实验2后篇——内存管理算法
Posted yiye_01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验2后篇——内存管理算法相关的知识,希望对你有一定的参考价值。
实验2介绍了操作系统的基本内存管理,或者说是系统内存管理的软件接口实现。这对于我们实际上碰到的内存管理操作有一些差距,所以我们这一节补充一些内容,来详细介绍一些内存管理技术。
这里要对实验2进行一些补充说明,实验2的代码实现主要参考源码中给的提示信息,而代码实现是否正确,这里没有老师检查也没有任何可参考的代码,而原课程设计有一个很巧妙的方法,使用assert机制来检测各个接口实现,通过代码的方式来检测每个接口是否正确。这是多么有意义的做法呀,想想我们在学习代码的过程中,都是拷贝别人的代码修改之,或者由有经验的人来指导,这样当我们碰到问题时,就很容易丧失自主思考的能力,而且很容易去对比已经有的代码,从而忽略了程序运行本身。
我不想去重复赘述教科书上的一些概念与总结的言辞,而用实际行动与代码的剖析去替代。这样可以让我们的代码更有活力,能够被更好的理解与使用到其他的项目中。有时虽然有些低劣,但是有一种解决方案为我们指明方向,然后沿着它不断摸索,不断改进,产生更好的解决方案。内存管理的终极目标是以最少的内存消耗实现最快的内存分配。本将以如下4个方面去详细介绍内存管理方案——malloc/free两种实现方式,伙伴算法分配方案,slab分配算法。这些管理方案在linux的内核中都有合理的使用,这样就是很复杂的过程,但是效率很高。对于malloc/free的实现方法有两种,一种是从unix V6中拿出来的,另一种是我修改的变种,这两种方式其实为实现内存管理的接口提供了原始而基本的解决方案。另外两种方法主要是为了解决内存分配时的碎片问题而产生的算法,它们都是从unix的分支sun-os中产生的算法,伙伴算法解决外部碎片,slab算法解决内部碎片,当然它们还有其他妙用,见各个部分详细介绍。
一)unix v6版本的malloc/free实现分析
首先,我介绍的是比较原始的malloc/free的代码实现,它是源自于《莱昂氏UNIX源代码分析》分析中的malloc.c中详细介绍。我将从两个方面来详细介绍它——其一源码分析,其二为代码运行仿真。
A)源码分析——对于内存管理的基本操作就是分配(malloc)与释放(free)。我还是从面向对象的角度来描述,另外在描述内存管理的方式一种形象的方法为用逻辑示意框图来描绘,对我们理解是很有意义的。所以我们先以框图来描述代码实现的逻辑如下:
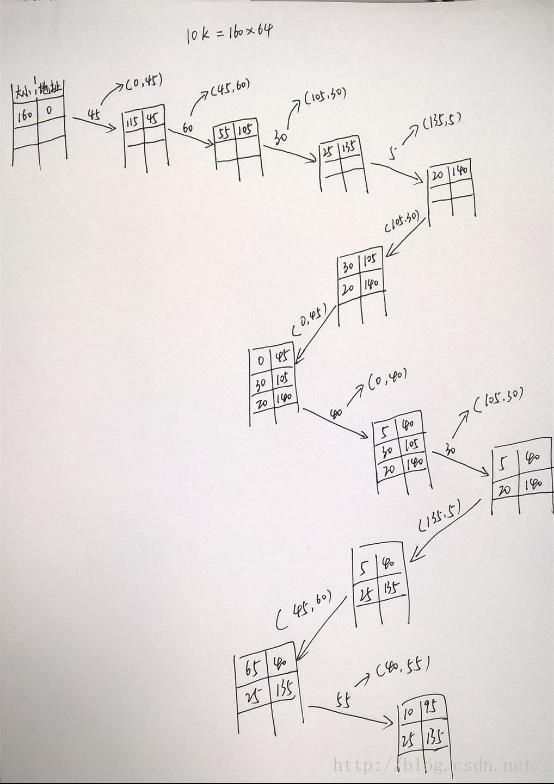
如上图所示:我们以10K大小的内存空间为分配与释放对象,每64Byte为分配单元,所以10K大小有160个分配单元。从左上角开始,我们用一个数组记录可以分配的空间对——分配的开始地址与大小,所以当程序开始时为(160,0)——开始地址为0,有160个分配空间,然后从左向右是不断分配内存块,而从右往左是释放内存块。在分配过程中以“分配大小首次适配”为分配对象,分配时当分配大小与当前可分配大小一致时,需要将该分配对从该数组中清除;在释放过程中需要检测当前释放的内存是否能与可分配对的关系,如果能够连接在一起,则将相关的分配对进行大小调整。
以面向对象的方式来描述分配算法:
属性:
struct map//分配对
char *m_size;//可分配的内存大小
char *m_addr;//可分配的内存开始地址
;
方法:
输入:mp为分配对数组
Size为分配的大小
输出:分配得到的开始地址
int malloc(struct map *mp,int size);//从分配对数组中,分配size大小的内存空间。
输入:mp为分配对数组
size为释放的空间大小
aa为释放的空间开始地址
void mfree(struct map *mp,int size,int aa);//将已经分配的内存(以分配对表示(aa,size))释放到分配对数组中。
实例化:
int coremap[CMAPSIZ];//静态申请分配对数组。
B)代码仿真
针对如上的描述只是对概念的介绍,而更详细的分析,需要查看附件的代码以及注释,如果纯粹的贴代码,这对博客是一种伤害。当然根据如上我的介绍也可以自己实现相关代码。对于这部分代码是比较独立的代码,我们可以直接将代码从莱昂氏的代码中拷贝出来,自己写一个main函数来调用之,然后再用打印将如上的分析结果给打印出来;当然也可以用gdb去单步调试malloc与mfree的详细流程。
代码参考附件中的unixMalloc_org中的代码。
为了实现c语言标准库中的malloc与free方法,我们需要对代码进行接口修改,然后增加一些代码来实现,使用多申请一个int的空间来保存申请的大小,或者通过使用动态链表来实现。
代码参考附件中的unixMalloc_macro。当然它也增加了一系列宏来修改代码增强代码可读性。
二)另一版的malloc/free实现分析
针对unix版本给出的代码,我们将整体分析分配空间的处理,其实可以用下图来表示:

如上图所示,我们将整个内存使用空间分配为两部分一部分为分配索引(代码中coremap)——用于记录与管理分配空间的使用情况,而另一部分为分配空间(代码中space)实际提供给其他系统使用的空间。这种结构跟现在的文件系统是一致的。这样的坏处是索引空间会比较浪费。
针对如上情况我们有另外一种实现方式将内存使用空间以帧的方式来进行分配管理,如下如图所示:
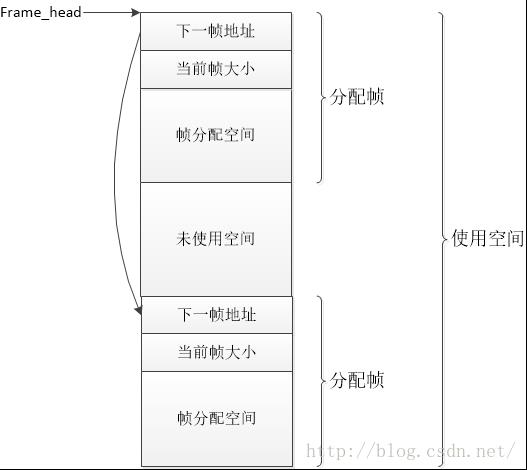
如上所示,我们将整个内存使用空间分配为不同的分配帧——分配帧用于记录已经使用的内存块,而每个分配帧的都有下一帧地址——用于将所有帧连接成链表(表头用frame_head指向)与当前帧大小。如上的算法流程可以看作将unix算法的分配索引整合到分配空间。为了与之前的讲解一致,我们也从类似的方法来讲解。
A)源码分析——先以分配逻辑示意图的方法来演示,而且也以相同的测试代码来实现。如下图所示:
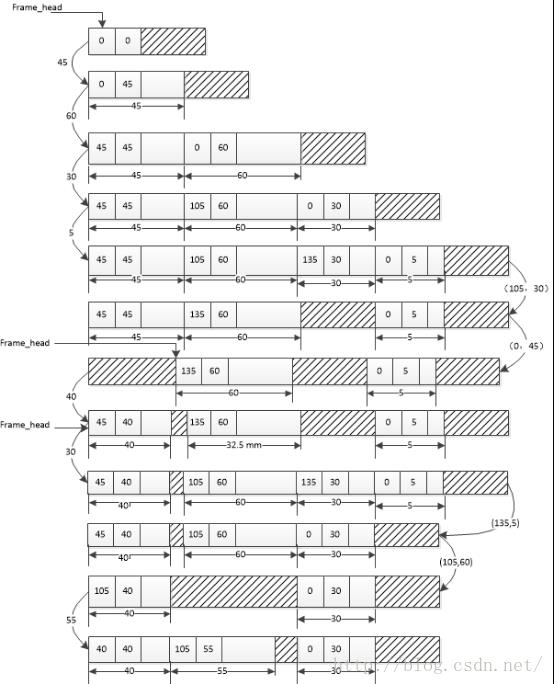
如上图所示,左边标记了内存分配,右边标记了内存释放,阴影部分为未使用的内存空间,而frame_head修改只在其值发生变化时发生。
以面向对象的方式来描述分配算法:
属性:
struct frame_map//记录已经分配的帧
struct frame_map* next_frame_addr;//下一帧的地址
int cur_alloced_size;//当前帧的大小
;
方法:
输入:申请的内存大小
输出:申请得到的内存地址
int frame_malloc(int size);//通过帧算法得到分配的内存
输入:释放的内存地址
输出:是否释放成功
int frame_free(int addr);//释放已经分配的内存
B)代码仿真——我们将测试unix的代码放入其中进行测试即可,通过添加打印与单步调试来分析代码实现,在附件frame_alloc目录下。
为了方便调试方便,我们用顶层makefile来管理代码仿真的部分。
make org 为编译unix源码的malloc与mfree代码
make macro 为编译修改过的unix源码的代码
make frame 为我们实现的帧分配算法
三)伙伴系统算法——buddy
伙伴系统作为一种有效的内存分配方法,在很多地方都有使用,对于我们需要理解它的实现流程,并能够编写实现它的代码。对于它的描述,常见的分析方法有两种——其一是从分配效率,其二是从内存使用碎片方式。
我们摘录了很多参考手册上的分析方法在附件中,详细列表如下:
1.《操作系统精髓与设计原理(原书第6版)》第7.2.3节
2.《计算机程序设计艺术(第一卷)》第2.5节,C算法。
为了直观的理解伙伴系统算法我们还是用图的方式来描述内存分配与释放,来至参考文献1:
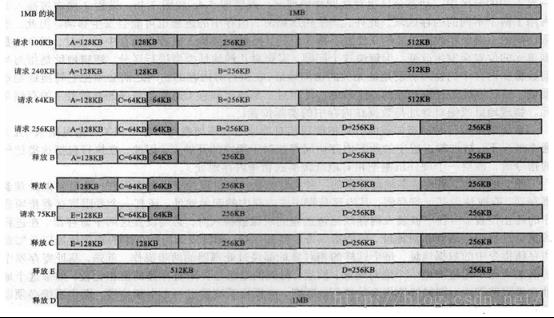
如上图所示,我们有1MB的空间用于分配使用,首先A请求100KB,我们分配了128KB(因为所有的分配单元必须为2^n),同时在分配128KB时,我们将剩余的内存分割为512KB,256KB,128KB,方便内存管理。然后B请求240KB,需要我们分配256KB给它,因为已经有了256KB,所以直接给了。C请求64KB,我们再将128KB分割,然后分配。D请求256KB,我们将512KB分割,然后分配之。释放B时,我们直接释放掉,再直接释放A。再请求75KB,又分配了128KB,在A释放的区域。释放C时,我们将剩余的64KB(伙伴)进行合并。释放E时,将剩余的128KB,256KB进行依次合并,释放D时将所有的又合并成1MB。
对于如上的描述,我们给出了直观的描述,但是我们需要明白一些概念:
1.分配单元(这是所有分配算法都会用到的),伙伴算法的分配单元都为2^n的空间。
2.伙伴:从同一块内存分配成两块的子内存。它们的特点是大小相等,地址连续。从参考资料2,我们还得到一个很有用的公式:

如上公式很抽象,我们以实例说明:大小为32(2^5)的地址为xxxx.....00000(x为0/1),它分割的伙伴地址分别为xxxx.....00000与xxxx.....10000。这对伙伴的地址可以看作将原地址的第4位进行0/1划分。换句话说如果我们知道了伙伴之一的地址,对其第4位进行异或运算就可以得到另一伙伴的地址,而且将第4位清0就可以得到分配的地址,为此,我们可以得到快速算法。而不用去反复递归。
3.分配与释放策略:当在分配内存时,如果能够直接找到适合的内存大小,直接给予就好,否则需要对剩余内存进行伙伴拆分,直到满足分配的单元。当释放内存时,需要对已经存在的内存进行归并——合并所有伙伴,直到没有伙伴合并。
算法实现——我们将以两种方式实现(递归与二进制地址分配方式):
实现的接口如下——目前我们实现的都是在模拟算法,而没有在实际中使用,因为在实际使用时,可能没有malloc与free或者这些接口是要我们实现的(其实,可以预先静态分配为数组):
属性:
typedef struct addr_node//用于保存未分配的伙伴地址,并且连接成链表
unsigned long start_addr;//保存未分配的伙伴地址
struct list_head next;//双向链表
addr_node_t;
方法:
void buddy_init();//初始化伙伴算法的数据结构与规范要分配的内存空间。
输入:分配大小
输出:分配的地址
void* buddy_alloc(int sz_by_order);//根据给的大小分配地址
输入:addr为已经分配的地址
sz_by_order为已经分配的大小
void buddy_free(void * addr,int sz_by_order);//释放已经分配的地址与大小。
void buddy_destroy();//释放伙伴算法的数据
初始化:
struct list_head free_ls[MAX_ORDOR];//记录伙伴算法每个分配单元的链表头
说明:
在算法实现过程中,我们使用了双向链表(struct list_head),而它的实现,是从linux内核进行拷贝出来的。它的实现很巧妙,在内核中得到广泛的使用,它的实现方式将链表的关系与实际保存的数据进行了分离,而且使用宏的方式来时实现简单方便,快捷。如下为一个使用demo,当然也可以在附件中找到。
#include "include_linux_list.h"
#include <stdio.h>
#include <stdlib.h>
typedef struct List//定义使用linux内核双向链表的结构
char* data;//保存的数据
struct list_head link;//双向链表的关系
List;
int main(int argc,char ** argv)
struct list_head head;//定义表头
struct list_head* p_one;
int i;
List* one_str;
INIT_LIST_HEAD(&head);//初始化表头
for(i=0;i<argc;i++)
one_str = malloc(sizeof(List));
one_str->data = argv[i];
list_add(&one_str->link,&head);//将元素添加到链表中
list_for_each(p_one,&head)
one_str = list_entry(p_one,List,link);//得到链表中的元素
printf("%s\\n",one_str->data);
free(one_str);
return 1;
在代码实现过程中,使用二进制地址分析的方法只是加速了代码的实现,而基本流程是一致的。
四)Slab分配策略
对于这种内存管理方法,纯粹是从实践观察中得到的,而详细的介绍,我们会从《The.Slab.Allocator》的论文中得到,如下为我们从论文中截取的,让人感兴趣的部分。因为它的分配效率的高效性,在很多操作系统中都得到很好的实现。当然linux也不例外,对它的理解也是理解linux内存管理很重要的部分;
思想来源:
对于前面几种内存分配算法都是将内存释放到整个内存中,而slab分配策略则是基于实际使用中对象的内存管理,将以运行过程中申请的内存为对象,进行分配,缓存,释放。对象缓存是一项处理经常被分配与释放的对象。它的思想来源于保持对象初始化的状态的不变性——构造态,这样之后,就可以避免在使用对象时需要每次都销毁与初始化。从而保证了算法的有效性。
算法的优势:
1.对内核经常使用的对象进行缓存,这样保证了多次使用时的分配速度会很快
2.对类似大小的对象进行缓存,这样避免了常见的内存碎片的问题——主要是内部碎片,同样对外部碎片也有很好处理。
3.常用了硬件缓存对齐与着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
算法实现——基于经典的分层模型:
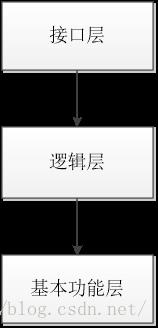
这种模型之前我们也描述过程,这样结构对我们理解代码实现,实际运用以及模拟仿真都有很好的意义。比如:在linux平台上,基本功能层是使用的是伙伴算法实现实际的内存分配,而对于我们代码模拟过程,也是从linux内核2.4中截取的代码,然后用malloc与free来替代了内核中的伙伴算法,从而对这部分代码进行调试,分析。
接口层设计:
接口的设计需要考虑如下两点:
(A)对象的属性描述(大小,对齐,名字,构造与析构函数),从属于实际使用的地方,而不是由分配器所决定。因为分配器不知道所有使用的内存大小与构造/析构时所做的操作。
(B)内存的管理策略应该时分配器所要考虑的,而不是由客户端所决定的。客户端只需要使用分配与释放的接口即可,而不用去考虑内在的分配效率与算法。
针对A的设计点,就必需设计客户端驱动(由客户端调用)的且包含所有属性的接口:
(1)struct kmem_cache *kmem_cache_create(
char *name,
size_t size,
int align,
void (*constructor)(void *, size_t),
void (*destructor)(void *, size_t));
该接口用于创建一个对象的缓存,它需要对象的大小与对齐情况。对齐(align)指的是对象需要基本的内存分配的限定,它可以为0,服从系统默认的对齐机制。名字(name)用于统计与调试。构造函数(constructor),对象被创建时的构造函数,只被调用一次。析构函数(destructor)用于对象被回收时,也只被调用一次。构造与析构函数使用大小作为参数,是用于支持相似的缓存实现类似的操作。该接口返回使用该缓存的唯一标识。
针对B的设计点,客户端需要简单的分配与释放的接口既可:
(2)void *kmem_cache_alloc(
struct kmem_cache *cp,
int flags);
分配对象的接口——从缓存中获取一个对象。对象必需处于构造状态。flags为KM_SLEEP or KM_NOSLEEP,表明是否能够理解获得内存资源。
(3) void kmem_cache_free(
struct kmem_cache *cp,
void *buf);
返回一个对象到缓冲中。对象依旧处于构造状态。
(4)void kmem_cache_destroy(
struct kmem_cache *cp);
销毁一个缓存,释放所有资源。所有分配的对象都必需返回给缓冲。
这些接口允许我们创建灵活的分配器适应客户端的理想的需求,当然也可以定制相关的接口。对象缓存的接口使客户端可以使用它们所需要的分配器的服务。
逻辑层设计——我们分析的linux内核2.4中的代码实现,而参考了论文中的实现描述:
从代码实现的角度来说,slab分配器的实现主要是使用形如 struct slab_s的结构体对对象缓存进行逻辑管理。
为了理解设计思路与逻辑实现我们需要理解如下几个概念:
1.对象——程序中数据结构对内存的实际需求,可以分为大,中,小
2.Slab——管理对象的基本结构,可以说是维系缓存与对象的纽带,分为空,部分满,全满。
3.缓存——cache,用于组织与管理slab与对象,一个cache对应一种对象
它们的关系如下图所示:
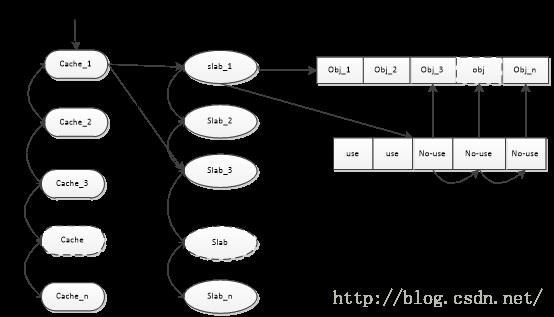
如上图所示,slab分配器系统是由一系列的对象缓冲块链接在一起,每个缓冲(cache)包含了缓冲对象的属性以及slab的列表,slab列表是以满的slab开始,其中第一个非满的slab也被cache所指向;而slab又管理了所有的对象(obj)列表,而没有使用的对象链接到slab的free指针上。
对于染色的理解为将对象的开始地址(s_mem)以硬件缓冲对齐的方式偏移,这样就可以充分利用硬件缓冲的特性来加速对内存的访问。
算法仿真——对于linux内核的代码有很多考虑,比如:对多处理器兼容,多进程访问加锁,proc文件系统的添加等,而实际我们仿真时不需要,所以需要将它们注释掉;linux在功能层实现实际物理分配使用了伙伴分配算法,而我们只需要对接分配与释放内存的代码即可——在附件中page.c中实现。
一叶说:内存管理在系统软件或者应用软件运行无疑起了核心的作用,所以值得我们去分析具体实现。而真正好而有效内存管理就是根据实际使用环境进行组合使用。当然,这些在linux内核中的使用就是一个很好的示例。如本博客描述的算法都在附件中有实现,希望对感兴趣的人员提供参考。对于内存管理的理解,更多的是能以逻辑图的方式将分配与释放的过程形象的表达出来。
以上是关于实验2后篇——内存管理算法的主要内容,如果未能解决你的问题,请参考以下文章