spark使用之ALS版本对比
Posted 小李飞刀李寻欢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark使用之ALS版本对比相关的知识,希望对你有一定的参考价值。
hi各位大佬好,我是菜鸟小明哥,最近在搞spark的破事,别人一问只会pyspark有点low,因此有必要学习下java-spark,以ALS为例开展,毕竟也是推荐中常用的方法,这个有必要知道。
疑问:ALS似乎只能用于评分的进行矩阵分解,如果是点击(0或1)咋办,没有评分(得不到评分),能将0/1视为评分这样做么??
带着问题开始!!
For Recommendation in Deep learning QQ Group 277356808
For deep learning QQ Second Group 629530787
I'm here waiting for you
前置博文,java读取movielens数据,maven环境问题,java-spark数据预处理
spark-ALS有官方的例子,但是我这里实现不了(不能给用户推荐合适的item)下面的可以执行,但是不能打印这个变量。
Dataset<Row> userRecs = model.recommendForAllUsers(10);经过很久的调研,目前能够实现的是ML版本得到user factor 及item factor,这个就是embedding的表征吧(后面可以验证)。MLlib有另一个版本,因为环境版本支持,很容易实现。最终保存形式如下:
import org.apache.spark.mllib.recommendation.ALS;
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel;
import org.apache.spark.mllib.recommendation.Rating;

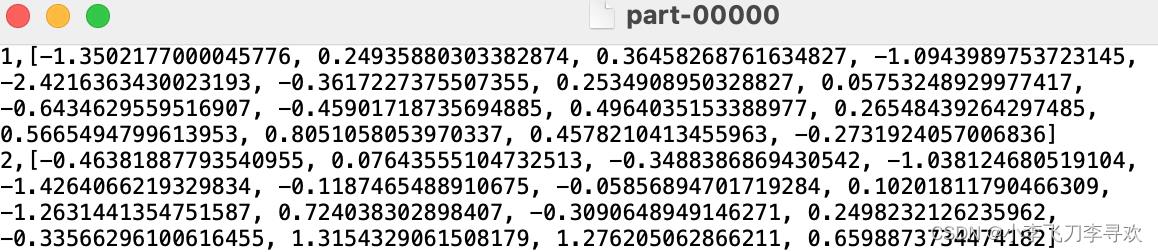
感觉无需编码就可以,前面是id,后面是double [] ,16维度。
MLlib的版本计算的很快,简直是瞬间计算完成。下面进行分割数据集(留一法),然后得到训练集和测试集,然后并用python-faiss计算出最终的效果。
如果没有下面的转换结果如下:解决方法参考博文
model.userFactors().toJavaRDD().saveAsTextFile(outDir+"/userFeatures");
//model.userFeatures().toJavaRDD().map(new FeaturesToString()).saveAsTextFile(
outputDir + "/userFeatures");
【10.16】现在两种方法的结果均已存储,那么现在读取为py,方便进行后续测试指标。
ALS1数据格式如下
mac 安装faiss没有问题,但引入faiss就是出错。
return _bootstrap._gcd_import(name[level:], package, level)
ModuleNotFoundError: No module named '_swigfaiss'
环境设置的问题,先在终端进入py的虚拟环境,
$ source /Users/。。/PycharmProjects/pythonProject/venv/bin/activateconda安装:conda install faiss-cpu -c
全部当成点击数据,没有按照评分进行区分正负样本,对比结果如下:指标见此博文
ALS1
[0.00073506 0.01175497 0.00660284 0.00270839 0.00184229]
ALS2
[0.00036465 0.01009934 0.00561241 0.00204855 0.00112642]两次结果相差不大
[0.00043596 0.01059603 0.00594256 0.00222487 0.00124072]
很显然ALS1效果较好。
但我感觉其中有bug,HR@50怎么可能这么低呢?这个无法和ytb做对比,因为使用ytb时只用了点击,而没有考虑其中的评分,而ALS考虑评分了。如果非要对齐,那么数据应该将大于3或者4的评分视为点击,小于此阈值的视为没有点击,然后再进行训练。不再展示,后续有机会做推荐再写。
愿我们终有重逢之时,而你还记得我们曾经讨论的话题
以上是关于spark使用之ALS版本对比的主要内容,如果未能解决你的问题,请参考以下文章