React 事件系统流程 原理理解
Posted YuLong~W
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了React 事件系统流程 原理理解相关的知识,希望对你有一定的参考价值。
文章目录
事件系统
问:React 为什么要写出一套自己的事件系统呢?
答:1、首先,对于不同的浏览器,对事件存在不同的兼容性,React 想实现一个兼容全浏览器的框架, 为了实现这个目标就需要创建一个兼容全浏览器的事件系统。
2、其次,v17 之前 React 事件都是绑定在 document 上,v17 之后 React 把事件绑定在应用对应的 容器 container 上,将事件绑定在同一容器统一管理,防止很多事件直接绑定在原生的 DOM 元素上,造成不可控的问题。
3、最后,这种事件系统,大部分处理逻辑都在底层处理了,这对后期的 ssr(服务器端渲染) 和跨端支持度很高。
React 需要模拟一套事件流:事件捕获-> 事件源 -> 事件冒泡,也包括 重写事件源对象 event
事件处理
1、冒泡阶段和捕获阶段
- 冒泡阶段:开发者正常给 React 绑定的事件比如 onClick,onChange,默认会在模拟冒泡阶段执行。
- 捕获阶段:如果想要在捕获阶段执行可以将事件后面加上 Capture 后缀,比如 onClickCapture,onChangeCapture。
2、阻止冒泡
阻止事件向上冒泡,可以用 e.stopPropagation()
3、阻止默认行为
阻止事件默认行为,可以用 e.preventDefault()
原生事件: e.preventDefault() 和 return false 可以用来阻止事件默认行为,由于在 React 中给元素的事件并不是真正的事件处理函数。所以导致 return false 方法在 React 应用中完全失去了作用。
事件合成
React 应用中,元素绑定的事件并不是原生事件,而是 React 合成的事件,比如 onClick 是由 click 合成,onChange 是由 blur ,change ,focus 等多个事件合成。
React 的事件不是绑定在元素上的,而是统一绑定在 顶部容器Container 上,在 v17 之前是绑定在 document 上的,在 v17 改成了 app 容器上。
绑定事件 不是一次性绑定所有事件,比如发现了 onClick 事件,就会绑定 click 事件,比如发现 onChange 事件,会绑定 [blur,change ,focus ,keydown,keyup] 多个事件。
事件插件机制
1、registrationNameModules
应用于 事件触发阶段,根据不同React事件使用对应的插件。
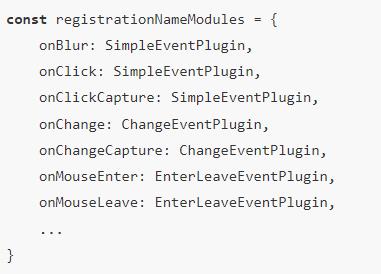
该对象记录了 React 事件和与之对应的处理插件的映射,比如上述的 onClick ,就会用 SimpleEventPlugin 插件处理,onChange 就会用 ChangeEventPlugin 处理。
问:为什么要用不同的事件插件处理不同的 React 事件?
答:对于不同的事件,有不同的处理逻辑。对应的事件源对象也有所不同,React 的事件和事件源是自己合成的,所以对于不同事件需要不同的事件插件处理。
2、registrationNameDependencies
应用于 事件绑定阶段,根据React事件找到对应原生事件数组。

该对象保存了 React 事件和原生事件对应关系,比如 onChange ,就会找到对应的原生事件数组,逐一绑定。
事件绑定
所谓事件绑定,就是在 React 处理 props 时候,如果遇到事件就会通过 addEventListener 注册原生事件。
export default function Index()
const handleClick = () => console.log('点击事件')
const handleChange =() => console.log('change事件)
return <div >
<input onChange= handleChange />
<button onClick= handleClick >点击</button>
</div>
onChange 和 onClick 会保存在对应 DOM 元素类型 fiber 对象( hostComponent )的 memoizedProps 属性上。
React 根据事件注册事件监听器
1、调用 diffProperties函数。

2、diffProperties函数 在 diff props 如果发现是合成事件( onClick ) 就会调用 legacyListenToEvent 函数。

3、legacyListenToEvent 函数对合成事件取出依赖事件数组进行遍历绑定。
问:绑定在 document 的事件处理函数是?
答:绑定在 document 的事件,是 React 统一的事件处理函数
dispatchEvent,React 需要一个统一流程去代理事件逻辑,包括 React 批量更新等逻辑。
事件触发
第一步:批量更新
执行 dispatchEvent,传入真实事件源元素。通过元素找到对应 fiber,fiber和原生DOM建立联系。接下来进行批量更新。

React 在初始化真实 DOM 的时候,用一个随机的 key internalInstanceKey 指针指向了当前 DOM 对应的 fiber 对象,fiber 对象用 stateNode 指向了当前的 DOM 元素。
批量更新:(state章节详讲) React State 原理理解
第二步:合成事件源
通过合成事件找到对应 处理插件,合成 新的事件源 e,里面包含了 preventDefault 和 stopPropagation 等方法。
第三步:形成事件执行队列
在第一步通过原生 DOM 获取到对应的 fiber ,接着会从这个 fiber 向上遍历,遇到元素类型 fiber ,就会收集事件,用一个数组收集事件:
- 如果遇到 捕获阶段事件 onClickCapture ,就会 unshift 放在数组前面。以此模拟事件捕获阶段。
- 如果遇到 冒泡阶段事件 onClick ,就会 push 到数组后面,模拟事件冒泡阶段。
- 一直收集到最顶端 app ,形成 执行队列,在接下来阶段,依次执行队列里面的函数。

举例:
export default function Index()
const handleClick1 = () => console.log(1)
const handleClick2 = () => console.log(2)
const handleClick3 = () => console.log(3)
const handleClick4 = () => console.log(4)
return <div onClick= handleClick3 onClickCapture= handleClick4 >
<button onClick= handleClick1 onClickCapture= handleClick2 >点击</button>
</div>
点击 button 按钮后:执行顺序:[handleClick4, handleClick2 , handleClick1,handleClick3 ]
阻止事件冒泡:

如果,handleClick2 中调用 e.stopPropagation(),那么事件源里将有状态证明此次事件已经停止冒泡,那么下次遍历的时候,event.isPropagationStopped() 就会返回 true ,所以跳出循环,handleClick1, handleClick3 将不再执行,模拟了阻止事件冒泡的过程。
总结
1、事件处理(捕获和冒泡、阻止冒泡阻止默认事件)
2、事件合成(事件插件机制)
3、事件绑定(事件注册)
4、事件触发(执行事件队列)
以上是关于React 事件系统流程 原理理解的主要内容,如果未能解决你的问题,请参考以下文章