kafka java(api)
Posted FreeFly辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka java(api)相关的知识,希望对你有一定的参考价值。
前提
在看javaapi演示前你需要了解一些kafka的概念:1: 至少要会启动 kafka,知道默认端口号,可参看此博客链接: https://blog.csdn.net/weixin_46415189/article/details/119749267
kafka依赖zookeeper,所以,在此之前你最好先了解一下zookeeper,至少会启动 kafka启动时server.properties默认zookeeper地址配置为:

2: kafka只有主题,通过主题发送和订阅消息
3: kafka同一主题同一消息会被所有订阅者(不同组)同时收到,如果消费者指定的组 id(用户自定义的字符串id)一致,那么同一主题下的一条消息只会被同组中的一个客户端收到
4: 默认创建的主题只会创建一个分区,可在启动时指定的server.properties文件中更改

5: 同一组的用户会被kafka自动分配订阅不同的分区(注意是同一组),所以一旦消费者数量大于分区数,你就会发现一个组中总有消费者永远收不到消息(除非同组有其它消费者掉线了,多出来的消费者才可能被重新分配,这里的分配由kafka默认实现)
6: 一旦指定了消费者订阅某个分区,即使处于同一组的俩个消费者也会同时收到消息(因此我猜测 分区是会发送给所有订阅者,只是因为在分配阶段,kafka不会把同一组用户分配到同一分区,用此实现同一主题的某条消息不会被同组用户同时收到)
kafka的java客户端api
代码有注释,不懂的地方可留言一起探讨,错误的地方还请指出
以下代码中用到了 kafka的部分配置,如果想了解全部配置,可参考以下链接:
https://kafka.apache.org/documentation/#producerconfigs
maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
生产者
public class MyProducer
public static void main(String[] args)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
/**
* ack是判别请求是否为完整的条件(就是是判断是不是成功发送了)。
* 我们指定了“all”将会阻塞消息,这种设置性能最低,但是是最可靠的。
*/
props.put("acks", "all");
/**
* retries,如果请求失败,生产者会自动重试,
* 我们指定是0次,如果启用重试,则会有重复消息的可能性。
*/
props.put("retries", 0);
/**
* producer(生产者)缓存每个分区未发送的消息。缓存的大小是通过 batch.size 配置指定的。
* 值较大的话将会产生更大的批。并需要更多的内存(因为每个“活跃”的分区都有1个缓冲区)。
*/
props.put("batch.size", 16384);
/**
* 默认缓冲可立即发送,即便缓冲空间还没有满,
* 但是,如果你想减少请求的数量,可以设置linger.ms大于0。
* 这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。
* 例如上面的代码段,可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,
* 如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。
* 需要注意的是,在高负载下,相近的时间一般也会组成批,即使是 linger.ms=0。
* 在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
*/
props.put("linger.ms", 1);
/**
* 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。
* 当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定,之后它将抛出一个TimeoutException。
*/
props.put("buffer.memory", 33554432);
/**
* 最后就是消息的序列化方式,没什么好介绍的
*/
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer(props);
for(int i = 0; i < 10; i++)
/**
*new ProducerRecord既是创建一个生产者,主题名随便起,不存在时,会自动创建
*send()方法是异步的,添加消息到缓冲区等待发送,并立即返回。生产者将单个的消息批量在一起发送来提高效率
*partition :主题下的分区编号,参数类型类Integer,可传null,传null时默认发送到kafka的默认主题分区 0 */
//发送到 1 分区,
//producer.send(new ProducerRecord<String, String>("my-topic",1,"partition1",Integer.toString(i)));
//不指定分区
producer.send(new ProducerRecord<String, String>("my-topic","partition0",Integer.toString(i)));
//不指定key和分区,这里的key对kafka来说没什么实际意义,由你自己决定怎么用或不用
//producer.send(new ProducerRecord<String, String>("my-topic",Integer.toString(i)));
/**
* 最后如果不关闭,将可能导致最后一次要发送的数据丢失
* (类似与flush,将缓冲区的数据发送出去,send只是将消息加入缓冲区,
* 缓冲区满时会自动发送出去,但最后一次缓冲区的消息不一定是满的,
* 所以需要close一下进行发送)
*/
producer.close();
消费者
public class AutoConsumer
public static void main(String[] args)
Properties props = new Properties();
//kafka服务器地址,这个应该没啥好解释的
props.setProperty("bootstrap.servers", "localhost:9092");
//group.id,可随意指定,多个消费者根据此值确定是否为同一组
props.setProperty("group.id", "auto-consumer1");
//设置enable.auto.commit,偏移量由auto.commit.interval.ms控制自动提交的频率。
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
//序列化的东西,也没啥好说的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//根据配置创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅主题,不指定分区,由kafka自动分配
consumer.subscribe(Arrays.asList("my-topic"));
/**
* 如果想指定订阅主题,用以下方式
* 参数 主题名 ,分区号 (指定分区时前提是 确认你的主题有该分区)
* consumer.assign(Arrays.asList(new TopicPartition("my-topic",1)));
*/
while (true)
//poll 一次,就接受一次消息,返回的对象 实现了Iterable接口,类似集合;
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("partition = %d offset = %d, key = %s, value = %s%n",record.partition(),record.offset(), record.key(), record.value());
/**
* broker(broker就是kafka服务器,存储数据的节点)通过心跳机器自动检测一个组中失败的进程(即消费者)。
* 消费者会自动ping集群,告诉进群它还活着。只要消费者能够做到这一点,它就被认为是活着的,
* 并保留分配给它分区的权利,如果它停止心跳的时间超过session.timeout.ms,那么就会认为是故障的。
* 它的分区将被分配到别的进程(这里的进程可以看作就是同组的其它消费者)。
*/
原则上,只要你正常启动了kafka,添加了maven依赖,上面的程序是可以直接运行的
效果演示
一个生产者,多个不同组消费者,不指定分区
生产者代码:

效果图:
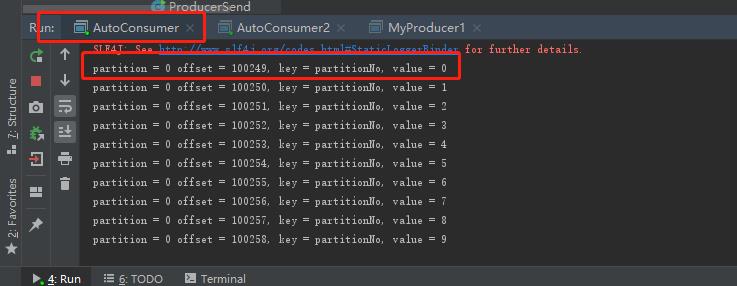
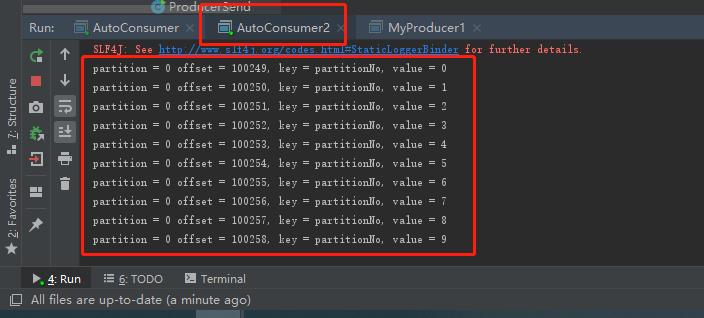
可已看出,俩个不同组的消费者消费了同样的消息(分区一样,偏移量一样就说明是同一条消息)
注意,我这里修改了kafka配置文件 server.properties文件的创建分区默认数,创建了俩个分区,但生产者未指定发往哪个分区,所以默认就发到了0分区,可通过zookeeper客户端查看分区数,如下:

一个生产者(其实几个都没关系,重要的是主题),俩个同组的消费者(不指定分区)

生产者和上面一样(不重要),发送到指定分区即可.先运行俩个消费者,在运行生产者,效果如下:

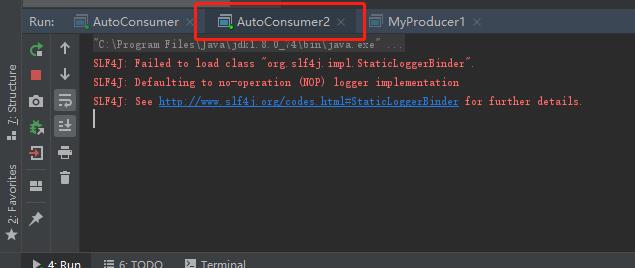
可以看到同一主题下的同组消费者只有一个收到了消息,这也就证实了开头说的,未指定分区时,kafka默认不会将同一组的消费者分配到同一分区, 生产者默认只发到了 0 分区,而俩个消费者被分配到了不同分区,因此只有监听了 0 分区的那个消费者才能收到消息
最后,同一主题,俩个同组消费者,指定订阅的分区一样(此时kafka的默认分配将失效)
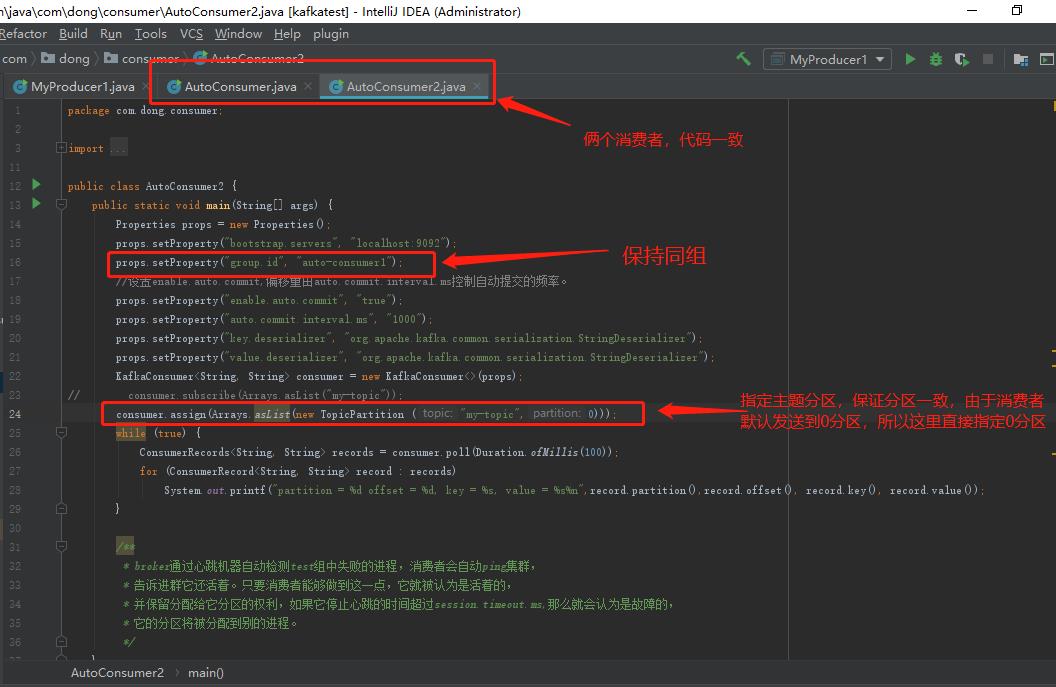
先运行俩个消费者,在运行生产者,效果如下:

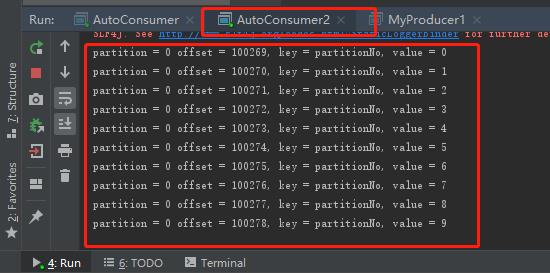
可以发现,明明前面同主题同组只有一个能接收到,这里一旦指定了消费者订阅的分区,同组的也能收到同一主题的同一消息.(我觉得这应该验证了我说的,同组定阅同一主题消息不会被同时收到只是发生在kafka分配消费者分区时, 而不是在分区分发消息时判断,因此一旦不适用kafka的自动分区分配,那么组id将失去意义)
总结:
不指定分区时,默认发送到 0 分区,指定分区时,只发送到指定分区 *订阅者一旦指定分区,则只能读到对应分区的内容,未指定分区,则会读到所有分区的内容 *自动创建主题时创建的分区数实在server.properties文件中配置的,num.partitions 默认为 1 *一旦手动指定同组的俩个消费者读取的分区一样,此时俩个消费者都能消费到消息。 *如果未手动指定,则同组用户只有一个能收到消息(因为kafka会默认平均将分区分给consumer, * 这也说明了为什么消费者数量要小于分区,否则会有消费者完全收不到消息) * * 因此如果想负载均衡 应该准备几个consumer,就创建几个分区。 且不指定分区。 producer应根据情况均匀的发送消息到每个partition * 如果想实现topic模式,所有消费者都能收到相同的消息,那么 consumer就指定相同的分区,或者不同的group id,订阅同一个主题即可 **/以上是关于kafka java(api)的主要内容,如果未能解决你的问题,请参考以下文章