神经网络
Posted ZJun310
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络相关的知识,希望对你有一定的参考价值。
第五章 神经网络
神经元模型
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应
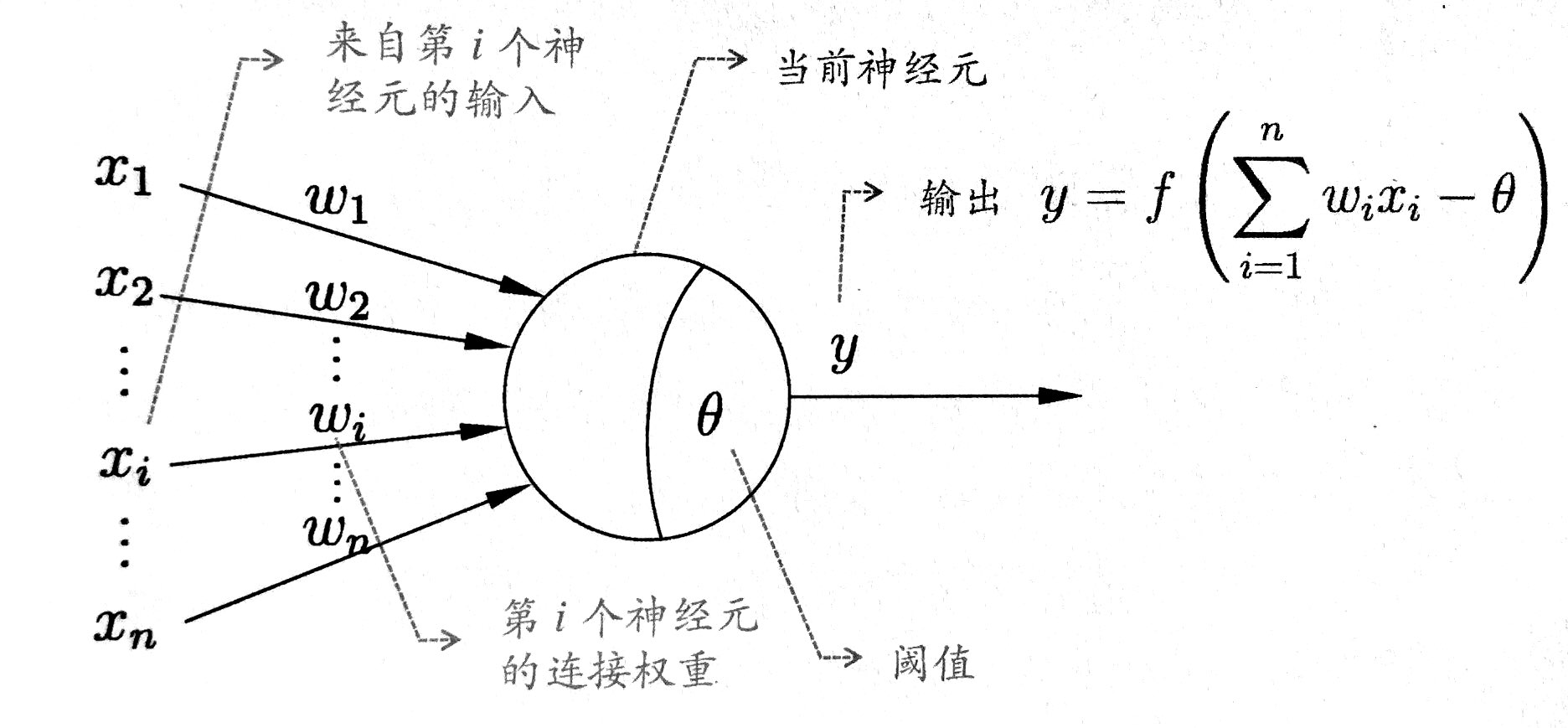
M-P神经元模型思路
将生物神经网络中的神经元抽象后得到经典的“M-P神经元模型”。在这个模型中,神经元接收来至n个其他神经元传递过来的输入信号 ,这些信号通过带权重的连接进行传递 ,神经元接收到总到输入值,将与神经元的阈值进行比较 ,然后通过激活函数处理以产生神经元的输出
图示如下
感知机(Perceptron)
感知机被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。
Wikipedia: In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers: functions that can decide whether an input (represented by a vector of numbers) belongs to one class or another.

Definition:In the modern sense, the perceptron is an algorithm for learning a binary classifier: a function that maps its input x (a real-valued vector) to an output value f(x) (a single binary value):
简单的说,其实就是一个超平面将样本空间一分为二
神经网络模型
基本构成
常见的神经网络是由感知机构成的层级结构,每层神经元和下层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接,这样的神经网络通常称为多层前馈神经网络。
模型训练
神经网络的学习过程,就是根据训练数据来调整神经元之间的连接权以及每个功能神经元的阈值
误差逆传播算法(Back Propagation of Error)
算法思想概览
Backward Prorogation of Errors, often abbreviated as BackProp is one of the several ways in which an artificial neural network (ANN) can be trained. It is a supervised training scheme, which means, it learns from labeled training data (there is a supervisor, to guide its learning).
To put in simple terms, BackProp is like “learning from mistakes”. The supervisor corrects the ANN whenever it makes mistakes.
An ANN consists of nodes in different layers; input layer, intermediate hidden layer(s) and the output layer. The connections between nodes of adjacent layers have “weights” associated with them. The goal of learning is to assign correct weights for these edges. Given an input vector, these weights determine what the output vector is.
In supervised learning, the training set is labeled. This means, for some given inputs, we know(label) the desired/expected output.
BackProp Algorithm:
Initially all the edge weights are randomly assigned. For every input in the training dataset, the ANN is activated and its output is observed. This output is compared with the desired output that we already know, and the error is “propagated” back to the previous layer. This error is noted and the weights are “adjusted” accordingly. This process is repeated until the output error is below a predetermined threshold.Once the above algorithm terminates, we have a “learned” ANN which, we consider is ready to work with “new” inputs. This ANN is said to have learned from several examples (labeled data) and from its mistakes (error propagation).
摘至:(Quora)How do you explain back propagation algorithm to a beginner in neural network?
BP算法基于梯度下降策略,以目标函数的负梯度方向对参数进行调整
梯度下降补充说明
梯度下降法也称最速下降法是以负梯度方向作为下降方向对极小化算法,也是无约束最优化中最简单的方法
下面给出负梯度方向是下降最快的方向的证明过程
假定
f(x)
在
xk
附近连续可微,于是有
记 x−xk=αdk , α 是步长因子, dk 为下降方向,于是得到
f(xk+αdk)=f(xk)+αgTkdk+o(||αdk||)
f(xk+αdk)-f(xk)=αgTkdk+o(||αdk||)
想要下降最快,也即最小化
gTkdk
利,用
C−S
可得
显然,当 dk=−gk 时 gTkdk 取到最小
BP算法流程
输入:训练集合以上是关于神经网络的主要内容,如果未能解决你的问题,请参考以下文章