图像分类MobileNet: 一点创新两个超参
Posted 行路南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像分类MobileNet: 一点创新两个超参相关的知识,希望对你有一定的参考价值。

MobileNet是2017年由Google提出的一个应用于移动端和嵌入式的卷积神经网络。它的主要应用场景包括有智能手机、无人机、机器人、自动驾驶、增强现实等等。
在这之前,研究者更多还是关注于精度的提升,模型也是朝着深度更深、结构更复杂的方向发展。从最初12年提出的8层的AlexNet、再到14年各领风骚的19层的VGG和22层的GoogLeNet、再到15年何凯明大神提出的152层的ResNet。可见,深度是越来越深,精度是越来越高。
但与此同时,这些网络的参数和计算量也是足够的大,很难在移动端和嵌入式设备中使用。
本文介绍的MobileNet就是一个针对移动端、参数量和计算量都大幅减小,同时精度很高的一个高效卷积神经网络。
我对MobileNet的总结是八个字: 一点创新,两个超参。
1 一点创新
那么MobileNet 有哪些创新之处呢?
其实最主要的创新就只有一点。那就是采用了depthwise separable convolution, 中文叫法是深度可分离卷积。
如果之前没听过,听这个名字感觉很高大上的样子。其实如果你了解标准的卷积操作,那么了解它也是很容易的事情。
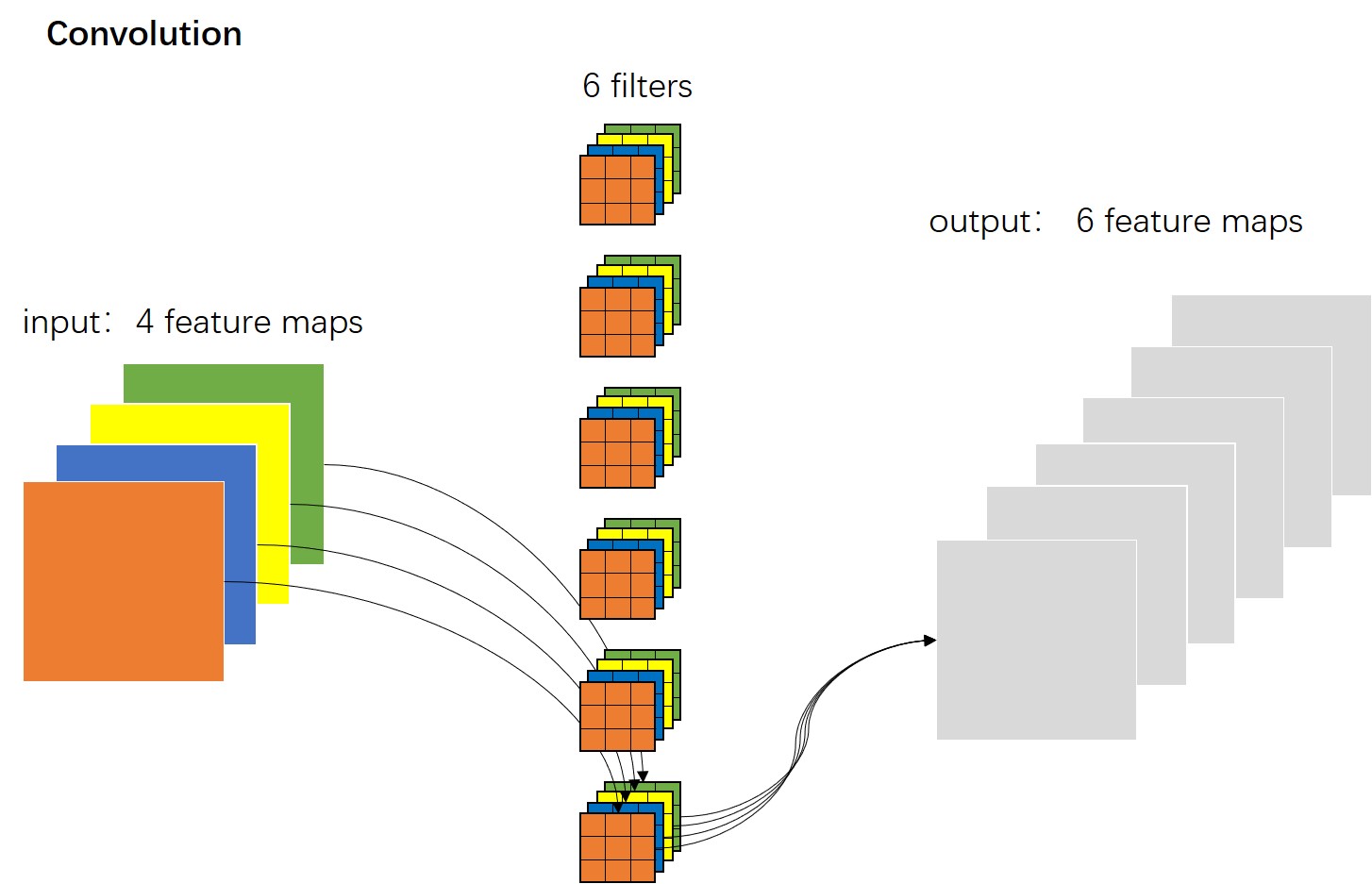
如上图所示,这是一张标准卷积的示意图。我们看到一个标准的卷积操作中既包含对输入特征图的过滤,又包含基于通道方向的组合。
深度可分离卷积所做的就是对标准卷积的分解,分解为一个depthwise convolution 和一个pointwise convolution 。(下文中,分别称之为DW卷积和PW卷积)
也即是说,在MobileNet的网络中不再使用标准卷积,而是采用这两个DW卷积和PW卷积来代替。
那么,什么是DW卷积和PW卷积呢?
1.1 DW卷积

这是DW卷积的示意图。我们看到,它的卷积核个数和输入特征图的通道个数一致(上图中均是4个),每个卷积核只有一个通道,作用于输入特征图的对应深度上。
它与标准卷积不同的是:在标准卷积中,每个卷积核的通道数是与输入特征图的通道数一致的,每个卷积核都与输入特征图在空间宽度、高度和深度上进行过滤和组合,并形成一张特征图;且有N个这样的卷积核,最终形成的输出特征图也就是通道数为N的特征图。
而DW卷积,明显简化了许多。它的一个卷积核只有单个通道,只负责输入特征图深度方向的一层特征图。这样很明显参数量会大大减少。(在下一节中会给出具体数据)
仅仅只有depthwise convolution是不够的,因为它只实现了对输入特征图宽度和高度的过滤操作,并没有对通道方向进行组合。因此我们还需要一个组合的操作。这便是PW卷积要做的事情。
1.2 PW卷积
PW卷积就是普通的1*1卷积。
我们之前介绍过,1*1卷积实现了对输入特征图在通道方向上的加权组合,来生成新的特征图。并根据卷积核的个数的多少,决定输出特征图的通道数。
因此,我们这里就使用一个1*1卷积,来对DW卷积的输出结果在通道方向进行线性的组合。
如下图所示,可以看到和标准卷积的区别,只是卷积核变为了1*1的大小。

1.3 对比标准卷积与深度可分离卷积的计算量
接下来,我们分析一下,采用DW卷积和PW卷积组合的这种深度可分离卷积,是如何大幅度减少网络参数的。
我们不妨设输入的特征图大小为 D F ∗ D F ∗ M D_F * D_F *M DF∗DF∗M,其中 D F D_F DF表示输入特征图的空间宽度和高度, M M M表示输入特征图的通道数(深度);
假设卷积核大小为 D K ∗ D K ∗ M ∗ N D_K * D_K * M * N DK∗DK∗M∗N,其中 D K D_K DK表示卷积核的空间宽度和高度, M M M表示输入特征图的通道数,N表示卷积核的个数; 且卷积核的步距stride=1,采用same padding的填充方式。
那么一个标准卷积计算量是:
D
K
∗
D
K
∗
M
∗
N
∗
D
F
∗
D
F
D_K * D_K * M * N * D_F * D_F
DK∗DK∗M∗N∗DF∗DF
其中$D_K * D_K * M $ 是计算得到输出特征图中的一个点的计算量,且输出特征图中一共有
N
∗
D
F
∗
D
F
N * D_F * D_F
N∗DF∗DF个点。
一个DW卷积的计算量是:
D
K
∗
D
K
∗
M
∗
D
F
∗
D
F
D_K * D_K * M * D_F * D_F
DK∗DK∗M∗DF∗DF
其中
D
K
∗
D
K
D_K * D_K
DK∗DK是计算得到输出特征图中的一个点的计算量,且输出特征图中一共有
M
∗
D
F
∗
D
F
M * D_F * D_F
M∗DF∗DF个点。
一个PW卷积的计算量是:
M
∗
N
∗
D
F
∗
D
F
M * N * D_F * D_F
M∗N∗DF∗DF
因为PW卷积只是标准卷积的特殊形式,只是卷积核大小
D
F
=
1
D_F = 1
DF=1。
最后,我们标准卷积与深度可分离卷积的计算量的结果是:
D K ∗ D K ∗ M ∗ D F ∗ D F + M ∗ N ∗ D F ∗ D F D K ∗ D K ∗ M ∗ N ∗ D F ∗ D F = 1 N + 1 D K 2 \\fracD_K * D_K * M * D_F * D_F+M * N * D_F * D_FD_K * D_K * M * N * D_F * D_F = \\frac1N+\\frac1D_K^2 DK∗DK∗M∗N∗DF∗DFDK∗DK∗M∗DF∗DF+M∗N∗DF∗DF=N1+DK21
因为卷积核大小 D K D_K DK通常设置为3,输出通道数N往往大于 D K 2 D_K^2 DK2,所以标准卷积的计算量大约是深度可分离卷积的8到9倍。
1.4 网络结构

MobileNet的网络结构很简单。我们仔细看这个表格,就会发现里面的层只有这么几种的堆叠:标准卷积、DW卷积、PW卷积、平均池化、全连接层。
需要多说的一点是,这里的每个卷积层后面都跟着BN和ReLU,这两个已经是卷积网络中的标配了。BN的目的是正则化来防止过拟合,ReLU是最主流的激活函数。
如果我们数一数MobileNet的带有权重的层,会发现一共有28层。
到此呢,MobileNet的基本内容已经说完了。下面说一下两个特别的超参数。
2 两个超参
虽然一个MobileNet模型已经很小、速度很快了,但有时候在特定的场景下,可能需要模型更小和更快。那么为了满足更小和更快的需求,作者分别引入了一个宽度系数 α \\alpha α和一个分辨率系数 β \\beta β。
2.1 宽度系数 α \\alpha α
具体说来,宽度系数就是对网络上的每一层卷积的通道数都乘以一个相同的因子
α
\\alpha
α,
α
\\alpha
α大于0且小于1。
举个例子,在MobileNet basic版本中第一个卷积层通道数是32,第二个卷积层通道数是32,第三个卷积层通道数是64…,那么当宽度系数
α
\\alpha
α为0.5时,这些卷积层的通道数分别变为16,16,32,…
这样做的效果就是整个网络整体变窄了。当然计算量也会随之变少。
在下表中可以看出,随着 α \\alpha α的减少,计算量和参数会随之减少。

2.2 分辨率系数 β \\beta β
另一个是分辨率系数
β
\\beta
β,也就是设置不同的输入图像的分辨率大小。当我们对输入的图像大小变为原始图像的
β
\\beta
β倍数时,会使得后继所有层的输入特征图都会缩小
β
\\beta
β。
需要注意的一点是,改变分辨率,只会对整个网络的计算量有影响,对参数量是不受影响的。下图是随着分辨率的减少,计算量也随之减少。

3 小结
通过上述的介绍,我们发现MobileNet 的创新主要就是深度可分离卷积。然而就是这样的改进,就能在保持准确率仅仅略微下降的同时,大幅度的降低了参数数量和计算量。
同时提供了两个可以灵活调整的超参数,使得我们可以根据自己的设备资源情况,合理设置参数的大小,从而满足我们对更快、更小模型的需求。
本文介绍到这里就结束了,后来Google又提出了MobileNetV2和V3系列,但我打算按照时间线的方式去介绍,下一篇文章介绍同一年提出,效果更惊艳的ShuffleNet。
喜欢请不要吝啬你的点赞,我是行路南,下一篇文章见。
欢迎交流与转载
文章同步发布在公众号:CV前沿
以上是关于图像分类MobileNet: 一点创新两个超参的主要内容,如果未能解决你的问题,请参考以下文章