Hadoop中Configuration类与参数设置规则
Posted 莫西里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop中Configuration类与参数设置规则相关的知识,希望对你有一定的参考价值。
一、介绍
我们在使用MapReduce框架进行开发时,总会使用到Configuration类的一个实例对象去初始化一个人任务,然后进行任务提交,而在整个任务执行过程中,客户点实例化的Configuration的对象,将作为整个任务过程中参数版本,任务执行过程中所需要的所有参数都是从客户端实例化的Configuration对象中进行获取。下面详细介绍一下Configuration的参数过程。
二、初始化过程
Configuration初始化时主要两步:读取默认文件和读取site级别的文件。
1、读取默认文件
Configuration初始化过程中,首先会读取整个CLASSPATH中的CORE-DEFAULT.XML、HDFS-DEFAULT.XML、YARN-DEFAULT.XML以及想起默认配置文件,这些文件需要用需要进行添加就已经存在项目的CLASSPATH中,因为这些文件存储在MR开发的依赖Jar文件中,用户不需要操心这一部分默认配置文件。
(1)yarn-default.xml文件在hadoop-yarn-common-version.jar文件的根目录下
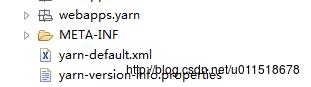
(2)mapred-default.xml文件在hadoop-mapreduce-client-core-version.jar 文件的根目录下
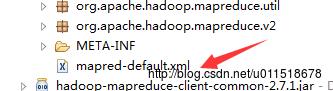
(3)core-default.xml文件在Hadoop-common-version.jar 文件根目录下
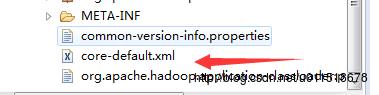
(4)hdfs-default.xml文件在 hadop-hdfs-version.jar文件根目录下
这几个default级别的文件中包含了Hadoop集群最基本也是默认的配置,下面借去了core-default.xml文件的一部分:
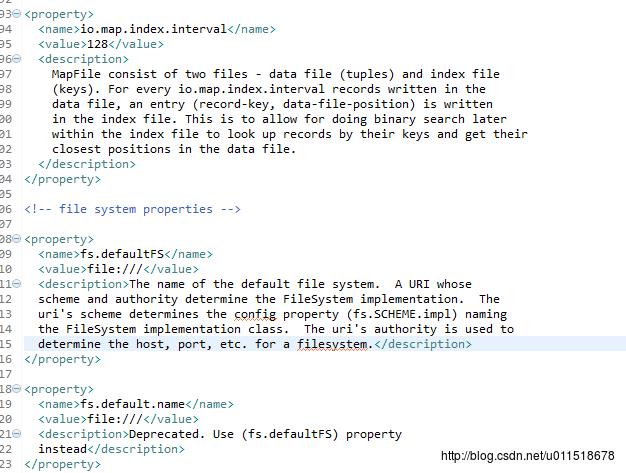
我截取的部分中包括了fs.defaultFS属性,该属性也是我们在搭建HDFS集群时的重要参数,相信有过搭建经理的人对这个参数应该很熟悉。
当Configuration对象对所有的default.xml文件读取完成后,整个Hadoop的参数配置基本航都已经加载完成,但是这些参数的值都是默认值。
2、读取site级别的文件
我们在搭建Hadoop集群时,会通过配置HADOOP_HOME/etc/hadoop/*-site.xml 文件去设置集群参数想,这里的site级别的文件就是指HADOOP_HOME/etc/hadoop文件夹下的带有site的文件。
这些site级别的文件也会被加载到CLASSPATH中,然后Configuration对象才能够进行加载。
# Allow alternate conf dir location.
if [ -e "$HADOOP_PREFIX/conf/hadoop-env.sh" ]; then
DEFAULT_CONF_DIR="conf"
else
DEFAULT_CONF_DIR="etc/hadoop"
fi
export HADOOP_CONF_DIR="$HADOOP_CONF_DIR:-$HADOOP_PREFIX/$DEFAULT_CONF_DIR"# CLASSPATH initially contains $HADOOP_CONF_DIR
CLASSPATH="$HADOOP_CONF_DIR"# CLASSPATH initially contains $HADOOP_CONF_DIR
CLASSPATH="$HADOOP_CONF_DIR"三、设置参数与加载顺序
1、参数设置
当Configuration初始化时,讲defalut级别的配置和site级别的配合加载到了Configuration对象中,这时如果我们还想要修改Configuration对象的值时,可以使用Configration对象的set(key,value)方法进行设置。但是Configuration对象的参数分为可设置参数和不可设置参数两种:
(1)不可设置参数
不可设置参数不是代表这种参数不可以被设置,只是设置了以后不会有作用。这类参数一般都是集群的设置参数,例如集群的可利用内存与CPU核数的两个参数:
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.cpu-vcores上述两个参数指的是datanode节点,yarn占用节点的内存数量与CPU的核数,因为这个参数是集群参数,如果设置了只有在集群重启后才会生效,因此用户在MR任务中设置该数据是无效的。
(2)可设置参数
mapreduce.map.memory.mb
mapreduce.map.cpu.vcores这类参数主要是涉及到HDFS的文件参数,MR任务的单个任务的内存大小或者是CPU核数。这类参数能够在MR开发过程中进行设置,MR在运行过程中会读取并发生相应的表换。
2、加载顺序
Configuration 设置的参数是具有一定顺序并进行加载的: default.xml < site.xml < configuration.set 。
Configuration 在进行参数加载时,首先会加载 default.xml 文件内容,设置好所有的默认值,然后加载site.xml文件,然后site.xml 文件中的参数值将覆盖default.xml 文件中的值,最后Configuration.set() 方法会对已经加载site.xml和default.xml文件的configutaion对象进行修改。
(1)default.xml 类文件是第一次设置
(2)site.xml 类文件是第二次设置
(3)Configuration.set 方法会进行第三次设置
四、任务的Configuration对象信息的存储
当用户提交任务后,Configuration对象的值被序列化以后存储在HDFS上,我们可以在hdfs文件系统的 /tmp 文件夹下找到相应的Configuration对象。这里简单的介绍是Configuration对象存储在hdfs上也是任务提交的一部分,以后会详细介绍MR任务进行远程提交的过程。
以上是关于Hadoop中Configuration类与参数设置规则的主要内容,如果未能解决你的问题,请参考以下文章