spark.mllib源码阅读-分类算法5-GradientBoostedTrees
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-分类算法5-GradientBoostedTrees相关的知识,希望对你有一定的参考价值。
Gradient-Boosted Trees(GBT或者GBDT) 和 RandomForests 都属于集成学习的范畴,相比于单个模型有限的表达能力,组合多个base model后表达能力更加丰富。
关于集成学习的理论知识,包括GBT和Random Forests的一些比较好的参考资料:
周志华教授的"Ensemble Methods: Foundations and Algorithms",系统的介绍了集成学习的理论及方法
Greedy Function Approximation: A GradientBoosting Machine
Stochastic GradientBoosting,Spark GBT实现所参考的算法
GBT和Random Forests二者的区别:
二者的理论思想在spark.mllib源码阅读-bagging方法中从模型的方差和偏差的角度做了一些简要的介绍,在Spark官方文档上也有一段关于二者优劣的描述:
1、GBT比RandomForests的训练成本更高,原因在于GBT中各个模型以序列串行的方式进行训练,通常我们说的并行GBT是指base model的并行训练,各个base model之间是无法做到并行的。而Random Forests
中各个子模型之间可以做到并行化。
2、Random Forests的base model越多越有助于降低过拟合,而GBT中base model越多会提高过拟合的程度。
3、二者训练的时间成本不同,因此调参的成本不同。有限的时间内Random Forests可以实验更多的参数组合。
4、通常来看,Random Forests的base model会得到一棵规模适中的树,而GBT为了降低在basemodel数量多时引发的过拟合,会限制其base model的规模。
下面来看看Spark中GBT的实现过程,主要包括3部分:GBT模型、GBT参数配置、GBT训练算法:
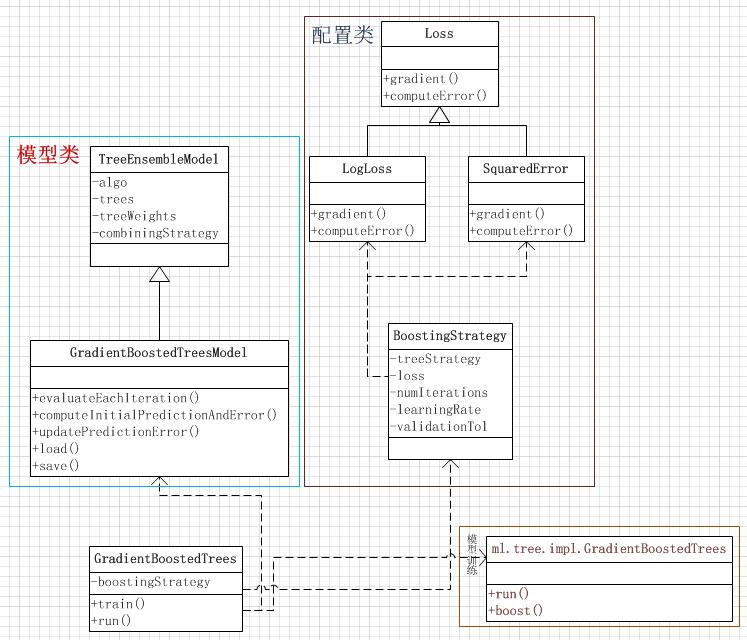
GradientBoostedTrees:
GBT的实现过程由GradientBoostedTrees类驱动并向用户暴露模型的训练方法。GradientBoostedTrees的2个关键方法是train和run,在run中,根据用户定义的模型配置类boostingStrategy来调用ml包下的GradientBoostedTrees类进行模型的训练,最后根据训练得到的参数来新建一个GradientBoostedTreesModel:
def train(
input: RDD[LabeledPoint],
boostingStrategy: BoostingStrategy): GradientBoostedTreesModel =
new GradientBoostedTrees(boostingStrategy, seed = 0).run(input)
def run(input: RDD[LabeledPoint]): GradientBoostedTreesModel =
val algo = boostingStrategy.treeStrategy.algo
//import org.apache.spark.ml.tree.impl.GradientBoostedTrees => NewGBT
val (trees, treeWeights) = NewGBT.run(input.map point =>
NewLabeledPoint(point.label, point.features.asML)
, boostingStrategy, seed.toLong)
new GradientBoostedTreesModel(algo, trees.map(_.toOld), treeWeights)
GradientBoostedTreesModel:
GradientBoostedTreesModel用来保存训练后的模型,其继承自TreeEnsembleModel。各个Base model保存在trees数组中,每个base model的权重在treeWeights数组中,
其父类TreeEnsembleModel实现的predict方法即是对各个base model的预测值加权treeWeights 得到最终的预测值。
class GradientBoostedTreesModel @Since("1.2.0") (
@Since("1.2.0") override val algo: Algo, //模型算法:分类 or 回归
@Since("1.2.0") override val trees: Array[DecisionTreeModel], //base model的数组
@Since("1.2.0") override val treeWeights: Array[Double]) //每个base model的权重
extends TreeEnsembleModel(algo, trees, treeWeights, combiningStrategy = Sum)BoostingStrategy
GBT的配置信息类,可配置的信息包括
treeStrategy:base tree的配置信息
Loss:损失函数,默认参数为2分类问题用LogLoss, 回归问题用SquaredError
numIterations:GBT的迭代次数,默认值为100
learningRate:学习速率,默认值为0.1
validationTol:通过验证集判断训练终止的条件:验证集上历史最小的残差 - 验证集当前残差 < validationTol*max(验证集当前残差, 0.01) 即提前终止训练
在训练GBT时,base tree的参数设置也很重要,base tree的参数由Strategy类维护,Strategy的默认值如下,在训练GBT时,务必要重新设置Strategy的值,这里我对可以设定的值都做了备注,方便初次使用的同学进行调参:
@Since("1.0.0") @BeanProperty var algo: Algo,//算法的类别:分类还是回归 Classification、Regression
@Since("1.0.0") @BeanProperty var impurity: Impurity,//计算信息增益的准则 分类基尼指数、信息增益 回归impurity.Variance
@Since("1.0.0") @BeanProperty var maxDepth: Int, //树的最大深度
@Since("1.2.0") @BeanProperty var numClasses: Int = 2,//类别数
@Since("1.0.0") @BeanProperty var maxBins: Int = 32,//连续特征离散化的分箱数
@Since("1.0.0") @BeanProperty var quantileCalculationStrategy: QuantileStrategy = Sort,//计算分裂点的算法,待定
@Since("1.0.0") @BeanProperty var categoricalFeaturesInfo: Map[Int, Int] = Map[Int, Int](),//存储每个分类特征的值数目
@Since("1.2.0") @BeanProperty var minInstancesPerNode: Int = 1,//子结点拥有的最小样本实例数,一个终止条件
@Since("1.2.0") @BeanProperty var minInfoGain: Double = 0.0,//最小的信息增益值,这个应该是用来控制迭代终止的
@Since("1.0.0") @BeanProperty var maxMemoryInMB: Int = 256,//聚合使用的内存大小。待定
@Since("1.2.0") @BeanProperty var subsamplingRate: Double = 1,//用于训练数据的抽样率
@Since("1.2.0") @BeanProperty var useNodeIdCache: Boolean = false,//待定
@Since("1.2.0") @BeanProperty var checkpointInterval: Int = 10 //checkpoint
模型的损失函数在BoostingStrategy类中自动设置,在二分类模型中损失函数被定义为LogLoss(对数损失函数)、在回归问题中损失函数被定义为SquaredError(平方损失函数)。在Spark2.1.0版本中还没有实现对多分类GBT的损失函数及多分类GBT模型。对于自定义损失函数,需要继承org.apache.spark.mllib.tree.loss.Loss这个类,并覆写gradient和computeError方法。
GradientBoostedTrees:
GradientBoostedTrees类是Spark训练GBT模型参数的类,模型的训练主要分为2步:1、将分类问题转化为回归问题,在GradientBoostedTrees的run方法中完成:
def run(
input: RDD[LabeledPoint],
boostingStrategy: OldBoostingStrategy,
seed: Long): (Array[DecisionTreeRegressionModel], Array[Double]) =
val algo = boostingStrategy.treeStrategy.algo
//都转化为回归问题
algo match
case OldAlgo.Regression => GradientBoostedTrees.boost(input, input, boostingStrategy, validate = false, seed)
case OldAlgo.Classification =>
// Map labels to -1, +1 so binary classification can be treated as regression.
val remappedInput = input.map(x => new LabeledPoint((x.label * 2) - 1, x.features))
GradientBoostedTrees.boost(remappedInput, remappedInput, boostingStrategy, validate = false, seed)
case _ => throw new IllegalArgumentException(s"$algo is not supported by gradient boosting.")
2、问题统一转化为回归问题后,调用GradientBoostedTrees的boost进行参数的训练,看一下整个训练过程的核心代码(在源码的基础上有删减):
// Initialize gradient boosting parameters
val numIterations = boostingStrategy.numIterations //总的迭代次数,决定了生成
val baseLearners = new Array[DecisionTreeRegressionModel](numIterations) //保存每次迭代的base模型的数组
val baseLearnerWeights = new Array[Double](numIterations)//模型权重?
val loss = boostingStrategy.loss //定义的损失函数
val learningRate = boostingStrategy.learningRate
// Prepare strategy for individual trees, which use regression with variance impurity.
val treeStrategy = boostingStrategy.treeStrategy.copy
val validationTol = boostingStrategy.validationTol
treeStrategy.algo = OldAlgo.Regression //org.apache.spark.mllib.tree.configuration.Algo => OldAlgo
treeStrategy.impurity = OldVariance
treeStrategy.assertValid()
// Cache input
val persistedInput = if (input.getStorageLevel == StorageLevel.NONE)
input.persist(StorageLevel.MEMORY_AND_DISK)
true
else
false
// Prepare periodic checkpointers 定期Checkpointer
val predErrorCheckpointer = new PeriodicRDDCheckpointer[(Double, Double)](
treeStrategy.getCheckpointInterval, input.sparkContext)
val validatePredErrorCheckpointer = new PeriodicRDDCheckpointer[(Double, Double)](
treeStrategy.getCheckpointInterval, input.sparkContext)
val firstTree = new DecisionTreeRegressor().setSeed(seed)
//实际是用随机森林训练的一棵树,GBT中树的深度通常较小
//RandomForest.run(data, oldStrategy, numTrees = 1, featureSubsetStrategy = "all", seed = $(seed), instr = Some(instr), parentUID = Some(uid))
val firstTreeModel = firstTree.train(input, treeStrategy)
val firstTreeWeight = 1.0
baseLearners(0) = firstTreeModel
baseLearnerWeights(0) = firstTreeWeight
//(预测值,误差值)
//如改成多分类的话应该是(list<pred>, list<Error>) 即每棵树的预测值和误差值
var predError: RDD[(Double, Double)] =
computeInitialPredictionAndError(input, firstTreeWeight, firstTreeModel, loss)
predErrorCheckpointer.update(predError)
var validatePredError: RDD[(Double, Double)] =
computeInitialPredictionAndError(validationInput, firstTreeWeight, firstTreeModel, loss)
if (validate) validatePredErrorCheckpointer.update(validatePredError)
var bestValidateError = if (validate) validatePredError.values.mean() else 0.0
var bestM = 1
var m = 1
var doneLearning = false
while (m < numIterations && !doneLearning)
// Update data with pseudo-residuals
//predError (预测值,误差值) 预测值是前m-1轮的预测值之和,误差值为lable-预测值
//如改成多分类的话 此时该样本的loss即可以用logitloss来表示,并对f1~fk都可以算出一个梯度,f1~fk便可以计算出当前轮的残差,供下一轮迭代学习。
val data = predError.zip(input).map case ((pred, _), point) =>
LabeledPoint(-loss.gradient(pred, point.label), point.features)//
val dt = new DecisionTreeRegressor().setSeed(seed + m)
val model = dt.train(data, treeStrategy)//训练下一个base model
// Update partial model
baseLearners(m) = model
// Note: The setting of baseLearnerWeights is incorrect for losses other than SquaredError.
// Technically, the weight should be optimized for the particular loss.
// However, the behavior should be reasonable, though not optimal.
// 这里learningRate是一个固定值,没有使用shrinkage技术
baseLearnerWeights(m) = learningRate // learningRate同时作为model的权重
predError = updatePredictionError(
input, predError, baseLearnerWeights(m), baseLearners(m), loss)
predErrorCheckpointer.update(predError)
if (validate) //验证集,验证是否提前终止训练
// Stop training early if
// 1. Reduction in error is less than the validationTol or
// 2. If the error increases, that is if the model is overfit.
// We want the model returned corresponding to the best validation error.
validatePredError = updatePredictionError(
validationInput, validatePredError, baseLearnerWeights(m), baseLearners(m), loss)
validatePredErrorCheckpointer.update(validatePredError)
val currentValidateError = validatePredError.values.mean()
if (bestValidateError - currentValidateError < validationTol * Math.max(
currentValidateError, 0.01))
doneLearning = true
else if (currentValidateError < bestValidateError)
bestValidateError = currentValidateError
bestM = m + 1
m += 1
GBT的训练是一个串行的过程,base treemodel在前一轮迭代残差的基础上逐棵生成。每次生成一棵树之后需要更新整个数据集的残差,再进行下一轮的训练。在数据集规模较大,并且迭代轮次比较多时,训练比较耗时,这在一定程度上增加了模型调参的成本。
截至Spark2.0.0,Spark的GBT模型比较初级,在分类问题上目前只支持2分类问题,梯度下降的过程控制也比较简单,难于适应一些精度要求高的的机器学习任务,因此目前版本下的Spark来做GBT模型并不是一个好的选择。相比较而言,XGBOOST是一个更好的选择,当然,有条件的情况下顺着Spark GBT的思路做一些改进也能达到接近的效果。
以上是关于spark.mllib源码阅读-分类算法5-GradientBoostedTrees的主要内容,如果未能解决你的问题,请参考以下文章