torch.long)
train_data = TensorDataset(all_source_ids,all_source_mask,all_target_ids,all_target_mask)
首先要从文件中将有bug和修复后的代码读出来:
def read_examples(filename):
"""Read examples from filename."""
examples=[]
assert len(filename.split(','))==2
src_filename = filename.split(',')[0]
trg_filename = filename.split(',')[1]
idx = 0
with open(src_filename) as f1,open(trg_filename) as f2:
for line1,line2 in zip(f1,f2):
examples.append(
Example(
idx = idx,
source=line1.strip(),
target=line2.strip(),
)
)
idx+=1
return examples
Example类的作用非常简单,就是索引号、源和目标三个字段的简单组合。
class Example(object):
"""A single training/test example."""
def __init__(self,
idx,
source,
target,
):
self.idx = idx
self.source = source
self.target = target
然后调用convert_examples_to_features函数将代码文本转换成token。
还记得BERT中要增加[CLS]和[SEP]符号的要求么:
def convert_examples_to_features(examples, tokenizer, args,stage=None):
features = []
for example_index, example in enumerate(examples):
#source
source_tokens = tokenizer.tokenize(example.source)[:args.max_source_length-2]
source_tokens =[tokenizer.cls_token]+source_tokens+[tokenizer.sep_token]
源代码是这样的:
public java.lang.String METHOD_1 ( ) return new TYPE_1 ( STRING_1 ) . format ( VAR_1 [ ( ( VAR_1 . length ) - 1 ) ] . getTime ( ) ) ;
转换成token之后:
['<s>', 'public', '_java', '.', 'lang', '.', 'String', '_M', 'ETHOD', '_', '1', '_(', '_)', '_', '_return', '_new', '_TYPE', '_', '1', '_(', '_STR', 'ING', '_', '1', '_)', '_.', '_format', '_(', '_V', 'AR', '_', '1', '_[', '_(', '_(', '_V', 'AR', '_', '1', '_.', '_length', '_)', '_-', '_1', '_)', '_]', '_.', '_get', 'Time', '_(', '_)', '_)', '_;', '_', '</s>']
BERT模型中需要的是ID,我们通过convert_tokens_to_ids将token转id:
source_ids = tokenizer.convert_tokens_to_ids(source_tokens)
source_mask = [1] * (len(source_tokens))
padding_length = args.max_source_length - len(source_ids)
source_ids+=[tokenizer.pad_token_id]*padding_length
source_mask+=[0]*padding_length
转换出来的效果是这样的:
source_ids: 0 15110 46900 4 32373 4 34222 256 40086 1215 134 36 4839 25522 671 92 44731 1215 134 36 20857 1862 1215 134 4839 479 7390 36 468 2747 1215 134 646 36 36 468 2747 1215 134 479 5933 4839 111 112 4839 27779 479 120 14699 36 4839 4839 25606 35524 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
然后我们要生成一个mask, 就是有值的地方是1,没值的全填0:
source_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
下面是针对修复的数据。首先,如果是测试集的话,自然就没有数据,需要模型推断出来;如果是训练集,则跟着训练的数据:
#target
if stage=="test":
target_tokens = tokenizer.tokenize("None")
else:
target_tokens = tokenizer.tokenize(example.target)[:args.max_target_length-2]
后面就是和缺陷代码一样的操作:
target_tokens = [tokenizer.cls_token]+target_tokens+[tokenizer.sep_token]
target_ids = tokenizer.convert_tokens_to_ids(target_tokens)
target_mask = [1] *len(target_ids)
padding_length = args.max_target_length - len(target_ids)
target_ids+=[tokenizer.pad_token_id]*padding_length
target_mask+=[0]*padding_length
数据准备好了之后,我们再用一个新类封装一下:
features.append(
InputFeatures(
example_index,
source_ids,
target_ids,
source_mask,
target_mask,
)
)
return features
InputFeatures类也是个简单的封装:
class InputFeatures(object):
"""A single training/test features for a example."""
def __init__(self,
example_id,
source_ids,
target_ids,
source_mask,
target_mask,
):
self.example_id = example_id
self.source_ids = source_ids
self.target_ids = target_ids
self.source_mask = source_mask
self.target_mask = target_mask
下面回到训练的主函数,将 id 和 mask 都转换成 PyTorch 的向量:
all_source_ids = torch.tensor([f.source_ids for f in train_features], dtype=torch.long)
all_source_mask = torch.tensor([f.source_mask for f in train_features], dtype=torch.long)
all_target_ids = torch.tensor([f.target_ids for f in train_features], dtype=torch.long)
all_target_mask = torch.tensor([f.target_mask for f in train_features], dtype=torch.long)
train_data = TensorDataset(all_source_ids,all_source_mask,all_target_ids,all_target_mask)
好,数据这部分基本上大功告成了,下面我们看模型部分。
模型
模型上我们采用和机器翻译差不多的Seq2Seq模型,按照惯例我们也采用编码器-解码器的结构。
编码器我们采用的就是微软的CodeBERT预训练模型,这是在命令行参数时我们指定的:
#budild model
encoder = model_class.from_pretrained(args.model_name_or_path,config=config)
还记得命令行里我们用的model_name_or_path 参数吧:
--model_name_or_path microsoft/codebert-base
我们尝试别的编码器的时候,就把这个参数替换掉就好了。
然后解码器我们选择一个6层的 TransformerDecoder 解码器:
decoder_layer = nn.TransformerDecoderLayer(d_model=config.hidden_size, nhead=config.num_attention_heads)
decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)
model=Seq2Seq(encoder=encoder,decoder=decoder,config=config,
beam_size=args.beam_size,max_length=args.max_target_length,
sos_id=tokenizer.cls_token_id,eos_id=tokenizer.sep_token_id)
编码器这部分负责有bug的代码的处理,这部分不管是训练还是推理部分都是一样的。输入给encoder的参数是源代码的id和mask:
def forward(self, source_ids=None,source_mask=None,target_ids=None,target_mask=None,args=None):
outputs = self.encoder(source_ids, attention_mask=source_mask)
encoder_output = outputs[0].permute([1,0,2]).contiguous()
针对训练的情况,解码器部分使用的不是BERT模型,而是普通的Transformer层,这部分的主要作用是要计算训练目标的交叉熵。
细节我们后面会继续深入,这里大家先有个概念:
if target_ids is not None:
attn_mask=-1e4 *(1-self.bias[:target_ids.shape[1],:target_ids.shape[1]])
tgt_embeddings = self.encoder.embeddings(target_ids).permute([1,0,2]).contiguous()
out = self.decoder(tgt_embeddings,encoder_output,tgt_mask=attn_mask,memory_key_padding_mask=(1-source_mask).bool())
...
outputs = loss,loss*active_loss.sum(),active_loss.sum()
return outputs
下面是推理的部分,将针对每一个source_id进行推理,但是推理的输入是 encoder_output,也就源代码的 tokens 经过 CodeBERT 进行编码之类的结果。
else:
#Predict
preds=[]
zero=torch.cuda.LongTensor(1).fill_(0)
for i in range(source_ids.shape[0]):
context=encoder_output[:,i:i+1]
context_mask=source_mask[i:i+1,:]
...
再后面就是 Beam Search 的过程。做过生成的同学对此应该比较熟悉了,后面我们会详细看下细节,其实细节也不多。
小结
通过本文,我们对于自动修复bug的数据处理、模型训练和推理的大致过程应该有了一个初步地了解。
在此处,大家可以思考下,如果你要解决的不是Java的问题,而是其它语言的问题,如何创建你自己的数据集。
如果还有对技术细节感兴趣的同学,后面我们还会继续讨论细节。
以上是关于如何使用机器学习自动修复bug: 数据处理和模型搭建的主要内容,如果未能解决你的问题,请参考以下文章