Golang开发面经知乎(两轮技术面)
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang开发面经知乎(两轮技术面)相关的知识,希望对你有一定的参考价值。
文章目录
写在前面
知乎面试下来感觉还行吧,毕竟知乎挺小的,不过也是挺注重基础的,面试官水平也很好。
笔试
略
一面
进程和线程的区别?
进程是操作系统资源分配的基本单位、而线程是任务调度和执行的基本单位。
每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销;
线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器。线程之间切换的开销小。
虚拟地址是什么?
虚拟地址空间划分为多个固定大小的虚拟页(VP),物理地址空间 (DRAM内存) 划分为多个固定大小的物理页(PP),虚拟页和物理页的大小是一样的,通常为4KB。
对于进程来说,使用的都是虚拟地址。
每个进程维护一个单独的页表。
页表是一种数组结构,存放着各虚拟页的状态,是否映射,是否缓存。
内存分段分页讲讲?
分段:将程序分为代码段、数据段、堆栈段等;
分段地址通过段表,转换成线性地址; 分段地址包括段号和段内地址; 段表,包括短号、段长、基址;
分页:将段分成均匀的小块,通过页表映射物理内存;
分页机制就是将虚拟地址空间分为大小相等的页;物理地址空间也分为若干个物理块(页框);页和页框大小相等。实现离散分配; 分页机制的实现需要 MMU 硬件实现;负责分页地址转换; 页大小(粒度)太大浪费;太小,影响分配效率。
http 1.0,1.1,2.0 区别?
HTTP1.0:中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准。
HTTP1.1:
- 在请求头引入了range头域,它允许只请求资源的某个部分,方便了开发者自由的选择以便于充分利用带宽和连接。
- 新增了多个错误状态响应码,如:413
- 长连接
HTTP2.0:
- 新的二进制格式
- 多路复用:
发出的多个请求可以在同一个连接上并行处理,当请求数量较大时,不会因为某一个请求任务过重而导致其他任务无法正常执行 - 头部数据压缩:encoder 以减少需要传输的 header 大小
post和get的区别
GET用于获取信息,是幂等的,且可缓存。
POST用于修改服务器上的数据,非幂等,不可缓存。
TCP 连接是怎么样的?
为什么是三次?断开为什么是四次?
三次握手
因为通信的前提是确保双方都是接收和发送信息是正常的。
三次握手是为了建立可靠的数据传输通道,
第一次握手就是让 接收方 知道 发送方 有发送信息的能力
第二次握手就是让 发送方 知道 接收方 有发送和接受信息的能力
第三次握手就是让 接收方 知道 发送方 有接受信息的能力
四次挥手
四次挥手则是为了保证等数据完成的被接收完再关闭连接。
既然提到需要保证数据完整的传输完,那就需要保证双方 都达到关闭连接的条件才能断开。
第一次挥手:客户端发起关闭连接的请求给服务端;
第二次挥手:服务端收到关闭请求的时候可能这个时候数据还没发送完,所以服务端会先回复一个确认报文,表示自己知道客户端想要关闭连接了,但是因为数据还没传输完,所以还需要等待;
第三次挥手:当数据传输完了,服务端会主动发送一个 FIN 报文,告诉客户端,表示数据已经发送完了,服务端这边准备关闭连接了。
第四次挥手:当客户端收到服务端的 FIN 报文过后,会回复一个 ACK 报文,告诉服务端自己知道了,再等待一会就关闭连接。
2MSL有什么用?
2MSL 即两倍的 MSL,TCP 的 TIME_WAIT 状态也称为 2MSL 等待状态,当 TCP 的一端发起主动关闭,在发出最后一个 ACK 包后,即第3次握手完成后发送了第四次握手的 ACK 包后就进入了 TIME_WAIT 状态,必须在此状态上停留两倍的 MSL 时间,等待 2MSL 时间主要目的是怕最后一个 ACK 包对方没收到, 那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的 FIN包 后可以再发一个 ACK应答包。
chan用过吧?对一个关闭的 chan 读写会怎么样?
-
空chan
- 读会读取到该chan类型的
零值。 - 写会直接写到chan中。
- 读会读取到该chan类型的
-
关闭的chan
- 读已经关闭的 chan 能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
如果有元素,就继续读剩下的元素,如果没有就是这个chan类型的零值,比如整型是 int,字符串是""。 - 写已经关闭的 chan 会 panic。因为源码上面就是这样写的,可以看
src/runtime/chan.go
- 读已经关闭的 chan 能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
redis 缓存击穿 ?雪崩?有了解过吗?
其实对于这些缓冲击穿,缓冲穿透,缓存雪崩都是由于中译之后比较容易混淆,如果我们还原回英文,那么就会很容易理解了。
- 缓存穿透:
cache penetration。表示程序要访问的缓存key不在缓存 key 的取值范围里。 - 缓存击穿:
hotspot invalid。表示缓存数据失效了。和cache penetration的区别是缓存的 key 还是存在的,只是这个 key 的数据失效了。 - 缓存雪崩:
cache avalanche。表示大量缓存都失效了,像雪崩一样。
跳表说一下?
Redis 的跳跃表由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义,其中 zskiplistNode 结构用于表示跳跃表节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。
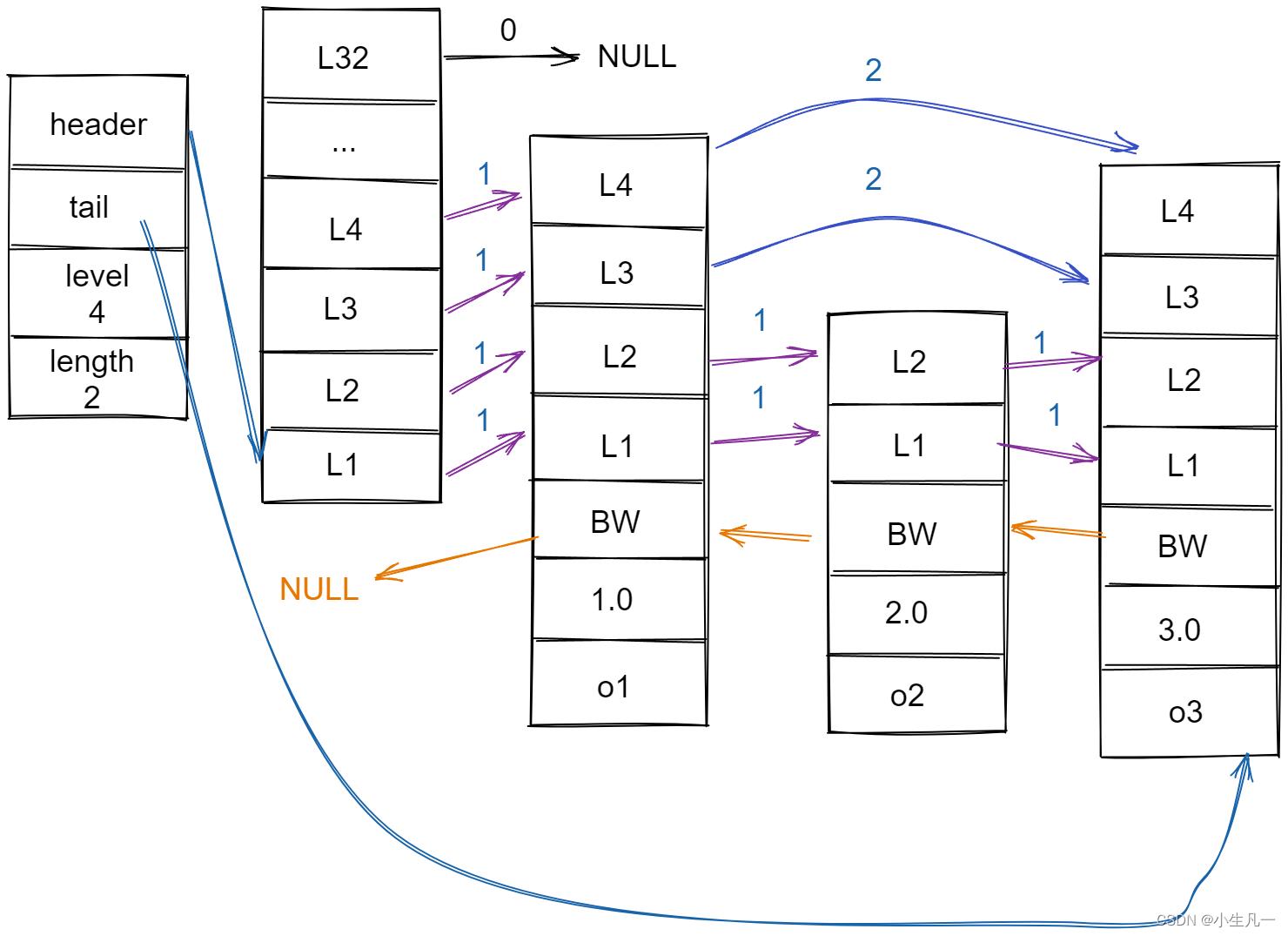
上图中展示了一个跳跃表示例,最左边的就是 zskiplist 结构。
- header:指向跳跃表的表头节点。
- tail:指向跳跃表的表尾节点。
- level:记录目前跳跃表内,层数
最大的那个节点的层数。 - 记录跳跃表的长度,也就是,跳跃表目前包含节点的数量。
- 层(level):节点中用L1、L2、L3等字样标记节点的各个层,L1表示第一层,L2代表第二层,以此类推。每层都带有两个属性:
前进指针和跨度。前进指针用于方位位于表尾方向的其他节点。而跨度则记录了前进指针所指向节点和当前节点的距离。 - 后退(backward)指针:
节点中用BW字样标记的后退指针,他指向当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。 - 分值(score):各个节点中的 1.0、2.0、3.0是节点所保存的分值。在跳跃表中,节点按各个所保存的分值从小到大排序。
- 成员对象(obj):各个节点中的o1,o2 和 o3 是节点所保存的成员对象。
算法:最长公共子串
二面
一上来就做题,难受,做完题就聊项目,聊完项目就聊聊八股。
用两个协程打印交替打印A1B2C3D4E5…
用两个 chan +一个 wg来控制。
package main
import (
"fmt"
"sync"
)
func main()
var wg sync.WaitGroup
wg.Add(1)
chNumber := make(chan struct)
chLetter := make(chan struct)
i:=0
index := 0
a := "abcdefghijklmnopqrskuvwxyz"
go func()
for
select
case <-chNumber:
fmt.Print(i)
i++
fmt.Print(i)
i++
chLetter <- struct
break
default:
break
()
go func(wg *sync.WaitGroup)
for
select
case <-chLetter:
if index > len(a)-1
wg.Done()
return
fmt.Print(string(a[index]))
index++
fmt.Print(string(a[index]))
index++
chNumber<- struct
break
default:
break
(&wg)
chNumber<- struct
wg.Wait()
慢查询如何排查?
可以先检查索引,再看看我们的 sql语句 是否足够性能好。
然后可以用 pprof 进行检测,排查慢的逻辑并优化。
es 用过是吧?简单说一下原理?
ES是一个搜索引擎,我所知道的是用到了倒排索引来进行检测的。
mysql 索引结构?和其他数据结构对比?
B 树
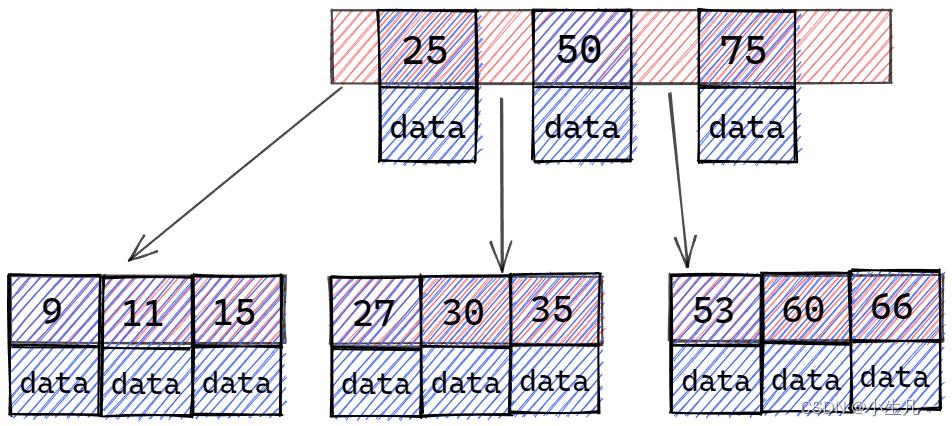
B+树
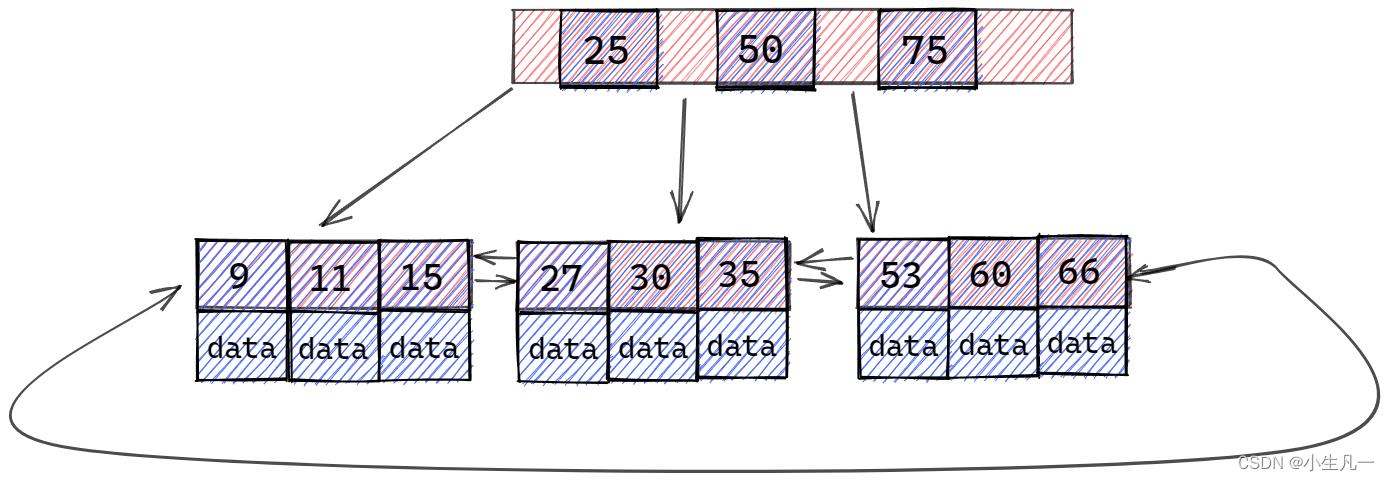
- B+ 树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为
log (n)。而 B-树 查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。 - B+ 树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而 B- 树 每个节点 key 和 data 在一起,则无法区间查找。同时我们访问某数据后,可以将
相近的数据预读进内存,这是利用了空间局部性。 - B+ 树更适合
外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确。
讲讲 聚集索引 和 非聚集索引?
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据。
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因。
参考链接
[1]. https://blog.csdn.net/weixin_39790760/article/details/110815922
以上是关于Golang开发面经知乎(两轮技术面)的主要内容,如果未能解决你的问题,请参考以下文章