「学习笔记」3.23代码学习
Posted stars_cj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「学习笔记」3.23代码学习相关的知识,希望对你有一定的参考价值。
老师这两天给留了一道题,研究了几天,也没写出来,想想可能太难了,还是先刷简单的题吧。
老师留的题目是这样的:若干个城市,找到其中m个点,这m个点的特征是,所有的城市都可以到这m个点中距离自己最近的点距离小于a,找到这样的m个点。这种题目类似于几个城市中寻找物流点。
主要思路是考虑从最小生成树开始,这m个点是最小生成树中的某几个结点。后来老师可能觉得有点难度,让我先把最小生成树写出来,然后……然后……我就写不出来了。网上源码很多,想要自己写,最小生成树主要是有两个算法,prime,kruscal,这两个算法是很好理解,但是我在用python实现的时候总感觉思路理不清,这也是我现在写代码最困难的,就是思路不清。
下面是我憋了两天写的,但是不对,我暂时放弃了,过几天再回过头来看。
#encoding:utf8
import numpy as np
#输入
# vertex=raw_input().split(' ') #定义图的顶点,输入格式0 1 2 3 4 5……顶点相当于矩阵下标或是矩阵索引
# graph_weight=[] #定义图的邻接矩阵 图的邻接矩阵未相邻的点及对角线的值均为0
# for i in range(0,len(vertex)):
# graph_weight.append(raw_input().split(' ')) #输入格式矩阵一行之间用空格分格,换列回车 取得邻接矩阵
# graph_weight=np.array(graph_weight,dtype=int) #输入时解释为str,此处将其更改为int
#定义prime算法
def prime(graph_weight):
vertex=map(str,range(0,len(graph_weight))) #定义图的顶点,顶点为string
print 'vertex:' vertex
vertex_tree=vertex[0] #定义最小生成树顶点集合,从0开始矩阵下标
print 'vertex_tree:' vertex_tree
graph_weight_tree=[] #定义最小生成树邻接矩阵,prime算法是从任意点出发,此算法定义从0点出发
while not(vertex_tree==vertex): #最小生成树遍历所有顶点后结束循环
for i in range(0,len(vertex_tree)):
for j in range(0,len(vertex)):
#if graph_weight[i][j]>0:
min_weight=min(graph_weight[i]) #min(graph_weight[i]) 取与第i个顶点相邻的所有顶点中的最小值
graph_weight_index=graph_weight.index(min_weight) #graph_weight.index()取第i个点与其相邻结点中最小值的索引
vertex_tree.append(graph_weight_index) #vertex_tree.append()将其最小值的邻接点加入最小生成树的顶点中
graph_weight_tree[j][graph_weight_index]=min_weight #将权值加入到最小生成树的矩阵里
min_weight=0 #在原邻接矩阵中将取出的最小值置为0
return graph_weight_tree
l1=[0,6,1,5,0,0]
l2=[0,0,5,0,0,0]
l3=[0,0,0,5,6,4]
l4=[0,0,0,0,5,2]
l5=[0,0,0,0,0,6]
l6=[0,0,0,0,0,0]
l=[l1,l2,l3,l4,l5,l6]
print prime(l)继续刷acmcoder上的题
2023 平均成绩
#encoding:utf8
#求平均成绩
##思路:
##正式答案
import numpy as np
l1=raw_input('请输入学生数量和课程数量: ').split(' ')
l1=map(int,l1)
l2=[]
for i in range(0,l1[0]):
l2.append(raw_input().split(' '))
l2=np.array(l2,dtype=int)
student_avg=np.average(l2,axis=1)
course_avg=np.average(l2,axis=0)
print l2
print course_avg
comp=l2>=course_avg
#print comp
print len(filter(lambda x:x.all(),comp))
##寻找思路所写
# l1=raw_input('请输入学生数量和课程数量: ').split(' ')
# l1=map(int,l1)
# l2=[]
# for i in range(0,l1[0]):
# l2.append(raw_input().split(' '))
# #l2=np.array(l2,dtype=int)
#print l2
# student_avg=np.sum(l2,axis=1,dtype=float)/l1[0]
# #print student_avg
# course_avg=np.sum(l2,axis=0,dtype=float)/l1[1]
# #print course_avg
# #我想将学生成绩与课程成绩做差,然后找到矩阵中行大于0的,再计数,但是比较麻烦,可以直接比较
# l3=l2-course_avg
# print l3
# l1=[2,2]
# l2=np.array([[2,3],[4,5]])
# student_avg=np.average(l2,axis=1)
# course_avg=np.average(l2,axis=0)
# print l2
# print course_avg
# comp=l2>=course_avg
# print comp
# print len(filter(lambda x:x.all(),comp))
##之前就是不知道该怎么将矩阵的行相加或列相加,才找的numpy这个库,但是觉得这个循环还是应该要知道,
##又重新考虑如何表示
l1=[2,2]
l2=np.array([[2,3],[4,5]])
l3=[] #行相加
sum=l2[0][0]
for i in range(0,l1[0]):
sum=0 #每次sum求完之后要归零,要不会一直加
for j in range(0,l1[1]):
sum=sum+l2[i][j]
l3.append(sum)
print l3
l4=[] #列相加
for i in range(0,l1[1]):
sum=0
for j in range(0,l1[0]):
sum=sum+l2[j][i] #列相加需要注意i,j的位置
l4.append(sum)
print l4
2025 查找最大元素
#encoding:utf8
#查找最大元素
##思路:python可以直接对字母进行比较,所以考虑是逐一比较,出现最大的加(max)
##首先找到最大值 ,然后想怎么能够在最大值后面加(max),找到个函数insert(index,插入内容),再考虑
##index(要找到的))这个函数,是找到元素所在的位置,但是这时候出现问题了,这里的index()只取了第一个
##最大值的位置,但题目要求将所有的最大值后面都要加(max)
##后来又考虑用替换的函数replace()
##正式答案
s=raw_input()
max_str=s[0]
for i in s:
if i>=max_str:
max_str=i
print s.replace(max_str,max_str+'(max)')
##v如下为寻找思路所写
#s=list(raw_input())
# s='xxxxx'
# s=list(s)
# # print s.index('c')
# # s.insert(s.index('c'),'(max)')
#
# max_str=s[0]
# #
# # for i in s:
# # if i>=max_str:
# # max_str=i
# for i in enumerate(s):
# if i>=max_str:
# max_str=i
# print max_str
#print s.index(max_str)
#
# print s.replace(max_str,max_str+'(max)')
#s.insert(s.index(max_str)+1,'(max)')
#print s
2026首字母大写
#encoding:utf8
#首字母变大写
l=raw_input()
l=l.split(' ')
#l=['i','like','acm']
s=[]
for i in l:
s.append(i.capitalize()) #str.capitalize()要注意是对str首字母大写
s=' '.join(s) #将s中的元素以空格合并
print s
2027统计元音
#encoding:utf8
##统计元音
##目前存在的问题:
##1\\题意要求最后一组计数出来不输出空格,以下代码输出还是有空格。3.23
##2\\按测试出来结果有一个字母o计数不对,第二组测试实例o应为0,以下代码输出为1 3.23
n=int(raw_input()) #输入测试实例个数
l=[]
for i in range(0,n): #分行输入测试实例
l.append(raw_input())
#测试给定输入
# n=2
# l=['aeiou','my name is ignatius']
vowel=['a','e','i','o','u']
#思路1:对列表中所有字母计数,输出元音字母数字
str_num= #定义对所有元素计数的字典
for i in l: #在l中每一个字符串i循环
for j in i: #在字符串i中对每一个元素j循环
str_num[j]=i.count(j) #对元素j计数,并加入str_num中
for k in vowel:
vowel_num=str_num[k] #在str_num中找到vowel中的元音字母的值,赋给vowel_num
print k,':',vowel_num
print '\\n'
#统计元音 还没做完 做不出来了 以下写的时间为3.21
##思路1:创建字典,字典键值为元音,如果输入元素的值等于字典的key,则计数+1,最后输出字典,对于输入
##的list中的元素如何一一与字典只的键值做比较,在循环时发生字典键值不能迭代的问题
# def count_vowel(l):
# vowel=['a','e','i','o','u']
# vowel_num=.fromkeys(vowel)
# count=0
# for i in l:
# if i in vowel_num:
# count+=1
# vowel_num[i]=count
#
# return vowel_num
# l1=list('aeiou')
# l2=list('my name is ignatius')
# s=[l1,l2]
##思路2:将输入list所有字母计数,输出其中元音字母的重复次数
##思路21 库函数计数
# from collections import Counter
# for i in s:
# print Counter(i)
##思路22 字典计数
# def count_num(l):
# countnum=
# for i in l:
# if l.count(i)>=1:
# countnum[i]=l.count(i)
# return countnum
#
# count_vowel=[]
# vowel=['a','e','i','o','u']
# for l in s:
# for i in vowel:
# count_vowel.append(count_num(l).get(i))
# print count_vowel
##输入
# n=int(raw_input())
# l=[]
# for i in range(0,n):
# s=list(raw_input())
# l.extend([s])
#先不考虑输入格式
# n=2
# l=['a','e','i','o','u']
# l1=list('aeiou')
# l2=list('my name is ignatius')
# s=[l1,l2]
# print s
# for i in range(0,len(s)):
# for j in range
1108求最小公倍数
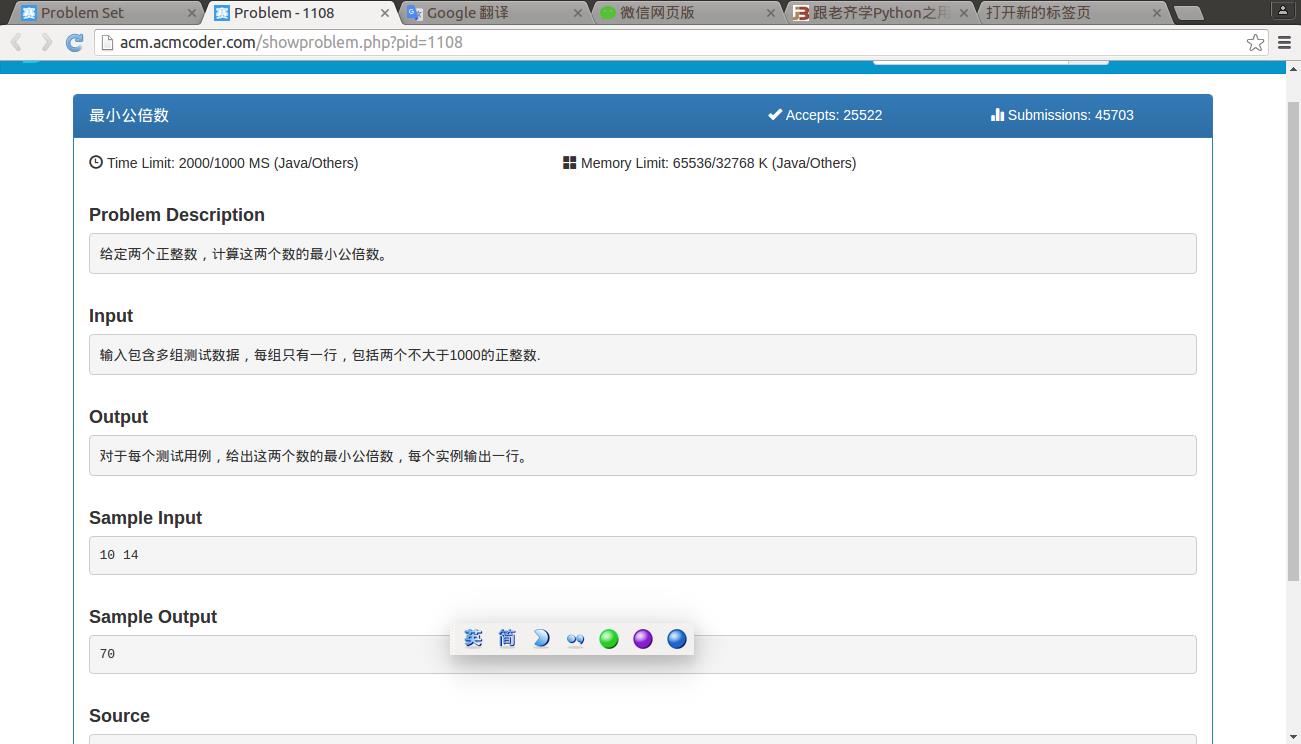
#encoding:utf8
##求最小公倍数
##先求最大公约数
def gcd(x,y):
if x%y==0:
return y
else:
return gcd(y,x%y)
#print gcd(18,10)
def Lowest_Common_Multiple(x,y):
return x*y/gcd(x,y)
print Lowest_Common_Multiple(10,18)
1166 敌兵布阵
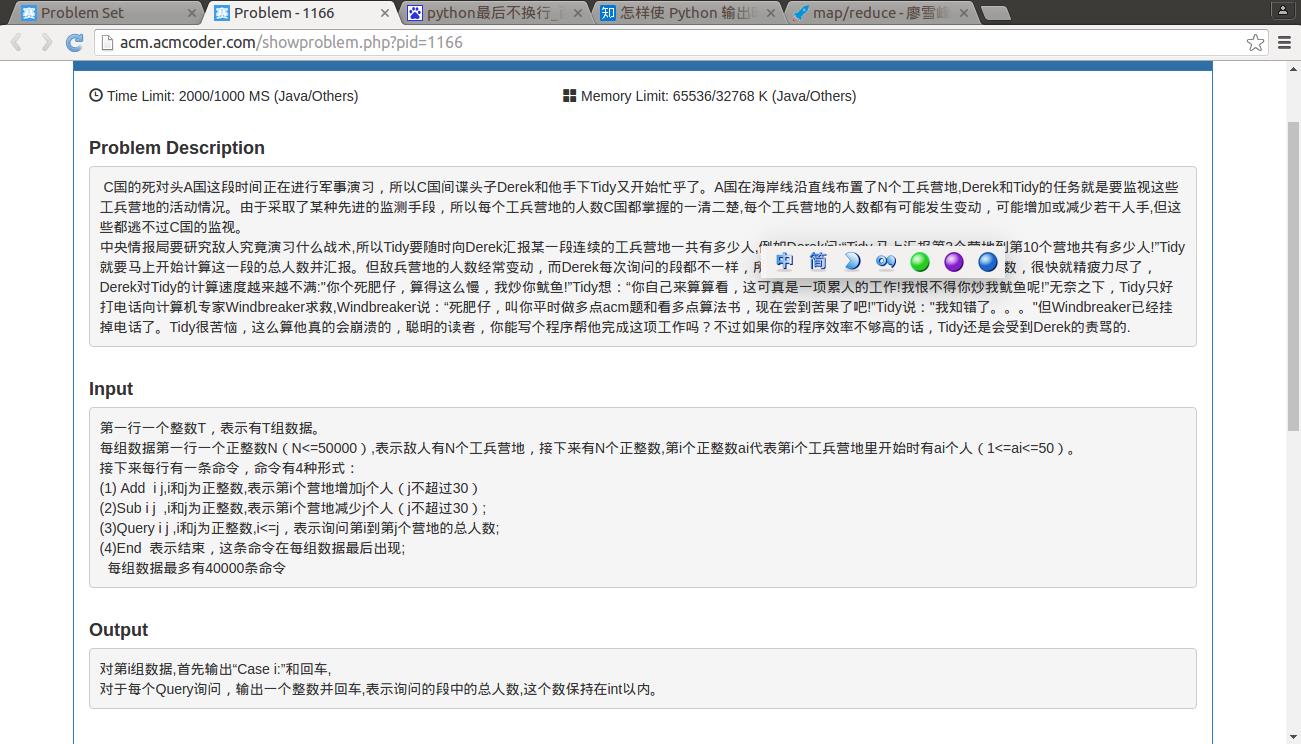
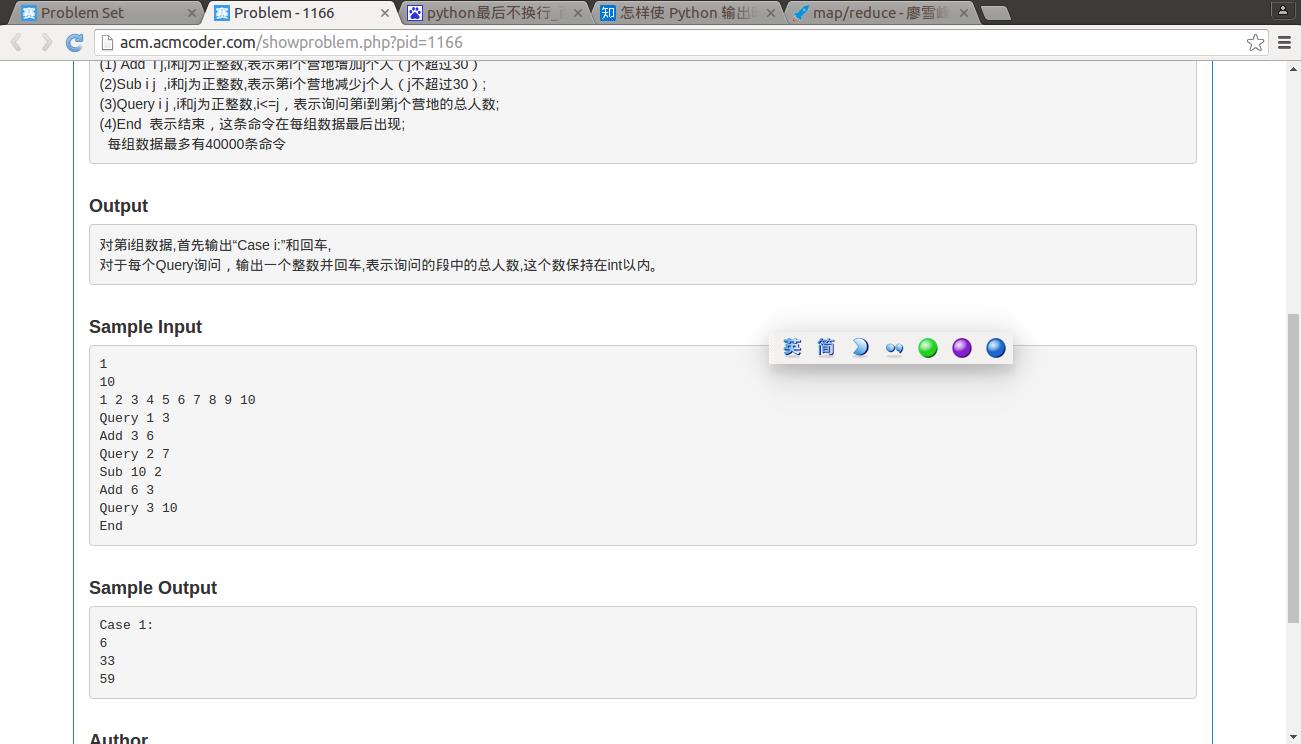
#encoding:utf8
##敌兵布阵
##问题1:未加入人数判断条件
import math
command=[]
t=len(command) #t tiao ming ling
T=int(raw_input()) #共T组数据
for i in range(0,T): #
N=int(raw_input()) #每组共有N个工兵营地
a=map(int,raw_input().split(' ')) #每个工兵营地的人数 例 1 2 3 4 #这里人数要求1<=ai<=50
# print 'Case',T,':'
while t<=40000 :
command=raw_input().split(' ')
if command=='End':
break
else:
i=int(command[1])-1 #第i个营地,此处用-1是因为列表是从0开始计,i不超过30
j=int(command[2]) #j不超过30
if command[0]=='Query':
print sum(a[i:j])
elif command[0]=='Add':
a[i]=a[i]+j #第i个营地增加j个人
elif command[0]=='Sub':
a[i]=a[i]-j
else:
break
以上是关于「学习笔记」3.23代码学习的主要内容,如果未能解决你的问题,请参考以下文章