使用Python,几行代码实现OCR图片识别,附测试图片和识别效果
Posted 秋9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python,几行代码实现OCR图片识别,附测试图片和识别效果相关的知识,希望对你有一定的参考价值。
目录
1.具体如何做呢?
1.1安装Tesseract-OCR
windows安装包下载地址:https://github.com/UB-Mannheim/tesseract/wiki
下载的文件名为tesseract-ocr-w64-setup-v5.2.0.20220712.exe
右击管理员运行tesseract-ocr-w64-setup-v5.2.0.20220712.exe




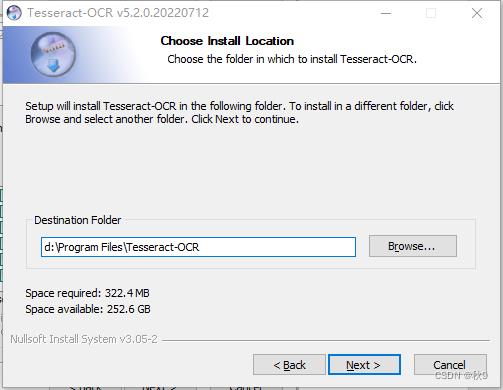
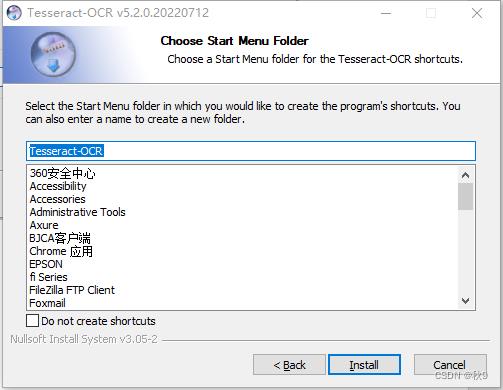

1.2配置环境

1.3安装Tesseract中文包
下载地址和如何安装,见另外一篇分享文章
Tesseract最新中文语言包chi_sim.traineddata(4.0.0)三种获取方式_秋9的博客-CSDN博客
1.4.安装pytesseract和pillow
pip install pytesseract 和pip install pillow
具体操作如下:
D:\\1\\ocr>pip install pytesseract
Collecting pytesseract
Downloading pytesseract-0.3.10-py3-none-any.whl (14 kB)
Requirement already satisfied: Pillow>=8.0.0 in d:\\python\\python381\\lib\\site-packages (from pytesseract) (9.2.0)
Collecting packaging>=21.3
Downloading packaging-21.3-py3-none-any.whl (40 kB)
|████████████████████████████████| 40 kB 123 kB/s
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in d:\\python\\python381\\lib\\site-packages (from packaging>=21.3->pytesseract) (2.4.7)
Installing collected packages: packaging, pytesseract
Attempting uninstall: packaging
Found existing installation: packaging 21.0
Uninstalling packaging-21.0:
Successfully uninstalled packaging-21.0
Successfully installed packaging-21.3 pytesseract-0.3.10
WARNING: You are using pip version 21.0.1; however, version 22.3 is available.
You should consider upgrading via the 'd:\\python\\python381\\python.exe -m pip install --upgrade pip' command.
D:\\1\\ocr>pip install pillow
Requirement already satisfied: pillow in d:\\python\\python381\\lib\\site-packages (9.2.0)
WARNING: You are using pip version 21.0.1; however, version 22.3 is available.
You should consider upgrading via the 'd:\\python\\python381\\python.exe -m pip install --upgrade pip' command.
D:\\1\\ocr>
2.代码和测试效果
2.1识别英文图片
代码如下:
from PIL import Image
import pytesseract
path="test2.png"
im=Image.open(path)
text=pytesseract.image_to_string(im)
print(text)test2.png图片如下:

识别效果:

结论:只有第1个字母识别错误
2.2 识别中文图片
代码如下:
from PIL import Image
import pytesseract
path="test4.png"
im=Image.open(path)
text=pytesseract.image_to_string(im,lang='chi_sim')
print(text)test4.png图片如下:

识别效果:

中文识别效果比较差。
欢迎小伙伴们,留言讨论
以上是关于使用Python,几行代码实现OCR图片识别,附测试图片和识别效果的主要内容,如果未能解决你的问题,请参考以下文章