AI终将战胜人类?-- 以Model Training 的角度看养娃与深度学习的共性
Posted shiter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI终将战胜人类?-- 以Model Training 的角度看养娃与深度学习的共性相关的知识,希望对你有一定的参考价值。
文章大纲
为什么AI 越来越厉害,写作,下棋,绘画 几乎无所不能?因为你给她的学习资料,她是真学!
如果算上fine-tune ,强化学习,那她真是一个可以取其精华,去其糟粕,自我进化的人了!
工作方式:人的成长 -VS- 深度神经网络
深度神经网络的很多处理方法大部分源自生物学的研究。最早的神经网络模拟就是研究怎么用计算机方法模拟单个神经元。

神经元的形状一般呈三角形或多角形,从结构上大致都可分成细胞体(soma)和突起(neurite)两部分。胞体包括细胞膜、细胞质和细胞核;突起由胞体发出,分为树突(dendrite)和轴突(axon)两种,所以从更加细致的分类结构上可以分为胞体和树突、轴突这三个区域。
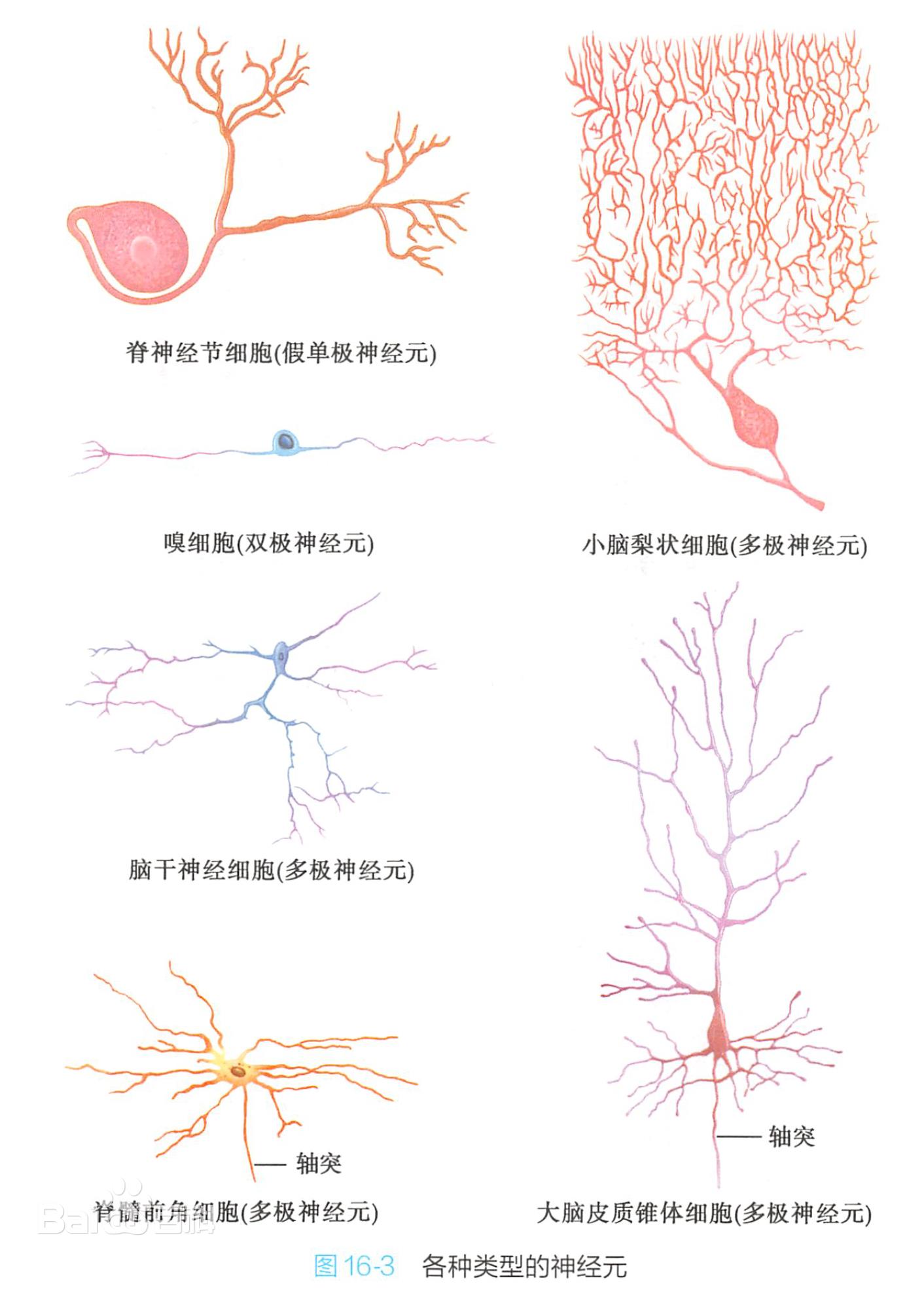
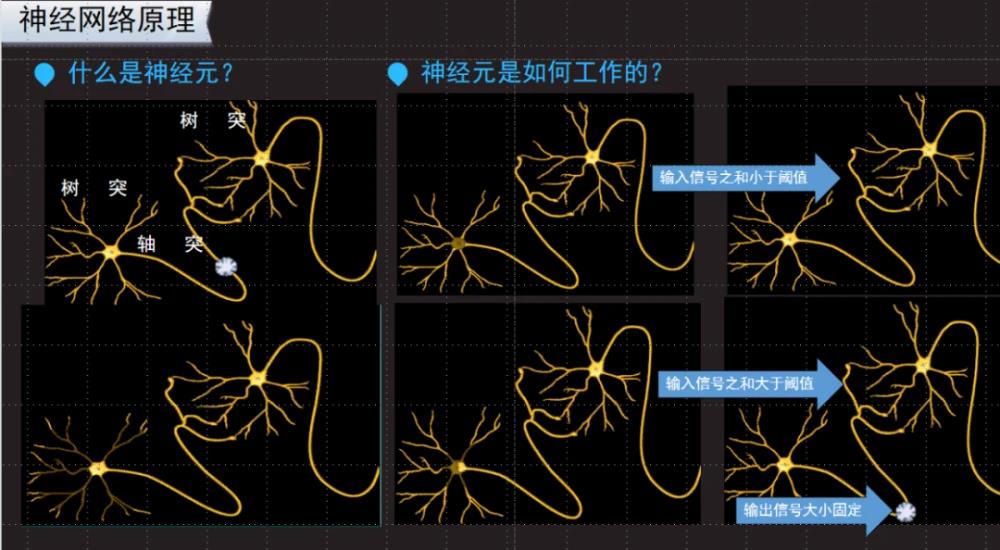
尝试用数学的方式来表达神经元的工作结构,下面这几张图很清晰,说白了就是足够的刺激,进行激活就行。你娃喊你叫爸爸之前,你先得喊他几万次爸爸把那一套神经网络激活了!

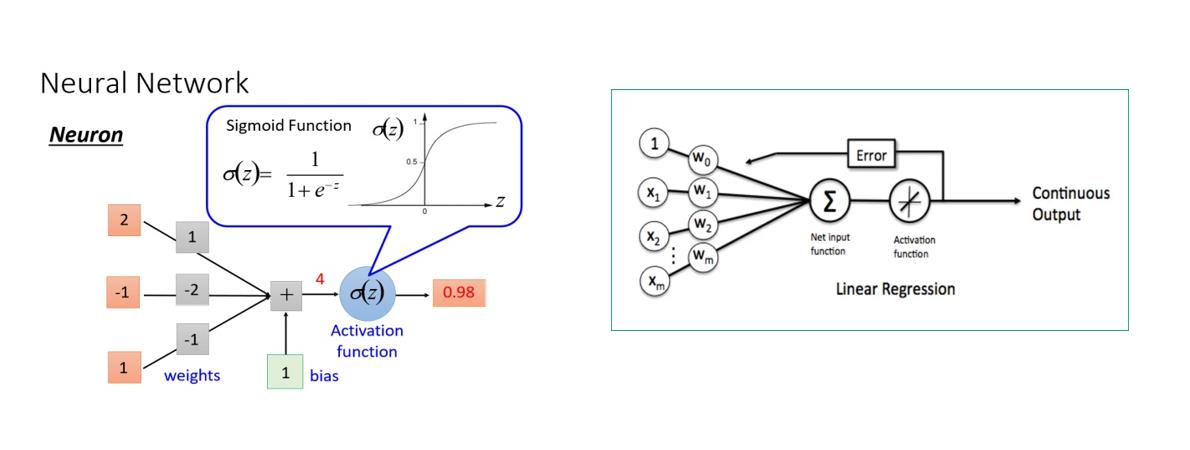
至于最后神经网络激活的哪块,咋激活的?我们其实也可以不用太关心,因为有误差反向传播帮忙解决人工神经网络这个问题。
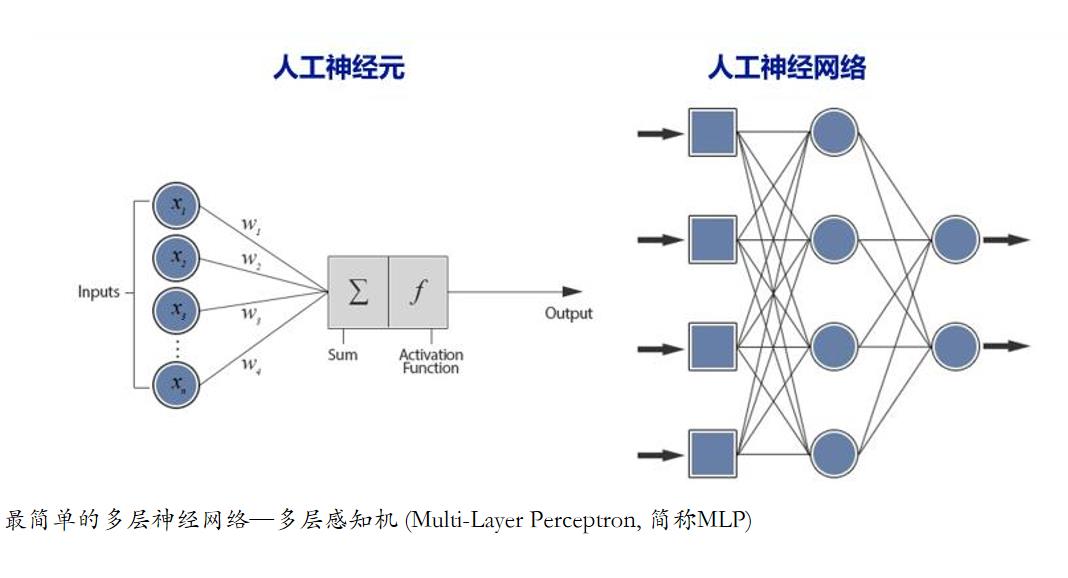
backprop算法能不能告诉我们大脑是如何学习的呢?目前好像科学家们还没弄清楚具体的大脑怎么反向传播误差。
虽然大脑与backprop之间存在诸多不同,但大脑有能力执行backprop中的核心算法。中心思想就是大脑能利用反馈连接来激发神经元活动,从而以局部计算出的误差值来编码“类反向传播的误差信号”(backpropagation-like error signals)。
吃一堑,长一智,我想应该是类似的吧。
培养成本:AI -VS- 养娃
现阶段,人工智能技术局限性还很大,某类模型往往只能解决特定细分领域的问题,模型“泛化”能力很差。通用人工智能才是人们的终极追求
超大规模预训练模型可能摸到了强人工智能的边,但成本很高!
从神经元的数量上来说,人类是目前已知生物中,神经元个数最多的生物,人类的神经元个数可以达到900到1000亿个,而狗和猫的神经元个数只有30到40亿个,这或许是为什么人类能过具有高智慧的缘由之一,我们可以简单的认为神经元的数量多少决定着生物的智慧化程度。
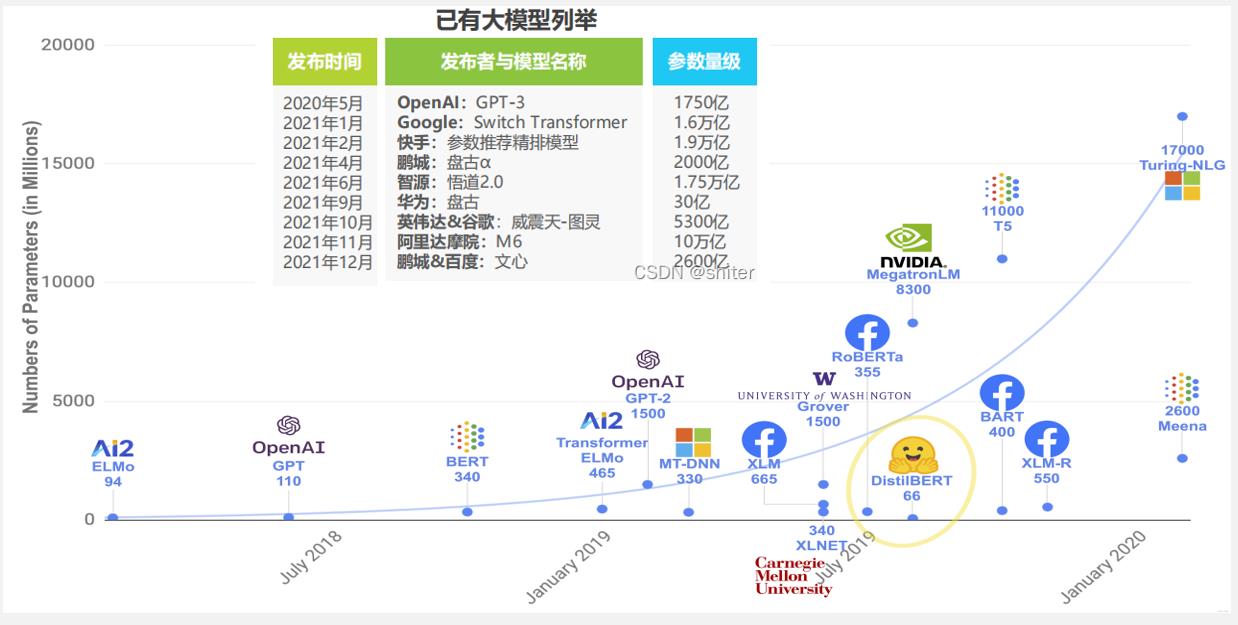
比较著名的GPT-3模型规模为千亿量级,谷歌的Swith Transformer刚开始迈入万亿门槛。中国的“万亿俱乐部”已经有两个玩家了,智源研究院参数规模已经1.75万亿,超过了谷歌Swith Transformer的1.6万亿。阿里巴巴刚刚发布的M6的参数规模已经突破了10万亿。成年人大脑中约包含850-860亿个神经元,每个神经元与3万突触连接,人脑突触数量预计2500万亿左右。
人工智能本质上就是来自于这些神经元、突触。人脑也是一台计算机,这些神经元、突触就是基本的计算单元。如果要想人工智能达到人类水平,那在基本计算单元的数量规模上达到甚至超越人类大脑,就是一个必要条件。
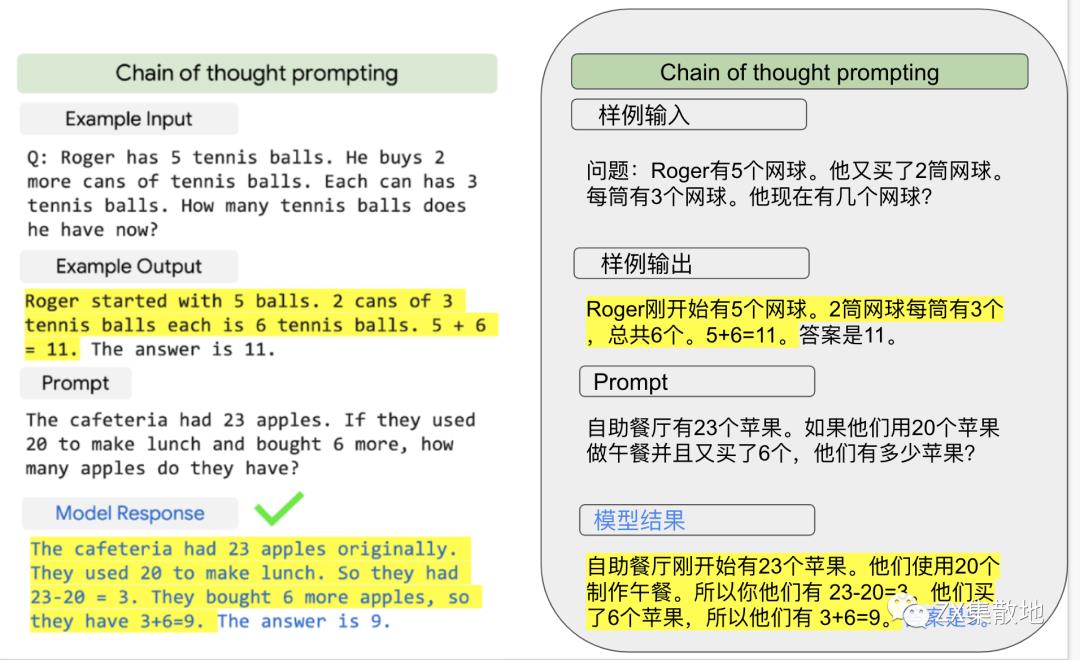
google 的PaLM (Scaling Language Model with Pathways) 模型,5400亿参数,花费为 900万 - 1700万美元,模型有了接近人类9-12岁儿童的解决数学问题的能力。
养娃的成本也不低!
所以,养个小孩的成本有多大,父母付出了多少艰辛,大概的衡量指标我们就可以参考上面的例子。
《中国生育成本报告(2022版)》

当你抱怨奶粉贵的时候,仔细一看,原来大头还是上小学以后!0-2 岁的支出只占了养育成本的一成多点!
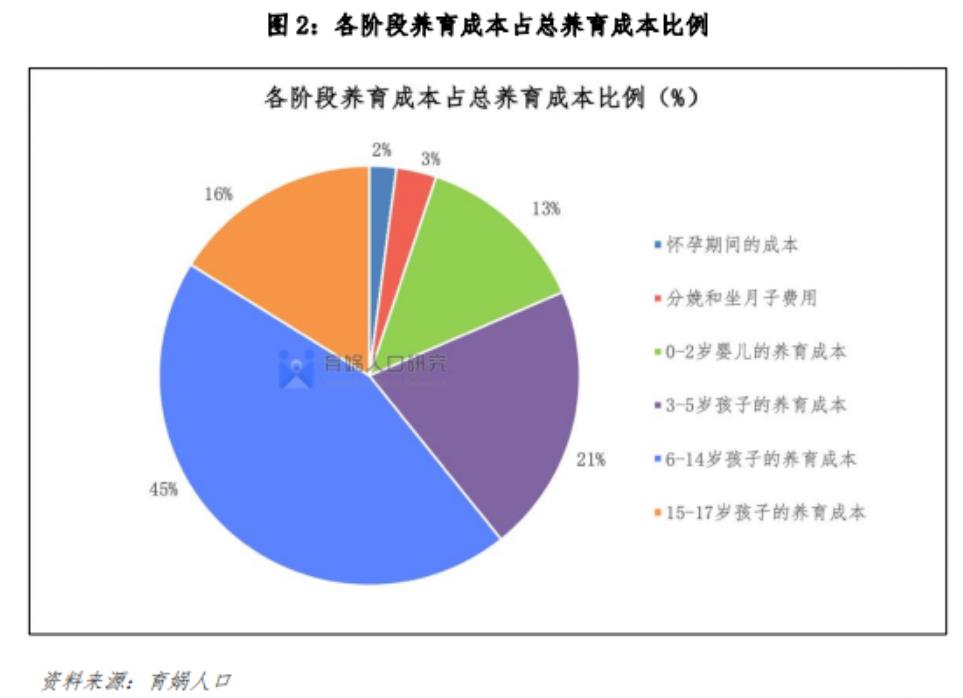


所以结论是,一个城镇孩子供大大学父母大概需要花费 60万左右的资金成本。
余下的人力、感情成本我们参考 google Pathways model。
其他启发,算法角度
几年前,李开复老师说AI 最好的应用应该是人类5秒内通过经验或者决策工作的替代领域,比如车牌识别,自动售票等等。那时候比较有创造力的领域,AI 还不能征服。
卷积神经网络网络可以捕获数据的重要属性如空间位置,递归神经网络以及transformer语言模型可以捕获序列性质,自动编码器-AEs可以捕获数据的数据分布。如图1所示,这些深度学习模型已经彻底改变了语音识别、视觉物体识别和物体检测等领域。
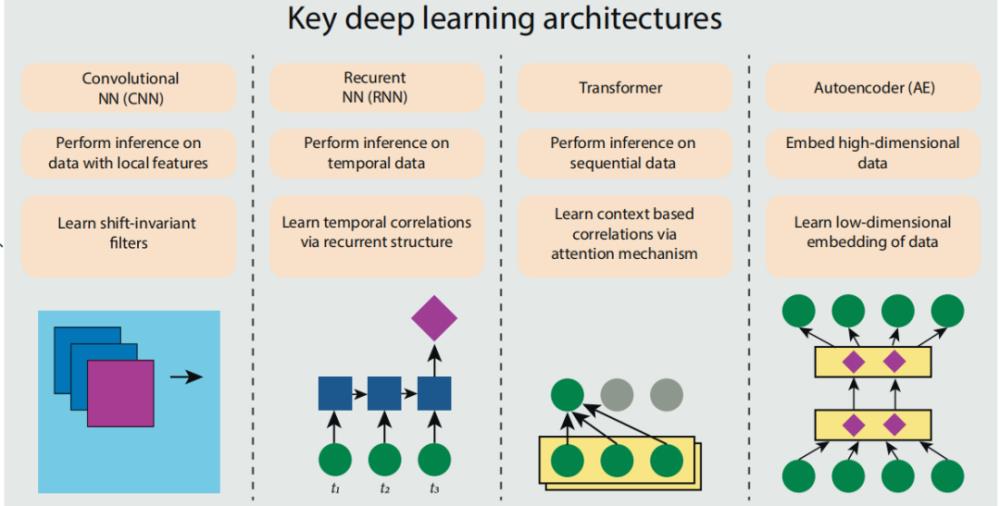
卷积- 从低级特征到高级特征,到抽象能力,到直觉
注意力机制 成长的关键期

为什么人可以从茫茫人海中迅速识别出自己熟悉的面孔呢?科学研究表明,人眼拥有巨量视觉信号并行输入高带宽处理器,带宽约等于每秒100MB信息处理能力。人类经过百万年的进化,视觉系统具有很强的模式识别能力,对可视符号的感知速度比对数字或文本快多个数量级,且大量的视觉信息的处理发生在潜意识阶段。如视觉突变:人眼能够迅速在一大堆灰色物体中识别出红色物体。
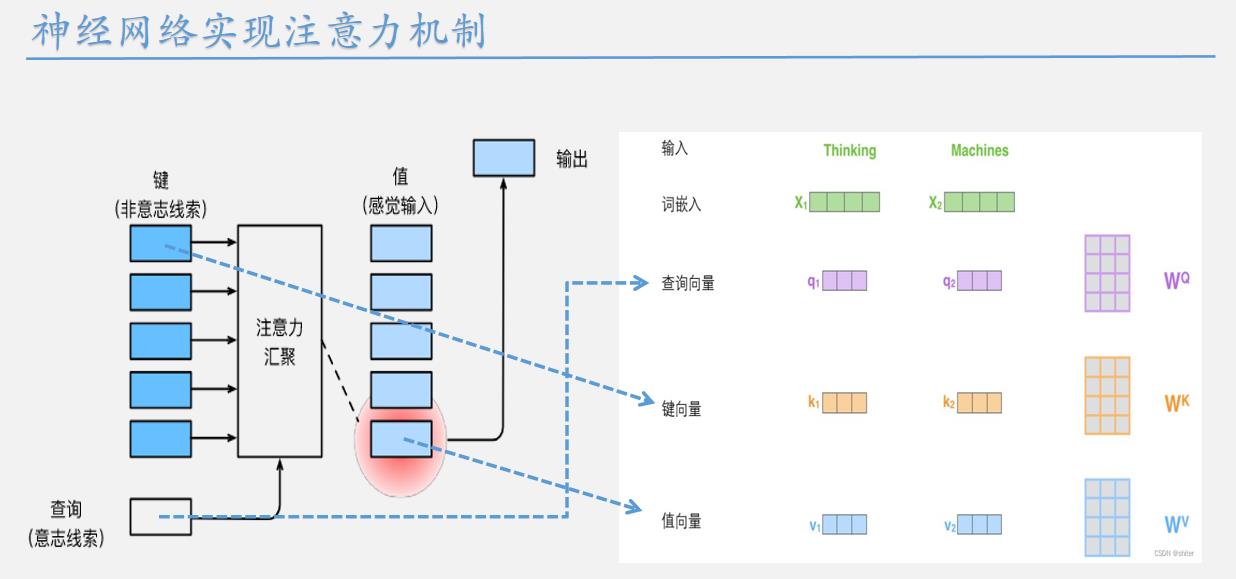
在深度学习中,我们经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。 想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中, 以便同一组词元同时充当查询、键和值。 具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。 由于查询、键和值来自同一组输入,因此被称为 自注意力(self-attention) [Lin et al., 2017b][Vaswani et al., 2017], 也被称为内部注意力(intra-attention)
后记 - 人生怎么走,算法有答案吗?
小孩很小的时候,经常会花费很大的时间和精力去反复学习一个成年人看起来很简单的事情,注意是学习做这些事情:爬,走,吃饭,自主睡觉 。。。走路摔了跟头,他就不走了么,不是的,往往是继续摔跟头,继续走。
其实与其说是AI 战胜了人类,不如说是人类扩展了自己的边界,将全人类的智慧结晶进行了传承吧。
P.S. 一个小实践
参考文献
大脑中的神奇世界:误差与反向传播
- https://new.qq.com/rain/a/20200529A0O9NW00
动物与人类的关键学习期,深度神经网络也有
- https://www.jiqizhixin.com/articles/2021-07-06-4
【论文阅读】思路打开 – Google 发现超大深度学习模型似乎具备推理能力
- https://mp.weixin.qq.com/s/n2KT7LcmGKyjn4o-MehAgQ
PaLM: Scaling Language Modeling with Pathways
- https://arxiv.org/pdf/2204.02311.pdf
用随机梯度下降来优化人生
- https://www.bilibili.com/read/cv13335461?spm_id_from=333.999.0.0
以上是关于AI终将战胜人类?-- 以Model Training 的角度看养娃与深度学习的共性的主要内容,如果未能解决你的问题,请参考以下文章