数据分析——pandas
Posted hellobigorange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析——pandas相关的知识,希望对你有一定的参考价值。
😊作者简介:大家好我是hellobigorange,大家可以叫我大橙子
📃个人主页:hellobigorange的个人主页
🔥系列专栏:数据分析(pandas-numpy-matplotlib)
💖写在前面:前段时间好多小伙伴问我数据分析的相关内容,因此我考虑了一下准备暂且放下时间序列预测专栏的编辑,先写一下数据分析专栏
📰如果觉得博主的文章还不错的话,请👍三连支持一下博主哦🤞11/04/2022 20:00

文章目录
pandas 是数据分析不必可少的工具, 这篇文章带大家学习pandas的较为全面的用法, 让大家可以熟练的用pandas做数据分析.
一、生成pandas
| 生成pandas | 作用 |
|---|---|
| pd.Series() | 生成pandas,一维数组 |
| pd.DataFrame() | 生成pandas,二维的,有行列标签的 |
(1) pd.Series
import numpy as np
import pandas as pd
a = pd.Series([1, 3, 6, 'orange'])
print('pandas和字典有点像', a)
(2) pd.DataFrame
(a)以数组形式生成
# 生成6个日期行索引号
datas = pd.date_range('20190403', periods=6)
# 生成有6行4列行索引(index)和列索引(columns)的pandas
df = pd.DataFrame(np.random.random(size=(6, 4)), index=datas, columns=['a', 'b', 'c', 'd'])
print('生成有6行4列行索引(index)和列索引(columns)的pandas:\\n', df)

(b)以字典形式生成
# 以字典方式生成pandas,其中AB为列索引
df2 = pd.DataFrame('A': 1, 'B': 2., index=np.arange(2))
print('以字典方式生成pandas\\n', df2)

二、dataframe的基本属性
| pandas | 作用 |
|---|---|
| df.index | 行索引号 |
| df.columns | 列索引号 |
| df.values | pandas数值 |
| df.shape | 形状 |
| df.dtypes | 查看每一列的数据类型 |
| s.index.is_unique | 是否有重复索引,返回值为Bool值 |
三、索引值和修改dataframe
| pandas索引 | 作用 |
|---|---|
| df[‘a’]或df.a | 索引a列 |
| df.loc[:,“a”] | 对标签进行索引,返回’a’标签所在列 |
| df.iloc[:,0] | 对位置进行索引,返回第0列 |
| df[2:4] | 索引2、3行 |
| df.tail(3) | 返回后三行 |
| df.head(5) | 返回前5行 |
| df.ix | 标签和位置混合索引,不建议使用 |
| df.iat[1,1] | 位置索引,索引第1行第1列的值 |
| df[df>0] | 索引df>0的元素,小于0的返回NaN |
| df.insert(1,‘bar’,np.nan) | 在第0、1列之间插入一列nan,列标签为’bar’ |
| df.assign(Ratio=lambda x:x.a-x.b) | 增加新列一列标签为Ratio的,值为df.a-df.b |
| df.reindex(index=range(8),method=‘ffill’) | 重建行索引标签0-7,method='ffill’新增行的值我们用上一行的填充,method只对行有效 |
| df.reindex(columns=range(8),fill_value=0) | 重建列索引标签0-7,fill_value=0表示对于新增列的值设为0 |
| df.drop([‘A’,‘B’], axis=0,inplce=True) | 丢掉行A、B |
# 1、pandas索引
print('选中df的a列\\n', df['a'], df.loc[:, 'a'], df.iloc[:, 0], df[0])
print('选中df的第0行\\n', df.iloc[0], df.loc['2019-04-03'],df[0:1])
print('选df的135行,12列', df.iloc[[1, 3, 5], 1:3], df.ix[[1, 3, 5], ['a', 'b']])
print('索引df的a列中大于0.5对应的行', df[df['a'] > 0.5])
# 2、通过索引改变pandas的值
df.iloc[2, 2] = 'orange'
df.iat[2,2] = 'orange'
df.loc['2019-04-03', 'a'] = 'apple'
# 3、将df的b列大于0.3对应的行令为0
df[df.b > 0.3] = 0
# 4、将df的d列大于0.5对应的元素令为0
df.d[df.d > 0.5] = 0
# 5、增加一列e和f
df['e'] = 6
# 6、增加一行
s2 = pd.Series(np.arange(4), index=df.columns)
res = df3.append(s2, ignore_index=True)
四、运算(排序、统计、累加、判等)
| pandas运算 | 作用 |
|---|---|
| df.describe() | 描述个数、均值、方差、分位数 |
| df.T | 转置 |
| df.sort_index(axis=1,ascending=False) | 对列索引号排序,降序 |
| df.sort_values(by=‘d’) | 对d列的值的大小进行排序 |
| s.value_counts() | 查看每个数有多少个,s为Series类型 |
| s.rank() | 排名,最小值排第一名,依次往后 |
| df.mean() | 按列取平均值 |
| df.mean(axis=1) | 按行取平均值 |
| df.cumsum()或df.apply(np.cumsum) | 对每一列进行累加 |
| s.mode() | 产生次数最多的数字,s为Series类型 |
| (df1==df).all().all() | 判断df1和df的值是否完全相等 |
| df.apply(lambda x:x.max()-x.min(),axis=0) | 求每一列的max-min |
| s.isin([‘a’,‘c’]) | s的值是否在[‘a’,‘c’]里 |
五、处理丢失数据(如nan数据)
| pandas处理丢失数据 | 作用 |
|---|---|
| df.dropna(axis=1, how=‘any’) | 丢掉nan所在的列 |
| df.dropna()或 df.dropna(axis=0, how=‘any’) | 丢掉nan所在的行 |
| df.fillna(value=5) | 填充nan的数据为5 |
| df.isnull() | 判断是否有空数据,返回值为布尔型 |
| df3.isnull().any().any()或np.any(df.isnull()) == True) | 存在任一丢失数据,返回True |
注意: 1.how='any'存在任意一个nan就丢,how='all'该列全部为nan才丢
2.NaN值不参与计算
六、合并
| pandas合并数据 | 作用 |
|---|---|
| pd.concat([df1, df2], axis=0,ignore_index=True,join=‘inner’) | 上下合并,忽略原来的行索引,join='inner’表示只合并df1、df2的共有列;不写就表示 |
| pd.merge(left, right, on=‘key’) | 以列索引key为基准进行左右合并 |
| df3.append([df4,df5], ignore_index=True) | 将df4,df5合并到df3,忽略原来的行索引。 |
注意:在concat里面axis=0,上下合并;axis=1,左右合并,不写默认axis=0; concat既可以上下又可以左右合并, append只能上下合并, merge只能左右合并
1、concat和append
df4 = pd.DataFrame(np.ones((3, 4)), columns=['a', 'b', 'c', 'd'], index=[1, 2, 3])
df5 = pd.DataFrame(np.ones((3, 4))*2, columns=['b', 'c', 'd', 'e'], index=[2, 3, 4])
res1 = pd.concat([df4, df5],axis=0, ignore_index=True)
res2 = pd.concat([df4, df5], join='inner')
print("res1:上下合并,忽略原索引,缺失补Nan:\\n",res1, '\\n', "res2:上下合并,只合并共有列:\\n",res2, '\\n')
res3 = pd.concat([df4, df5], join='inner',axis=1)
print("res3:左右合并,忽略原索引,缺失补Nan:\\n",res3)
res4 = df4.append([df4,df5], ignore_index=True)
print("append方式上下合并:\\n",res4)
s2 = pd.Series(np.arange(4), index=df4.columns)
res5 = df4.append(s2, ignore_index=True)
print("append方式增加一行:\\n",res5)

2、merge合并,左右合并
# 只有一个key
left = pd.DataFrame('key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'])
right = pd.DataFrame('key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3'])
# 以key的columns为基准合并
res6 = pd.merge(left, right, on='key')
print(res6)
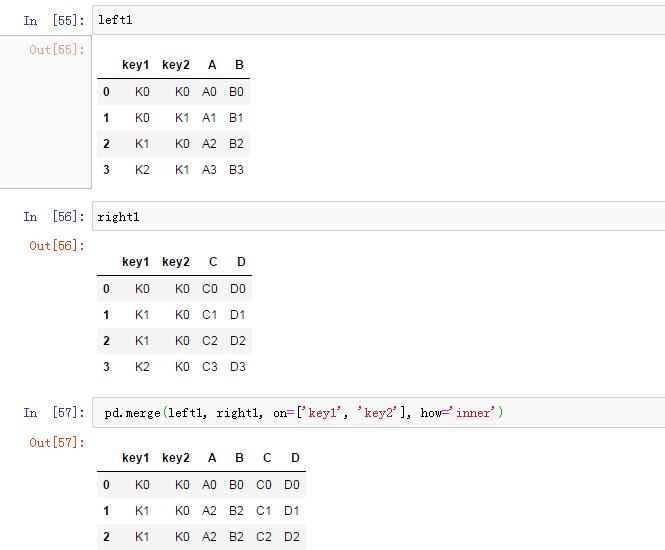
# 考虑有两个key
left1 = pd.DataFrame('key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'])
right1 = pd.DataFrame('key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3'])
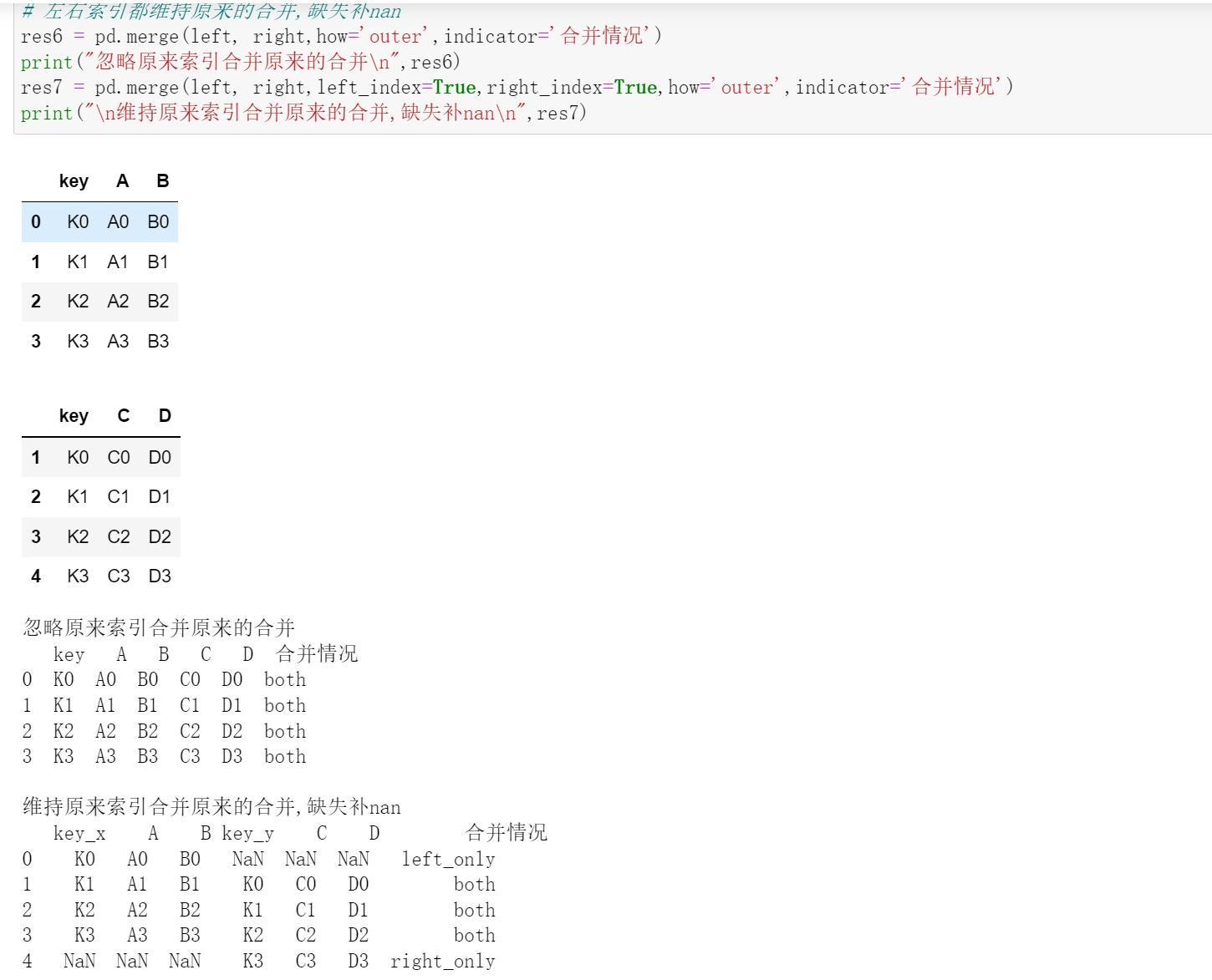
# how='inner'合并key1key2都相同的,how='outer'都合并,没有补nan
res7 = pd.merge(left1, right1, on=['key1', 'key2'], how='inner')
print(res7)
# 以key为基准合并,但考虑相同索引可能背后意义不同,故予以分别显示、
boys = pd.DataFrame('K': ['K0', 'K1', 'K2'],
'age': [1, 2, 3])
girls = pd.DataFrame('K': ['K0', 'K0', 'K3'],
'age': [4, 5, 6])
res9 = pd.merge(boys, girls, on='K', suffixes=['boy_age', 'girl_age'], how='inner')
print(res9)
运行结果:
只有一个key, pd.merge(left, right, on=‘key’)
2)
有2个key(key1,key2), pd.merge(left1, right1, on=[‘key1’, ‘key2’], how=‘inner’)
how='inner'合并key1key2都相同的,how='outer'都合并,没有补nan
按照行索引合并
补充:merge合并小技巧
比如特征一个是以小时为粒度的,如天气预报,一个以15min为粒度,我们需要将两个特征合并,就需要对天气做扩充,merge的小技巧就是提取二者时间的小时,做合并,这样天气数据就会自动填充为15min
left1 = pd.DataFrame('time':['2021-01-02 00:00:00', '2021-01-02 00:15:00'],
'time_hour': ['2021-01-02 00', '2021-01-02 00'],
'pelec': [2,2.5])
right1 = pd.DataFrame('time': ['2021-01-02 00:00:00'],
'time_hour': ['2021-01-02 00'],
'pelec': ['晴'])
res7 = pd.merge(left1, right1, on=['time_hour'], how='inner')
print(res7)

七、文件的存取
| pandas文件存取 | 作用 |
|---|---|
| pd.read_excel(‘文件路径’) | 读取excel文件 |
| pd.read_csv(‘文件路径’) | 读取csv文件 |
| pd.read_pickle(‘文件路径’) | 读取pickle文件到pandas |
| df.to_csv(‘文件路径’) | 将df写到csv文件 |
| data1.to_pickle(‘文件路径’) | 将df写到pickle |
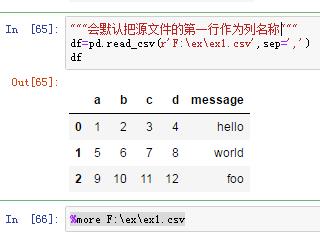
1)读取,
第一行作为列名称
2)原文件没有列名称,自己指定列名称
3)指定原文件中的某一列做行索引
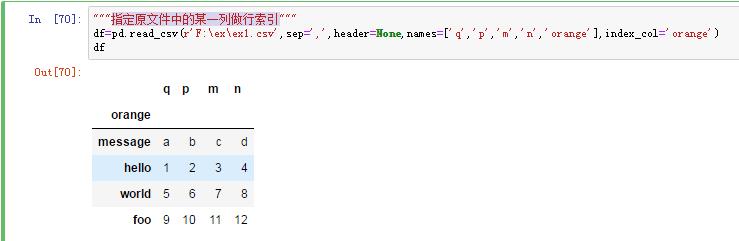
注意:修改index_col=['orange','m']可以生成多级行索引
4)若分割符不标准
有多个长度不等的空格分割,我们采用正则表达式
pa.read_t
6)保存文件:
index=False不写入行索引,header=None不写列标签,columns=['a','b']只写ab列,sep='|'以竖线分割。





八、时间日期:
8.1 生成时间序列
时间日期在Pandas里的作用:
- 分析金融股票交易数据
- 分析服务器日志
| pandas时间序列 | 作用 |
|---|---|
| pd.date_range(‘20191011’,periods=600,freq=‘s’) | 创建600个以秒为间隔的时间序列 |
| s.resample(‘2Min’,how=‘sum’) | 对s序列进行每2min采样求和,返回新的pandas序列 |
| pd.period_range(‘2000Q1’,‘2016Q1’,freq=‘Q’) | 以季度(3个月)为单位,生成的从2000q1到2016Q1的时间序列 |
| pd.Timestamp(‘20160301’)-pd.Timedelta('days=5) | 计算5天前的日期 |
1) pd.date_range 生成时间戳时间序列
pandas生成时间序列,可作为DataFrame或Series的index
2)pd.period创建时期序列,及时期序列的频率转换

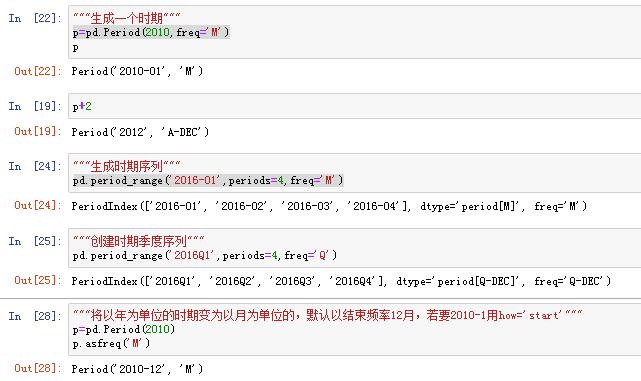
8.2 时间重采样
- 高频——>低频:降采样,例:5Min股票交易数据转为日交易数据
- 低频——>高频:升采样
- 其他重采样:每周三(W-WED)转换为每周五(W-FRI)
| 重采样 | 作用 |
|---|---|
| s.to_period() | 将时间戳时间序列转换为时期的时间序列 |
| pts.to_timestamp(how=‘end’) | 转为时间戳的时间序列 |
| ts.resample(‘5min’,how=‘sum’,label=‘right’) | 将分钟采样变为5min采样,若不加label=‘right’,则标签为采样开始时间 |
| ts.resample(‘5min’,how=‘ohlc’) | 返回列标签有——开盘价,最高价,最低价,收盘价 |
| df.resample(‘A-DEC’).sum() | 重采样,以年为单位, 'A-DEC’以年为单位,12月为一年的结束 |
| adf.resample(‘Q-DEC’).mean() | 重采样,以季度为单位 |
| ts.resample(‘D’,fill_method=‘ffill’,limit=3) | 以周为单位,转为以天为单位,向前插值,最多前插三个 |
| df=pd.read_csv(‘1.csv’,index_col=True,parse_dates=True) | 从文件中解析时间数据,parse_dates=True python会尽可能的解析时间日期 |
注意:降采样,一般要带上方法,如.sum,how='mean'等
升采样要带上插值方法
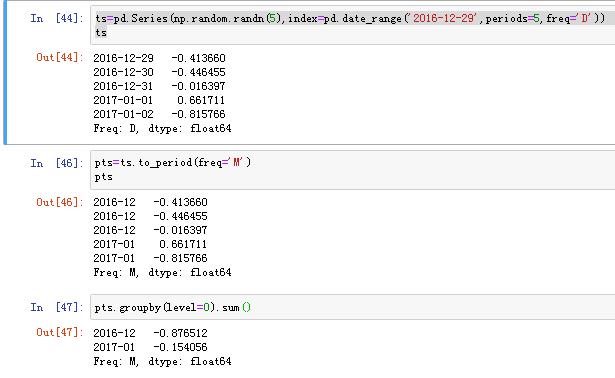
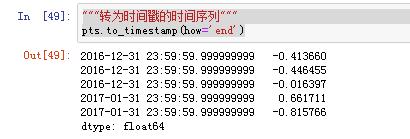
"""重采样"""
"""分钟股票交易数据"""
ts=pd.Series(np.random.randint(0,50,60),index=pd.date_range('2016-4-25 09:30',periods=60,freq='T'))
///降采样
///1)1天一采变为5天采样
ts.resample('5min',how='sum',label='right')
ts.resample('5min',how='ohlc')
///2)"""将天改为月份重采样"""
ts=pd.Series(np.random.randint(0,50,100),index=pd.date_range('2016-4-25',periods=100,freq='D'))
//方法1:lambda函数
ts.groupby(lambda x:x.month).sum()
//方法2:将时间戳转为时期
ts.groupby(ts.index.to_period('M')).sum()
"""升采样"""
///"""'W-FRI以周为单位,周五为一周的结束"""
ts=pd.Series(np.random.randint(0,50,2),index=pd.date_range('2016-4-2',periods=2,freq='W-FRI'))
///以周为单位,转为以天为单位,向前插值,最多前插三个
ts.resample('D',fill_method='ffill',limit=3)
"""其他重采样"""
///"""将每周五时间转为每周一"""
ts.resample('W-MON',fill_method='ffill')
九、groupby分组计算
| 分组 | 函数 |
|---|---|
| df.groupby(索引列表).sum() | 列表分组 |
| 支持迭代 | for 组名, 组 in df.groupby(索引列表): |
| 通过字典映射分组 | mapping = ‘a’:red, ‘b’:‘red’, ‘c’:blue, ‘d’:‘orange’, ‘e’:‘blue’,df.groupby(mapping, axis =1) |
| 通过函数分组 | df.groupby(len) |
| 多级索引通过索引级别分组 | df.groupby(level=, axis= ) |

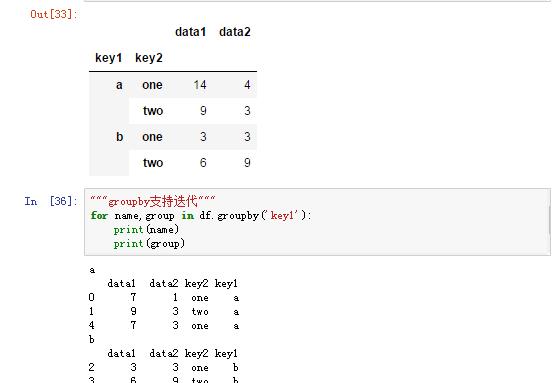
十、聚合函数
1)内置聚合函数
上图中的.mean()就是聚合函数,此外还有
df.groupby().describe()# 包含所有内置函数结果df.groupby().min()df.groupby().max()df.groupby().mean()df.groupby().sum()
2)自定义聚合函数

3)应用多个聚合函数
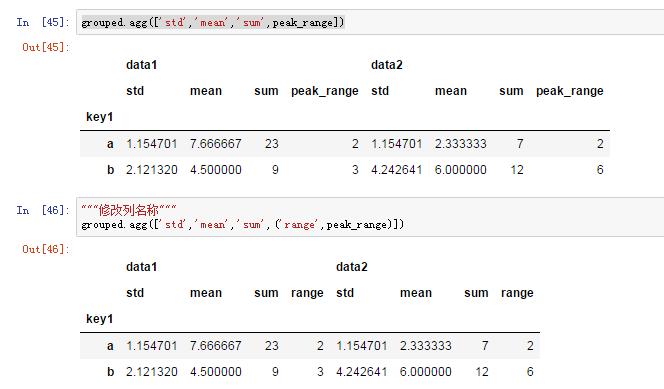
4)不同列应用不同的聚合函数
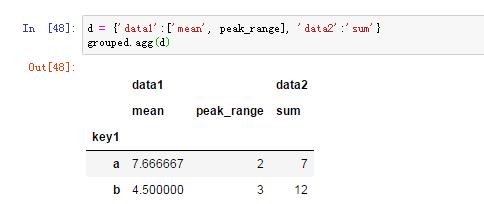
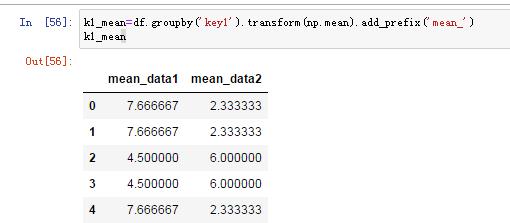
5)将分组转换为和原来的df一样的格式(行索引相同)
调用groupby().transform(聚合函数)
今天的内容就到这里啦,希望看到此文的小伙伴能有所收获,后续会继续更新数据分析的其他内容,关注我,咱们下期再见!!

以上是关于数据分析——pandas的主要内容,如果未能解决你的问题,请参考以下文章