大数据篇:oozie与spark2整合进行资源调度
Posted 杨铖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据篇:oozie与spark2整合进行资源调度相关的知识,希望对你有一定的参考价值。
文章目录
前言:
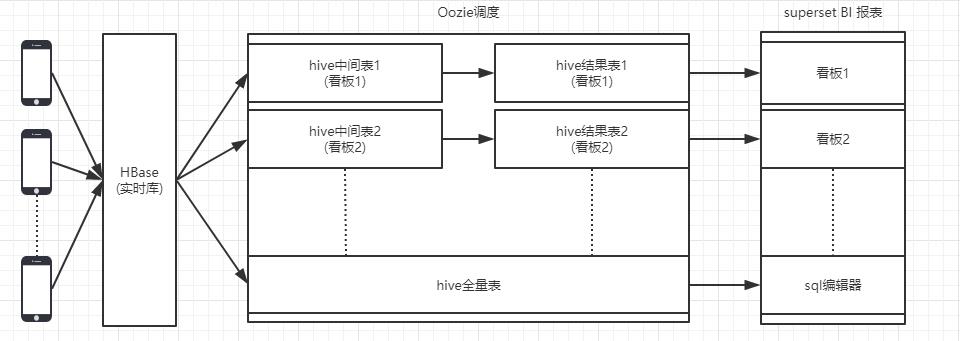
Oozie是Hadoop平台上开源的工作流调度引擎,通过hue集成的oozie管理界面,可以清晰地发布/查看/管理相关调度任务,基于此可以完成整个BI中间表,结果表的存储与计算。
整体流程如下:
1.oozie资源调度
1.1 oozie概览
Oozie是Hadoop平台上的资源调度框架,与flume,sqoop,和hue并称大数据四大协作框架,支持多种任务(spark1/2,mapreduce,java,shell,python等)调度,管理和查看。
下面集群采用的是CDH 5.13集成的oozie 4.1.0,框架更多细节详见:http://oozie.apache.org/docs/4.1.0/index.html
1.2 oozie与spark2整合
下面主要如何通过hue界面工具,将spark2任务提交到oozie调度中心,完成任务的管理和查看,一些关键点如下:
• oozie添加spark2依赖库
• 打包与提交spark2 jar, 创建spark2工作流
• 管理与查看工作流相关状态
1.2.1 oozie添加spark2依赖库
由于CDH自带的oozie默认仅支持spark1,所以唤醒spark2任务有两种方式:
• 第一种是写好spark2 submit的shell脚本,通过oozie里的shell任务唤醒该脚本去提交spark2任务;
• 第二种是配置spark2相关依赖环境,直接通过oozie进行spark2 submit;
下面主要是第二种详解:
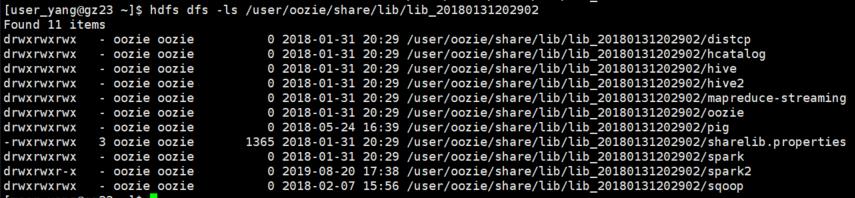
• 首先hdfs创建下oozie的spark2目录:
sudo -u hdfs hdfs dfs -mkdir /user/oozie/share/lib/lib_20180131202902/spark2
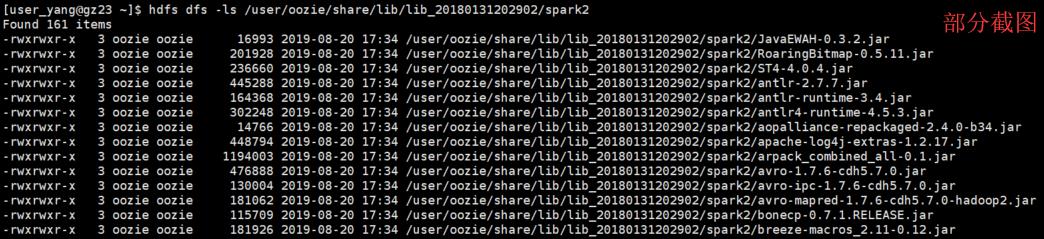
• 其次将 CDH parcels目录下的spark2依赖上传到上面的spark2目录:
sudo -u hdfs hdfs dfs -put /opt/cloudera/parcels/SPARK2/lib/spark2/jars/*.jar /user/oozie/share/lib/lib_20180131202902/spark2/
sudo -u hdfs hdfs dfs -put /opt/cloudera/parcels/CDH/lib/oozie/oozie-sharelib-yarn/lib/spark/oozie-sharelib-spark*.jar /user/oozie/share/lib/lib_20180131202902/spark2/
• 修改第一步创建的spark2目录相关权限:
sudo -u hdfs hdfs dfs -chown -R oozie:oozie /user/oozie/share/lib/lib_20180131202902/spark2
sudo -u hdfs hdfs dfs -chmod -R 775 /user/oozie/share/lib/lib_20180131202902/spark2
• 更新oozie sharelib
oozie admin -oozie http://bigdata.zuzuche.cn:11000/oozie -sharelibupdate

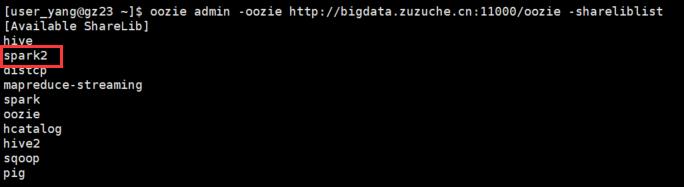
• 查看spark2是否已添加到oozie sharelib
oozie admin -oozie http://bigdata.zuzuche.cn:11000/oozie -shareliblist
1.2.2 打包与提交spark2 jar, 创建spark2工作流
• spark2的打包,通过intellij的sbt进行 clean compile assembly 即可
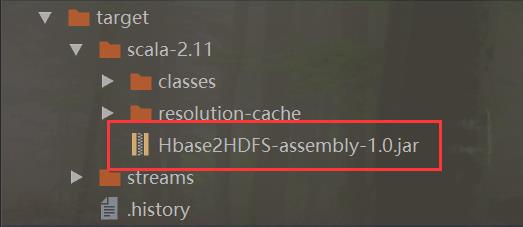
• 基于hue的oozie管理界面详细:
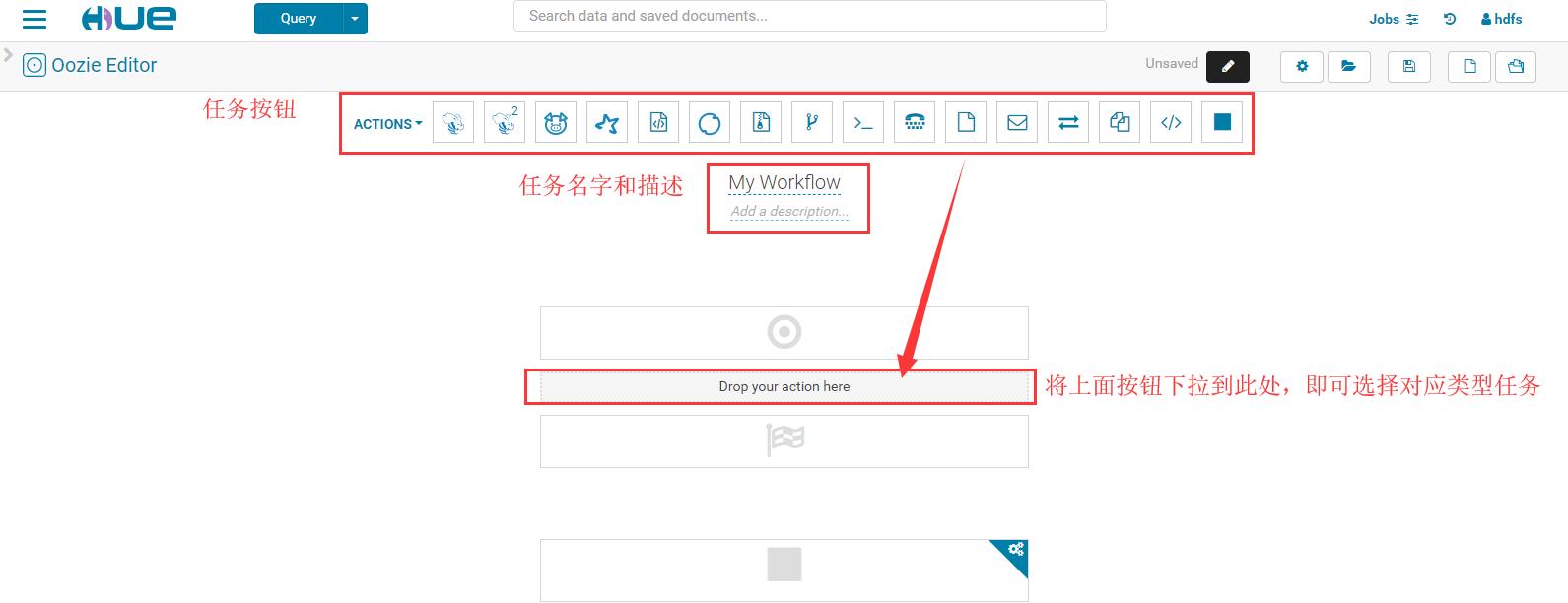
• 通过Hue管理界面创建spark2工作流:
选择spark任务类型:
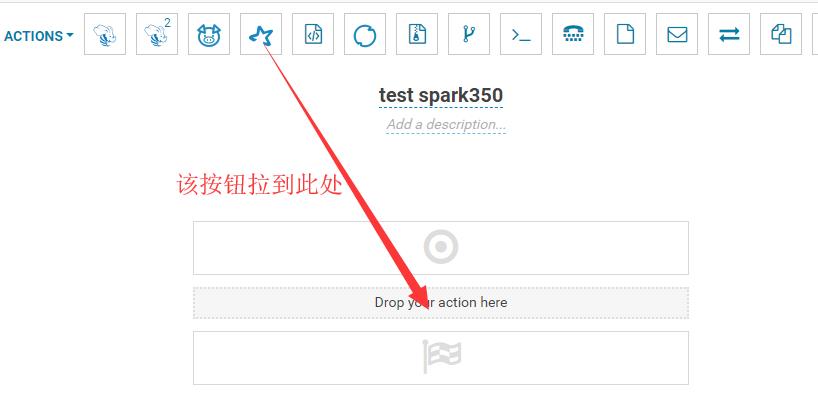
上传spark jar包:
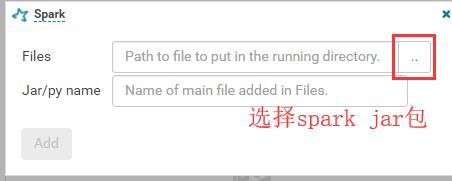
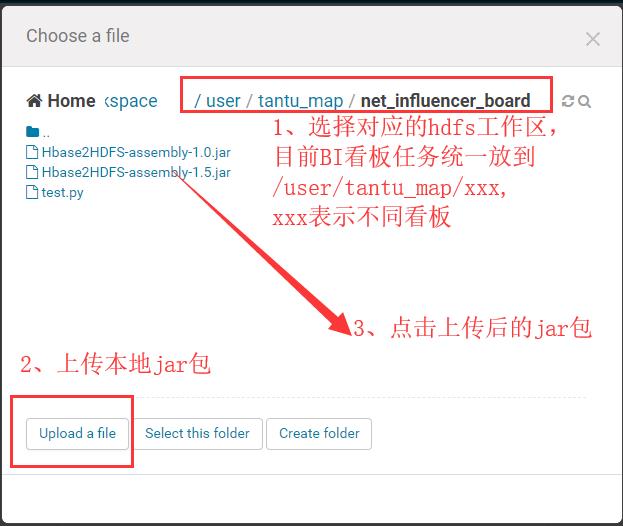
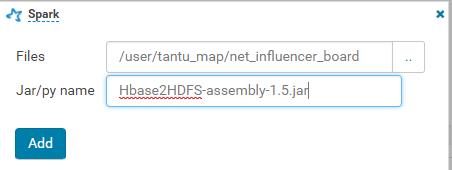
• 配置job.properties相关参数:
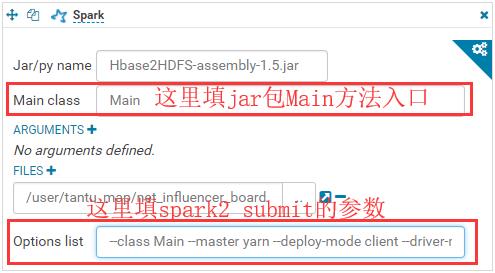
点击上图右上角齿轮标志,进入配置job.properties参数:
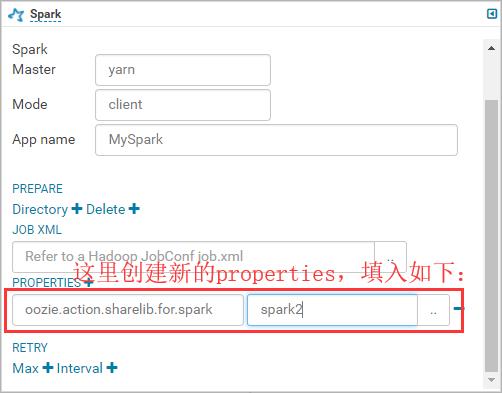
由于上述properties在某些情况下配置会失效,下面进一步配置job.properties:

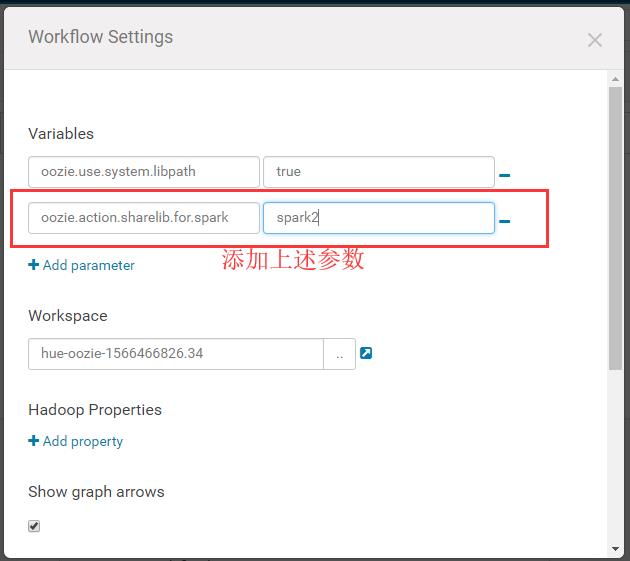
然后保存提交:

最后查看结果:
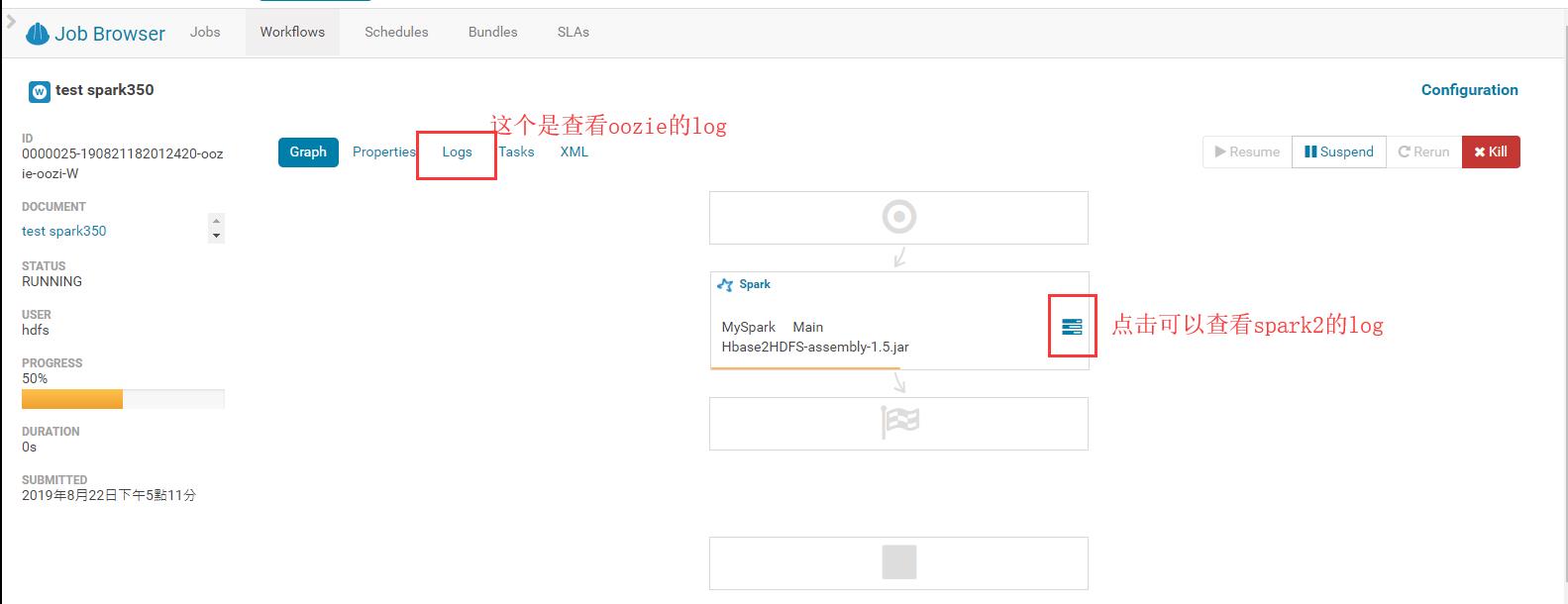
1.2.3 管理与查看工作流相关状态
在job browser的workflows可以看到相应的任务流运行状态:
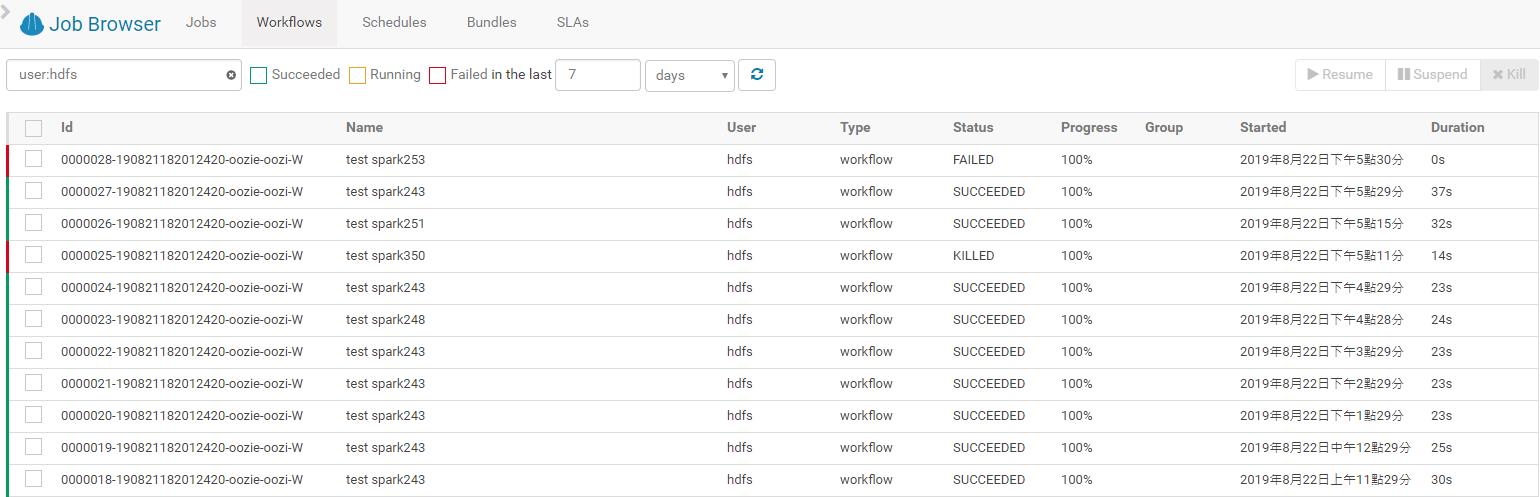
进入schedule界面,设置相关频率:
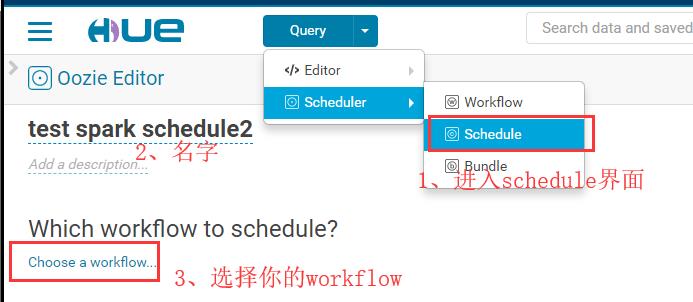
看到各个schedule的状态:

1.3 oozie workflow/schedules/bundles
• workflow更多是单次单个任务的定义
• schedules是对workflow的某个任务定时调度管理
• bundles是对多个schedule的组合管理
1.4 配置可能会遇到的一些问题
WARN org.apache.oozie.action.hadoop.SparkActionExecutor: SERVER[ec2-54-179-152-169.ap-southeast-1.compute.amazonaws.com] USER[admin] GROUP[-] TOKEN[] APP[MyFirstSpark2] JOB[0000000-171016230402705-oozie-oozi-W] ACTION[0000000-171016230402705-oozie-oozi-W@spark-1411] Launcher exception: Exception when registering SparkListener
org.apache.spark.SparkException: Exception when registering SparkListener
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2193)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:562)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2313)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:868)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:860)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:31)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:738)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
at org.apache.oozie.action.hadoop.SparkMain.runSpark(SparkMain.java:178)
at org.apache.oozie.action.hadoop.SparkMain.run(SparkMain.java:90)
at org.apache.oozie.action.hadoop.LauncherMain.run(LauncherMain.java:81)
at org.apache.oozie.action.hadoop.SparkMain.main(SparkMain.java:57)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.oozie.action.hadoop.LauncherMapper.map(LauncherMapper.java:235)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.ClassNotFoundException: com.cloudera.spark.lineage.ClouderaNavigatorListener
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.util.Utils$.classForName(Utils.scala:229)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2159)
at org.apache.spark.SparkContext$$anonfun$setupAndStartListenerBus$1.apply(SparkContext.scala:2156)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:35)
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:2156)
... 34 more
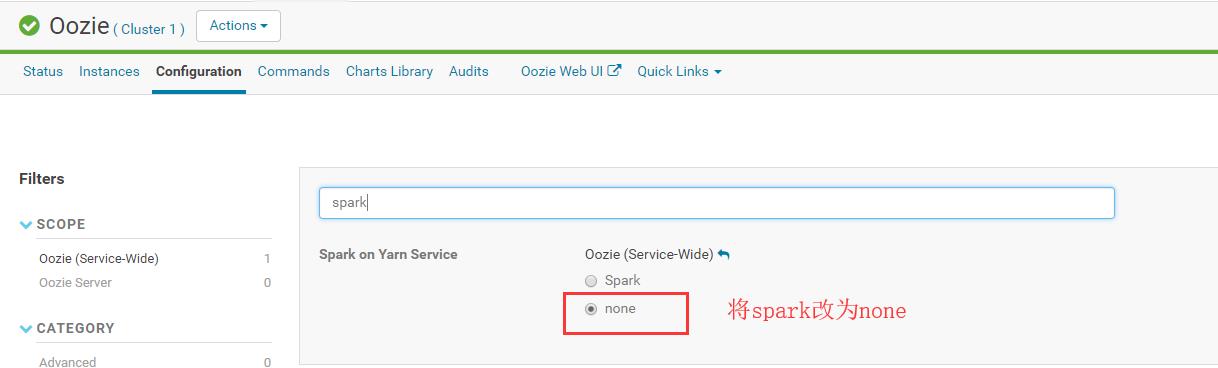
解决方法,修改CDH上oozie的配置,如下:
以上是关于大数据篇:oozie与spark2整合进行资源调度的主要内容,如果未能解决你的问题,请参考以下文章