JVM C1 编译优化:合并相同的表达式-Global Value Numbering 之实现
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM C1 编译优化:合并相同的表达式-Global Value Numbering 之实现相关的知识,希望对你有一定的参考价值。
1. 原因
为了合并相同的运算,避免重复计算,通常在编译过程中,编译器会尝试合并相同的计算。
C1在初始的时候内部会构建图结构的HIR,它由基本块BB构成一个控制流图,每个基本块里面是SSA形式的指令。
单个BB块中通过ValueNumbering 来实现,多个BB块里实现的合并叫做Global Value Numbering ,但其算法的本质是一致的。
2. 值编号 Value Numbering
值编号(Value numbering):是指为每个SSA的instruction计算一个Hash值,然后遍历instruction寻找相同的instruction进行合并优化。而Global Value Numbering就是查找多个BB块中合并相同的值编号的instruction,基于C1如何生成的HIR的BB块在这篇博客里就不介绍了。C1 优化器会做一次BB块内部的Value Numbering的优化,然后在做一次跨BB块的Global Value Numbering的优化。
2.1 SSA的Instruction
首先我们先给一下BB块以及SSA的表达式Instruction的例子,能更直观的理解:
B0 (SV) [0, 14] -> B1 sux: B1 pred: B5
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 1 0 i8 a5._12 (I) t
4 0 i9 8
6 0 i10 i8 + i9
9 0 i11 18
11 0 i12 i6 + i11
. 14 0 13 goto B1我们可以看到BB块的编号,以及前驱以及后继BB块,同时执行一个如下语句:
int adder = c.t+8;需要3句Instructions,三元地址表达式
__bci__use__tid____instr____________________________________
. 1 0 i8 a5._12 (I) t
4 0 i9 8
6 0 i10 i8 + i92.2 计算Hash值
如何计算i10的Hash呢?i10是一个ArithmeticOp
LEAF(ArithmeticOp, Op2)
public:
// creation
ArithmeticOp(Bytecodes::Code op, Value x, Value y, bool is_strictfp, ValueStack* state_before)
: Op2(x->type()->meet(y->type()), op, x, y, state_before)
set_flag(IsStrictfpFlag, is_strictfp);
if (can_trap()) pin();
// accessors
bool is_strictfp() const return check_flag(IsStrictfpFlag);
// generic
virtual bool is_commutative() const;
virtual bool can_trap() const;
HASHING3(Op2, true, op(), x()->subst(), y()->subst())
;可以看到主要是计算value x的subst和 value y 的subst, 也就是这里给的i8, i9, 什么是subst ?就是指向的值,比如i8里的a5.12 i9里的8
i10的hash的值就是计算i8指向的a5.12以及i9的常量8
#define HASH1(x1 ) ((intx)(x1))
#define HASH2(x1, x2 ) ((HASH1(x1 ) << 7) ^ HASH1(x2))
#define HASH3(x1, x2, x3 ) ((HASH2(x1, x2 ) << 7) ^ HASH1(x3))
#define HASH4(x1, x2, x3, x4) ((HASH3(x1, x2, x3) << 7) ^ HASH1(x4))2.3 ValueMapArray
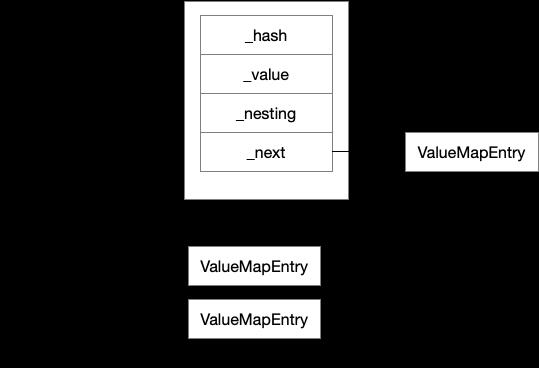
Hash值的计算并不具备唯一性,Hash相同无法保证表达式的一只,Hash的算法只是为了更快速的查找到相同的Hash值的Instr,在JVM里构建了ValueMapEntry 来保存一个Instr的 Hash ,以及value,同时也保存了指向下一个entry的指针。
JVM同时构建了ValueMapArray的数组,通过Hash%size找到数组里对应的首个ValueMapEntry,通过遍历ValueMapEntry的链表结构,匹配相同的Hash值,然后在进行Value的比较,我们以前面的ArithmeticOp例子为例:
virtual bool is_equal(Value v) const \\
if (!(enabled) ) return false; \\
class_name* _v = v->as_##class_name(); \\
if (_v == NULL ) return false; \\
if (f1 != _v->f1) return false; \\
if (f2 != _v->f2) return false; \\
if (f3 != _v->f3) return false; \\
return true; \\
比较都是ArithmeticOp里的value x的subst和 value y 的subst是否完全相同。
如果完全相同,将会把当前的Instr里的subst替换成相同的Instr。在不同的情况下,插入当前的Instr在ValueMapArray中。
当然并不是所有的Instr都需要进行Value Number编号,比如:if, goto, return 这些的Hash值都会被计算为0,0的Hash值是不会被保存到ValueMapArray中。
2.4 CFG 控制流分析
Global Value Numbering 作为一个全局(函数)分析,和Value Numbering的区别主要在跨BB块的分析,基于控制流分析,在不同的BB块的流转。先来看一段代码:
int adder = c.t+8;
while (num<100)
num = c.t+8;
if(num>10)
c.t=10;
return num+c.t+8;把这段代码转为CFG
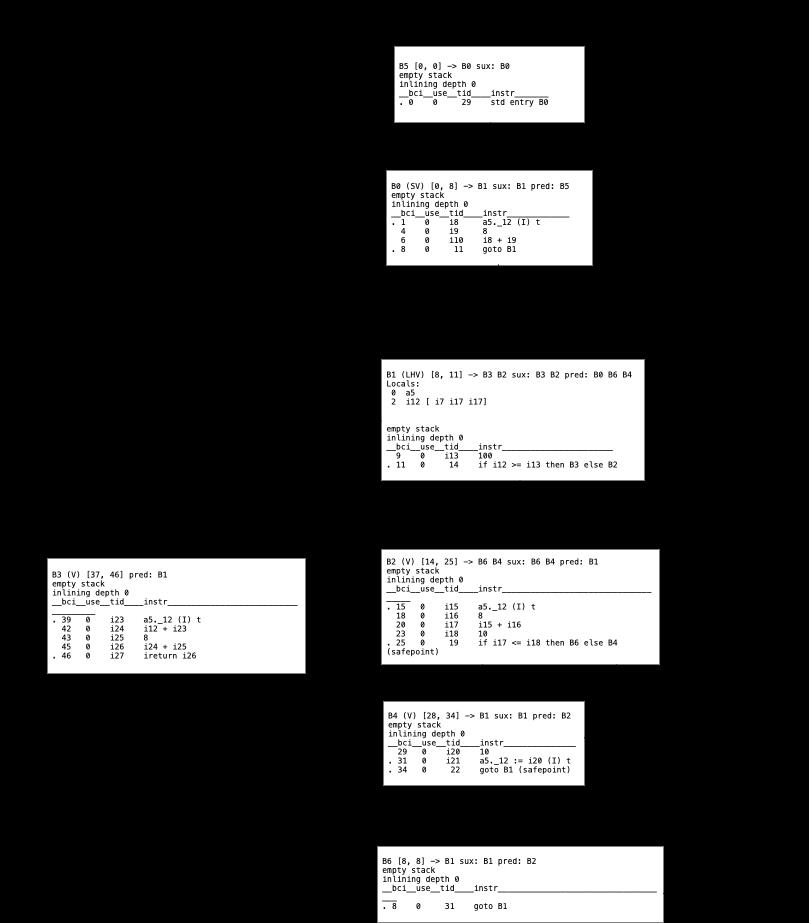
我们需要对每一个参数进行数据流分析,从而找到相同的表达式。在我们的例子里:我们不能把第一行的c.t+8 和第3行的num=c.t+8进行合并成 num=adder,主要原因是因为在5行里c.t 从新赋值了,这是我们对语意的理解。
编译优化对静态分析是要求准确,需要进行May Analyze,遍历所有存在的路径,但我们不会对一条分支进行判断以确定是否会真实的存在该条路径,例如第5行if(num<10)这条分支的num进行值域求解分而获取判断结果是否有可能走到该分支,而是直接使用在CFG存在这条路径就可以了,在某些优化后可能存在块合并的情况下,这也是合并后在进行GVN分析。
2.5 数据流分析的transfor function
在数据流分析中,通常会提到transfor function,常见的Out[B]= gen U(In - Kill)
2.5.1 Kill 场景
什么是Kill?在做了某些操作后,比如改变某个变量的值,我们需要让关于这个变量的前后表达式无法合并,这样就需要Kill这个变量。
我们以2.4的代码进行举例,因为num= c.t + 8 ,也就是c.t+8 和int addr=c.t+8 是一样的表达式,我们应该考虑合并。但是在第5行里c.t=10,进行了c.t 的赋值,这是很明显不能合并表达式的。
这里代表了一种场景,当一个字段被storeField过,就需要Kill,而 Kill的逻辑如下
a. 将该字段c.t标示成被kill状态
b. 尝试去移除和c.t相关的ValueMapEntry
如何表示该字段被kill,这里和常见的数据流分析一样,使用bitMap的每一个bit位表示每一个参数:
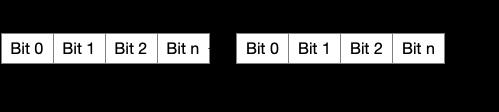
我们会发现SSA IR有个天然的好处,直接使用参数的下标id就可以了。如果没有用SSA IR表示,需要对每一个表达式进行行编号。
为何要从ValueMapEntryArray里移除和c.t相关的ValueMapEntry?毕竟已经在BitMap里表示了这个值被kill, 这个应该是从效率来考虑。要减少ValueMapEntryArray里的值,毕竟当Hash值相同的情况下,还是有需要链表访问里面的值,在这里还加了一个额外的逻辑,只会删除在同一Nest的ValueMapEntry, 可以简单的认为同一个BB块在同一层Nest。
有的人可能会很奇怪既然删除了ValueMapEntry,何必还要在BitMap里依然要标示,其原因就是因为在进行数据流分析的时候流的走向很重要,有可能存在删除了ValueMapEntry后有可能后面的BB块又访问了这个Field,为了避免复杂的分析,最安全的就是这时候是不在添加。
我们可以罗列一下哪些场景是需要被kill的:
1. Store field 2. Store Array 3. Monitor, 4. 操作unsafe 5.Intrinsic 6.Load field
大家可能会有点奇怪为何LoadField 是需要kill的呢?其实场景主要涉及volatile的语意,以及还有获取静态的字段的时候类有可能没有初始化成功
2.5.2 流分析
JVM C1 的HIR是双向链表,如下图:

在B2块里前向块是B6,B4, 后向块B1 ,在数据流分析中通常采用前向分析或者后向分析,在GVN的完整分析过程中,分析BB块中需要边分析边进行相同表达式合并。我们如果简单的考虑前向分析,后续的BB块中可能存在修改的场景并影响前面的BB块,这样的合并会存在问题,这种场景比较常见于循环。Natural loops 自然循环
- 在正常情况我们正向分析,依次对当前的block进行优化
- 当碰到循环头的时候,我们需要使用后向分析分析完完整的循环后,然后在进行当前的block优化
为何要分析完整的循环,也就是前面提到的后续的BB块可能存在修改的场景,我们需要遍历完所有的循环去执行Kill 的transfor function。
为何又要后向分析?我们来看这种场景:

红色的这个点,如果前向分析你会发现红色的这个点如果前向分析, 会把非循环的绿色的点加入到分析的点中。如何避免这样的问题发生,我们需要把绿色的点继续前向分析,以确定能回到蓝色的点。如果绿色的点链路很长,这会大大导致时间变长。同时我需要遍历所有的节点的每条路径以确保是在环里的。
使用后向分析:
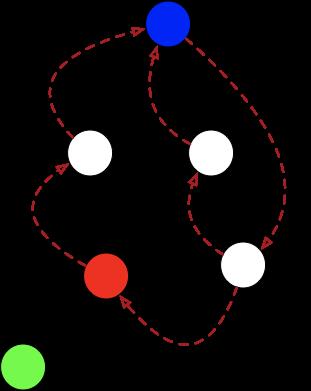
我们会发现绿色的点是不会在加到循环的分析过程中。在循环过程中使用后向分析,能很轻易的把非环的节点排除掉,同时会在碰到分析的环的节点超过ValueMapMaxLoopSize默认是8的时候不在分析循环,以避免分析较大的循环而耗费过多的时间。
分析循环只是为了提高精度,主要是对field 以及数组的修改, 只是kill所对应的值
void do_StoreField (StoreField* x)
if (x->is_init_point() || // putstatic is an initialization point so treat it as a wide kill
// This is actually too strict and the JMM doesn't require
// this in all cases (e.g. load a; volatile store b; load a)
// but possible future optimizations might require this.
x->field()->is_volatile())
kill_memory();
else
kill_field(x->field(), x->needs_patching());
void do_StoreIndexed (StoreIndexed* x) kill_array(x->type()); 其它的部分场景下(如下)及避免复杂循环分析下,会进行最大颗粒度的kill_memory
void do_MonitorEnter (MonitorEnter* x) kill_memory();
void do_MonitorExit (MonitorExit* x) kill_memory();
void do_Invoke (Invoke* x) kill_memory();
void do_UnsafePutRaw (UnsafePutRaw* x) kill_memory();
void do_UnsafePutObject(UnsafePutObject* x) kill_memory();
void do_UnsafeGetAndSetObject(UnsafeGetAndSetObject* x) kill_memory();
void do_Intrinsic (Intrinsic* x) if (!x->preserves_state()) kill_memory(); 大颗粒度的Kill_Memory ,只要是load field, load array 就直接kill,也就是前面的逻辑:删除ValueMapEntry,设置BitMap的bit位
#define MUST_KILL_MEMORY(must_kill, entry, value) \\
bool must_kill = value->as_LoadField() != NULL || value->as_LoadIndexed() != NULL;2.5.3 替换相同的表达式
在遍历BB块的时候,如果发现该表达式的值与前面的值相同的时候,就使用前序BB的值来替代现在的值。
. 27 0 i18 a4._12 (I) t
30 0 i19 i11 + i18
31 0 i20 8
33 0 i21 i19 + i20
. 34 0 i22 ireturn i21将被替换成
30 1 i19 i11 + i7
33 1 i21 i19 + i8
. 34 0 i22 ireturn i21用i7替换成i18, i8代替i20
以上是关于JVM C1 编译优化:合并相同的表达式-Global Value Numbering 之实现的主要内容,如果未能解决你的问题,请参考以下文章