图像语义分割 公开数据集 智能驾驶方向
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像语义分割 公开数据集 智能驾驶方向相关的知识,希望对你有一定的参考价值。
前言
本文整理了10个质量较好,数据集较大,比较新的,图像语义分割的公开数据集;主要服务于智能驾驶方向(辅助驾驶、自动驾驶等)。
目录
一、Mapillary Vistas
发布方:IIIT Hyderabad
下载地址:https://www.mapillary.com/
论文地址:
发布时间:2017年(2020年推出,2.0更新版本)
简介:这是一个新颖的大规模街道级图像数据集,通过使用多边形来描绘单个对象,以精细和细粒度的样式执行注释
特征:
- 包含25,000个高分辨率图像,标注为66个对象类别,有37个类别的特定实例的标签
- 采集地点:欧洲、北美和南美、亚洲、非洲和大洋洲的部分地区
- 采集环境:不同的天气,如晴天、雨天、阴天;不同的光照条件,如黎明、黄昏、夜晚
- 采集设备:手机、平板电脑、动作相机、专业拍摄设备
示例:

下载情况:
需要注册账号;无需要审核。可以下载。
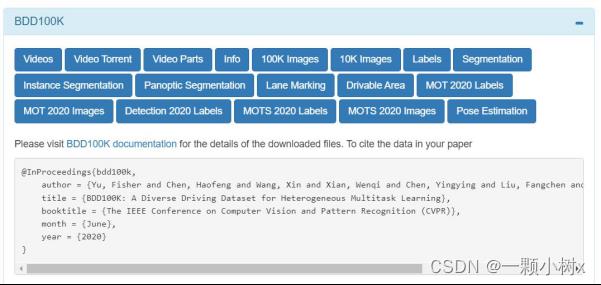
二、BDD100K
发布方:UC Berkeley
下载地址:Berkeley DeepDrive
论文地址:https://arxiv.org/abs/1805.04687
发布时间:2020年
简介:全天候全光照大型数据集,包含1,100小时的HD录像、GPS/IMU、时间戳信息,100,000张图片的2D bounding box标注,10,000张图片的语义分割和实例分割标注、驾驶决策标注和路况标注。总数据量接近2TB。鉴于数据集也是“众筹”的,可能采集设备参数不统一,传感器安装方案不明,但应该不影响数据的使用。
特点:官方推荐使用此数据集的十个自动驾驶任务:图像标注、道路检测、可行驶区域分割、交通参与物检测、语义分割、实例分割、多物体检测追踪、多物体分割追踪、域适应和模仿学习。
示例:

下载情况:
需要注册账号;无需要审核。可以下载。
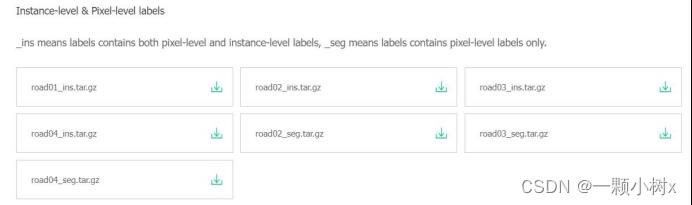
三、ApolloScape
发布方:百度Apollo
下载地址:Apollo Scape
论文地址:
发布时间:2019年
简介:百度公司提供的 ApolloScape 数据集将包括具有高分辨率图像和每像素注释的 RGB 视频、具有语义分割的测量级密集 3D 点、立体视频和全景图像。选择中型 SUV 配备了高分辨率摄像头和Riegl采集系统。数据集是在不同城市的不同交通条件下收集的。每张图像都标记有厘米精度的高精度姿势信息,静态背景点云具有毫米相对精度。数据集能应用于自动驾驶,包括但不限于 2D/3D 场景理解、定位、迁移学习和驾驶模拟。
示例:

下载情况:
需要注册账号(百度、github等);无需要审核。可以下载。
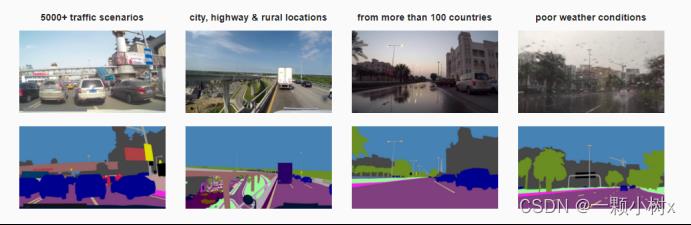
四、Cityscapes
发布方:戴姆勒公司
下载地址:Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
论文地址:
发布时间:2016年
简介:专注于对城市街景的语义理解。大型数据集,包含从50个不同城市的街景中记录的各种立体视频序列
特征:
- 拥有5000张在城市环境中驾驶场景的图片,具有19个类别的密集像素标注,其中8个具有实例级分割
- 一张图片的标注和质量控制平均需要1.5小时
- 高质量的像素级注释为5000帧,另外20000个弱注释帧
- 标注类别:平面、建筑、自然、车辆、天空、物体、人类和空洞
- 标注图像分为训练组、验证组和测试组
示例:

下载情况:
需要注册账号(科研机构);无需要审核。可以下载。
五、Highway Driving
发布方:韩国科学技术院(Korea Advanced Institute of Science and Technology)
下载地址:https://sites.google.com/site/highwaydrivingdataset/
论文地:https://arxiv.org/pdf/2011.00674.pdf
发布时间:2019年
简介:高速公路驾驶数据集是一个密集标注的语义视频分割任务的基准,它所提供的标注在空间上和时间上都比其他现有的数据集更密集。每一帧的标注都考虑到了相邻帧之间的关联性
特征:
- 由20个60帧的序列组成,帧率为30Hz
- 数据集分成训练集和测试集,训练集由15个序列组成,而测试集由剩下的五个序列组成
- 帧率为30Hz的短视频片段是在高速公路驾驶的情况下拍摄的
- 包含道路、车道、天空、栅栏、建筑、交通标志、汽车、卡车、植被和未知10类标签。未知类包括未定义的物体、采集数据的车辆的引擎盖和模糊的边缘
类别与颜色:

示例:

下载情况:
需要注册账号;且能访问谷歌网盘。暂无下载。
六、Wilddash
发布方:奥地利技术研究所
下载地址:WildDash 2 Benchmark
论文地址:
发布时间:2018年
大小:10.8G
简介:这是一个用于汽车领域的语义和汽车领域的实例分割的新测试数据集。它具有以下优点:(i) 允许对失败的测试进行回溯,以发现视觉上的风险因素;
(ii) 增加负面的测试案例,以避免假阳性; (iii)具有低区域偏差和低相机设置偏差
特征:
- 包含了全球多样性的交通状况,包括来自世界各地的测试案例
- 通过拥有大量来自不同国家的道路场景、道路布局以及天气和照明条件,减少了数据集的偏差
- 具有视觉危害和改进的元信息的场景,为每个测试图像阐明涵盖了哪些危害
标注:道路、人行道、停车场、铁轨、人、骑手、汽车、卡车、公共汽车、铁轨、摩托车、自行车、大篷车、建筑物、墙壁、栅栏、护栏、桥梁、隧道、电线杆、交通标志、交通灯、植被、地形、天空、地面、动态和静态。
示例:
下载情况:
需要注册账号;且需要经过审核。暂无下载。
七、IDD
发布方:IIIT Hyderabad
下载地址:IDD
发布时间:2018年
简介:这是一个用于理解非结构化环境中的道路场景的数据集,它反映了与现有数据集明显不同的道路场景的标签分布
特征
- 由10,004张图像组成,用34个类别进行精细标注,这些类别采集于印度公路上的182个驾驶序列(完)
- 分辨率以1080p为主,也有720p和其他分辨率的图像
- 采集环境:海德拉巴、班加罗尔等城市及其郊区,采用车载摄像机拍摄
示例:

下载情况:
需要注册账号;无需要审核。可以下载。
八、Lost And Found
发布方:戴姆勒公司
下载地址:https://www.6d-vision.com/current- research/lostandfounddataset
论文地址:https://arxiv.org/pdf/1609.04653.pdf
发布时间:2016年
简介:关注于检测道路上由丢失货物引起的意外小障碍物的问题。数据使用ZED被动双目采集,共有2104标注好的数据。数据提出后的几年有多个数据集效仿(如seg me if you can 、SOD),同时有40+的算法将此数据集作为benchmark
特征
- 包含112 个立体视频序列和 2104 个带注释的帧(从记录的数据中大约每十分之一帧挑选一次)
- 在200万像素的立体图像上,帧率高达20赫兹
- 包括13个不同街道场景的记录,具有37种不同的障碍物类型
- 选定场景包含特殊的挑战,包括不规则的道路轮廓、远距离、和强烈的光照变化
- 立体相机设置的基线为21厘米,焦距为2300像素,空间和辐射测量分辨率为2048×1024像素和12比特
示例:

下载情况:
需要注册账号(科研机构);无需要审核。暂无下载。
其他障碍物分割数据集:seg me if you can:Datasets
九、Argoverse 2
发布方:
下载地址:https://www.argoverse.org/av2.html
论文地址:
发布时间:2021年
简介:用于感知和自动驾驶领域的预测研究。带注释的传感器数据集包含1,000个多模式数据序列,包括高分辨率图像除了激光雷达点云,来自七个环形摄像机和两个立体摄像机,和6-DOF地图对齐姿势。序列包含26个3D长方体注释对象类别,所有这些都经过充分采样以支持训练和3D感知模型的评估。激光雷达数据集包含20,000个序列未标记的激光雷达点云和地图对齐的姿势。这个数据集是最大的收集激光雷达传感器数据并支持自我监督学习和点云预测的新兴任务。最后,运动预测数据集包含250,000个场景,用于自动驾驶汽车与每个本地场景中的其他参与者之间有趣且具有挑战性的交互。在所有三个数据集中,每个场景都包含自己的 3D 高精地图车道和人行横道的几何形状——来自六个不同城市的数据。
示例:

下载情况:
需要注册账号;无需要审核。可以下载。
十、nuScenes
发布方:Motional
下载地址:https://www.nuscenes.org/nuscenes
论文地址:nuScenes: A Multimodal Dataset for Autonomous Driving | IEEE Conference Publication | IEEE Xplore
发布时间:2020年
简介:由Motional(前身nuTonomy)提供的全天候全光照数据集。注册账号之后就可以下载所有数据,总数据量在300GB以上。官方提供了数据使用接口,并提供了Detection, Tracking, Prediction, Lidar Segmentation四类任务的挑战榜,还可以支持语义分割,实例分割,多模态数据融合,端对端决策等问题的研究。目前该数据集仍然在持续更新,属于质量比较高的数据集。
示例:

下载情况:
需要注册账号;无需要审核。可以下载。
参考1:https://zhuanlan.zhihu.com/p/522121257
参考2:https://zhuanlan.zhihu.com/p/356976113
本文只供大家参考与学习,谢谢~
以上是关于图像语义分割 公开数据集 智能驾驶方向的主要内容,如果未能解决你的问题,请参考以下文章