聊聊 Kafka:Kafka 如何保证一致性
Posted 老周聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Kafka:Kafka 如何保证一致性相关的知识,希望对你有一定的参考价值。
一、前言
在如今的分布式环境时代,任何一款中间件产品,大多都有一套机制去保证一致性的,Kafka 作为一个商业级消息中间件,消息一致性的重要性可想而知,那 Kafka 如何保证一致性的呢?本文从高水位更新机制、副本同步机制以及 Leader Epoch 几个方面去介绍 Kafka 是如何保证一致性的。
二、HW 和 LEO
要想 Kafka 保证一致性,我们必须先了解 HW(High Watermark)高水位和 LEO(Log End Offset)日志末端位移,看下面这张图你就清晰了:

高水位的作用:
- 定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
- 帮助 Kafka 完成副本同步
这里我们不讨论 Kafka 事务,因为事务机制会影响消费者所能看到的消息的范围,它不只是简单依赖高水位来判断。它依靠一个名为 LSO(Log Stable Offset)的位移值来判断事务型消费者的可见性。
日志末端位移的作用:
- 副本写入下一条消息的位移值
- 数字 15 所在的方框是虚线,这就说明,这个副本当前只有 15 条消息,位移值是从 0 到 14,下一条新消息的位移是 15。
- 介于高水位和 LEO 之间的消息就属于未提交消息。这也反映出一个事实,那就是:同一个副本对象,其高水位值不会大于 LEO 值。
高水位和 LEO 是副本对象的两个重要属性。Kafka 所有副本都有对应的高水位和 LEO 值,而不仅仅是 Leader 副本。只不过 Leader 副本比较特殊,Kafka 使用 Leader 副本的高水位来定义所在分区的高水位。换句话说,分区的高水位就是其 Leader 副本的高水位。
三、HW 和 LEO 的更新机制
现在,我们知道了每个副本对象都保存了一组高水位值和 LEO 值,但实际上,在 Leader 副本所在的 Broker 上,还保存了其他 Follower 副本的 LEO 值,请看下图:

从图中可以看出,Broker 0 上保存了某分区的 Leader 副本和所有 Follower 副本的 LEO 值,而 Broker 1 上仅仅保存了该分区的某个 Follower 副本。Kafka 把 Broker 0 上保存的这些 Follower 副本又称为远程副本(Remote Replica)。Kafka 副本机制在运行过程中,会更新 Broker 1 上 Follower 副本的高水位和 LEO 值,同时也会更新 Broker 0 上 Leader 副本的高水位和 LEO 以及所有远程副本的 LEO,但它不会更新远程副本的高水位值,也就是我在图中标记为灰色的部分。
这里你可能就困惑了?
- 为啥 Leader 副本所在的 Broker 上,还保存了其他 Follower 副本的 LEO 值?
- 为啥 Leader 副本所在的 Broker 上不会更新 Follower 副本 HW?
别着急,老周带你看下源码:
在 kafka.cluster.Partition#makeLeader 中:


Leader 副本所在的 Broker 上只有重置更新远程副本的 LEO,并没有远程副本的 HW。
这里你又可能会问了?
- 为什么要在 Broker 0 上保存这些远程副本呢?
- Broker 0 不会更新远程副本 HW,那远程副本的 HW 的更新机制又是怎样的呢?
Broker 0 上保存这些远程副本的主要作用是,帮助 Leader 副本确定其高水位,也就是分区高水位。
第二个问题我们直接来看下 HW 和 LEO 被更新的时机:
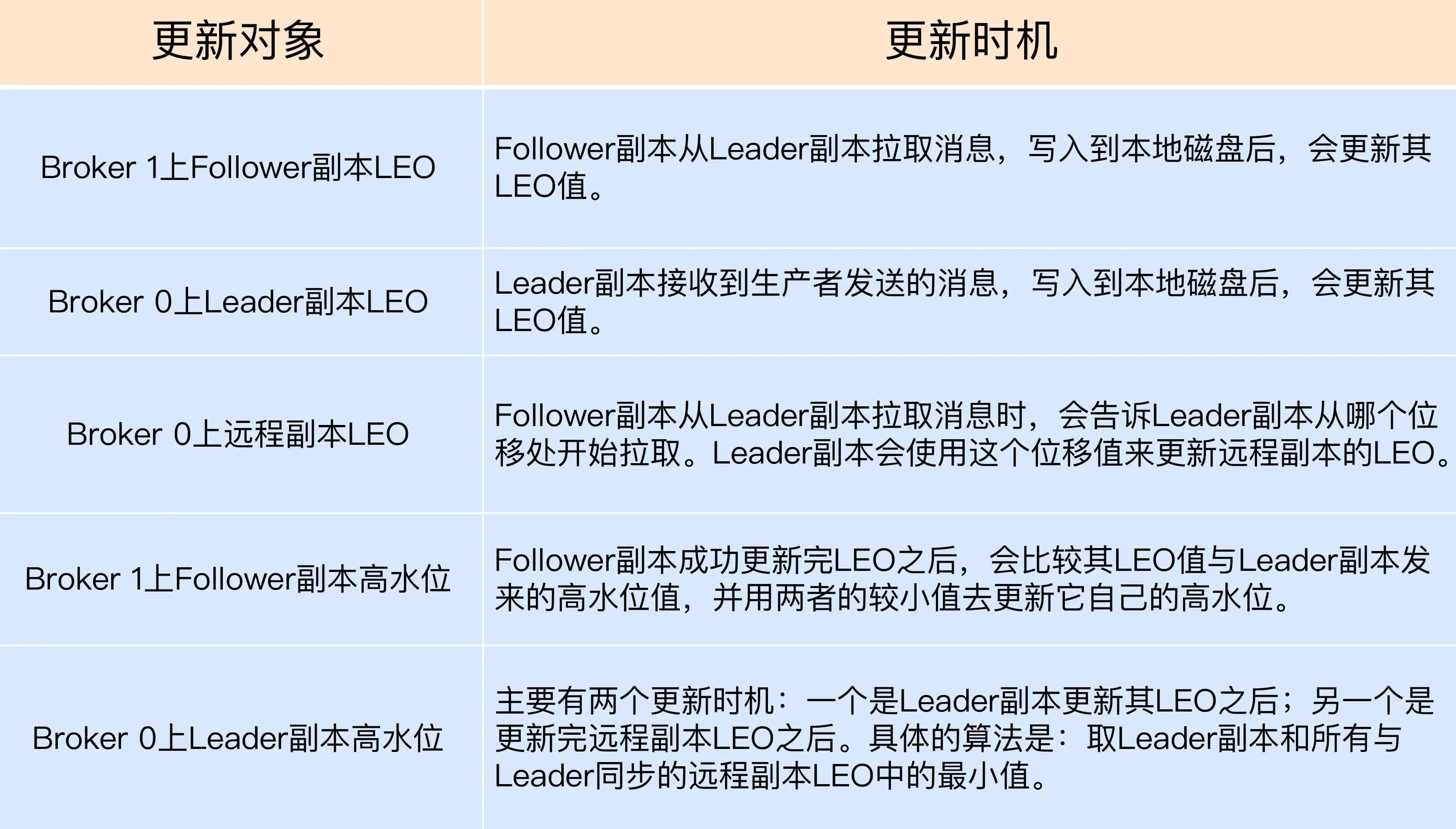
3.1 Leader 副本
处理生产者请求的逻辑如下:
- 写入消息到本地磁盘
- 更新分区高水位值
- 获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值(LEO-1,LEO-2,……,LEO-n)
- 获取 Leader 副本高水位值:currentHW
- 更新 currentHW = maxcurrentHW, min(LEO-1, LEO-2, ……,LEO-n)
处理 Follower 副本拉取消息的逻辑如下:
- 读取磁盘(或页缓存)中的消息数据
- 使用 Follower 副本发送请求中的位移值更新远程副本 LEO 值
- 更新分区高水位值(具体步骤与处理生产者请求的步骤相同)
3.2 Follower 副本
从 Leader 拉取消息的处理逻辑如下:
- 写入消息到本地磁盘
- 更新 LEO 值
- 更新高水位值
- 获取 Leader 发送的高水位值:currentHW
- 获取步骤 2 中更新过的 LEO 值:currentLEO
- 更新高水位为 min(currentHW, currentLEO)
四、副本同步机制
搞清楚了上面 HW 和 LEO 的更新机制后,我们举一个单分区且有两个副本的主题来演示下 Kafka 副本同步的全流程。
当生产者发送一条消息时,Leader 和 Follower 副本对应的 HW 和 LEO 是怎么被更新的呢?
首先是初始状态。下面这张图中的 remote LEO 就是刚才的远程副本的 LEO 值。在初始状态时,所有值都是 0。

当生产者给主题分区发送一条消息后,状态变更为:

此时,Leader 副本成功将消息写入了本地磁盘,故 LEO 值被更新为 1。
Follower 再次尝试从 Leader 拉取消息。和之前不同的是,这次有消息可以拉取了,因此状态进一步变更为:

这时,Follower 副本也成功地更新 LEO 为 1。此时,Leader 和 Follower 副本的 LEO 都是 1,但各自的高水位依然是 0,还没有被更新。它们需要在下一轮的拉取中被更新,如下图所示:
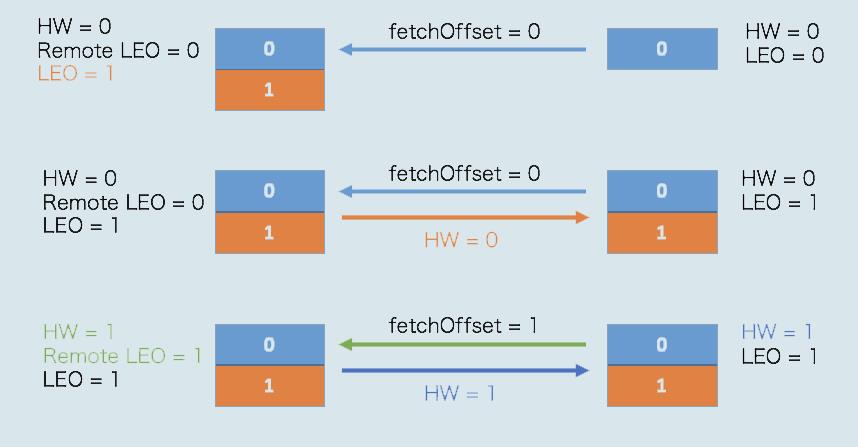
在新一轮的拉取请求中,由于位移值是 0 的消息已经拉取成功,因此 Follower 副本这次请求拉取的是位移值 =1 的消息。Leader 副本接收到此请求后,更新远程副本 LEO 为 1,然后更新 Leader 高水位为 1。做完这些之后,它会将当前已更新过的高水位值 1 发送给 Follower 副本。Follower 副本接收到以后,也将自己的高水位值更新成 1。至此,一次完整的消息同步周期就结束了。事实上,Kafka 就是利用这样的机制,实现了 Leader 和 Follower 副本之间的同步。
五、Leader Epoch 机制
上面的副本同步机制似乎很完美,我们不妨来思考下这种场景:
从刚才的分析中,我们知道,Follower 副本的高水位更新需要一轮额外的拉取请求才能实现。如果把上面那个例子扩展到多个 Follower 副本,情况可能更糟,也许需要多轮拉取请求。也就是说,Leader 副本高水位更新和 Follower 副本高水位更新在时间上是存在错配的。这种错配是很多“数据丢失”或“数据不一致”问题的根源。基于此,社区在 0.11 版本正式引入了 Leader Epoch 概念,来规避因高水位更新错配导致的各种不一致问题。
所谓 Leader Epoch,我们大致可以认为是 Leader 版本。它由两部分数据组成。
Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
我举个例子来说明一下 Leader Epoch。假设现在有两个 Leader Epoch<0, 0> 和 <1, 120>,那么,第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 120 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 120。
Kafka Broker 会在内存中为每个分区都缓存 Leader Epoch 数据,同时它还会定期地将这些信息持久化到一个 checkpoint 文件中。当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存。如果该 Leader 是首次写入消息,那么 Broker 会向缓存中增加一个 Leader Epoch 条目,否则就不做更新。这样,每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,以避免数据丢失和不一致的情况。
源码在 org.apache.kafka.raft.LeaderState 中:

Kafka Broker 会在内存中为每个分区都缓存 Leader Epoch 数据:

同时它还会定期地将这些信息持久化到一个 checkpoint 文件中:
org.apache.kafka.common.message.LeaderAndIsrRequestData.LeaderAndIsrPartitionState#write

接下来,我们来看一个实际的例子,它展示的是 Leader Epoch 是如何防止数据丢失的。请先看下图:

开始时,副本 A 和副本 B 都处于正常状态,A 是 Leader 副本。某个使用了默认 acks 设置的生产者程序向 A 发送了两条消息,A 全部写入成功,此时 Kafka 会通知生产者说两条消息全部发送成功。
现在我们假设 Leader 和 Follower 都写入了这两条消息,而且 Leader 副本的高水位也已经更新了,但 Follower 副本高水位还未更新——这是可能出现的。还记得吧,Follower 端高水位的更新与 Leader 端有时间错配。倘若此时副本 B 所在的 Broker 宕机,当它重启回来后,副本 B 会执行日志截断操作,将 LEO 值调整为之前的高水位值,也就是 1。这就是说,位移值为 1 的那条消息被副本 B 从磁盘中删除,此时副本 B 的底层磁盘文件中只保存有 1 条消息,即位移值为 0 的那条消息。
当执行完截断操作后,副本 B 开始从 A 拉取消息,执行正常的消息同步。如果就在这个节骨眼上,副本 A 所在的 Broker 宕机了,那么 Kafka 就别无选择,只能让副本 B 成为新的 Leader,此时,当 A 回来后,需要执行相同的日志截断操作,即将高水位调整为与 B 相同的值,也就是 1。这样操作之后,位移值为 1 的那条消息就从这两个副本中被永远地抹掉了。这就是这张图要展示的数据丢失场景。
严格来说,这个场景发生的前提是 Broker 端参数 min.insync.replicas 设置为 1。此时一旦消息被写入到 Leader 副本的磁盘,就会被认为是“已提交状态”,但现有的时间错配问题导致 Follower 端的高水位更新是有滞后的。如果在这个短暂的滞后时间窗口内,接连发生 Broker 宕机,那么这类数据的丢失就是不可避免的。
现在,我们来看下如何利用 Leader Epoch 机制来规避这种数据丢失。请看下图:

场景和之前大致是类似的,只不过引用 Leader Epoch 机制后,Follower 副本 B 重启回来后,需要向 A 发送一个特殊的请求去获取 Leader 的 LEO 值。在这个例子中,该值为 2。当获知到 Leader LEO=2 后,B 发现该 LEO 值不比它自己的 LEO 值小,而且缓存中也没有保存任何起始位移值 > 2 的 Epoch 条目,因此 B 无需执行任何日志截断操作。这是对高水位机制的一个明显改进,即副本是否执行日志截断不再依赖于高水位进行判断。
现在,副本 A 宕机了,B 成为 Leader。同样地,当 A 重启回来后,执行与 B 相同的逻辑判断,发现也不用执行日志截断,至此位移值为 1 的那条消息在两个副本中均得到保留。后面当生产者程序向 B 写入新消息时,副本 B 所在的 Broker 缓存中,会生成新的 Leader Epoch 条目:[Epoch=1, Offset=2]。之后,副本 B 会使用这个条目帮助判断后续是否执行日志截断操作。这样,通过 Leader Epoch 机制,Kafka 完美地规避了这种数据丢失场景。
以上是关于聊聊 Kafka:Kafka 如何保证一致性的主要内容,如果未能解决你的问题,请参考以下文章