一文看懂Go语言协程的设计与原理
Posted 码农在新加坡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂Go语言协程的设计与原理相关的知识,希望对你有一定的参考价值。
首发于微信公众号:【码农在新加坡】,欢迎关注。
个人博客网站:一文看懂Go语言协程的设计与原理
背景
Go语言最大的特色就是从语言层面支持并发(Goroutine),Goroutine是Go中最基本的执行单元。事实上每一个Go程序至少有一个Goroutine:main Goroutine。Go 程序从 main 包的 main() 函数开始,在程序启动时,Go 程序就会为 main() 函数创建一个默认的 goroutine。
为了了解Go语言协程的设计,我们从历史设计出发,来看看最终Goroutine怎么一步一步到现在的设计的。
单进程时代
早期的操作系统每个程序就是一个进程,操作系统在一段时间只能运行一个进程,直到这个进程运行完,才能运行下一个进程,这个时期可以成为单进程时代——串行时代。
如图:进程之间串行执行,A、B、C 三个进程按顺序执行。

单进程时代的两个问题:
- 单一执行流程、计算机只能一个任务一个任务的处理。
- 进程阻塞所带来的CPU浪费时间是不可避免的(如进程A阻塞了,然后CPU是单进程没有任何的切换能力,但是需要等待进程A结束后才能执行下个进程)
遇到这种问题,我们怎么才能充分利用CPU呢?
多进程时代
后来操作系统就具有了最早的并发能力:多进程并发,当一个进程阻塞的时候,切换到另外等待执行的进程,这样就能尽量把CPU利用起来,CPU就不浪费了。
在多进程时代,有了时间片的概念,进程按照调度算法分时间片在 CPU 上执行,A、B、C 三个进程按照时间片并发执行。(调度算法)
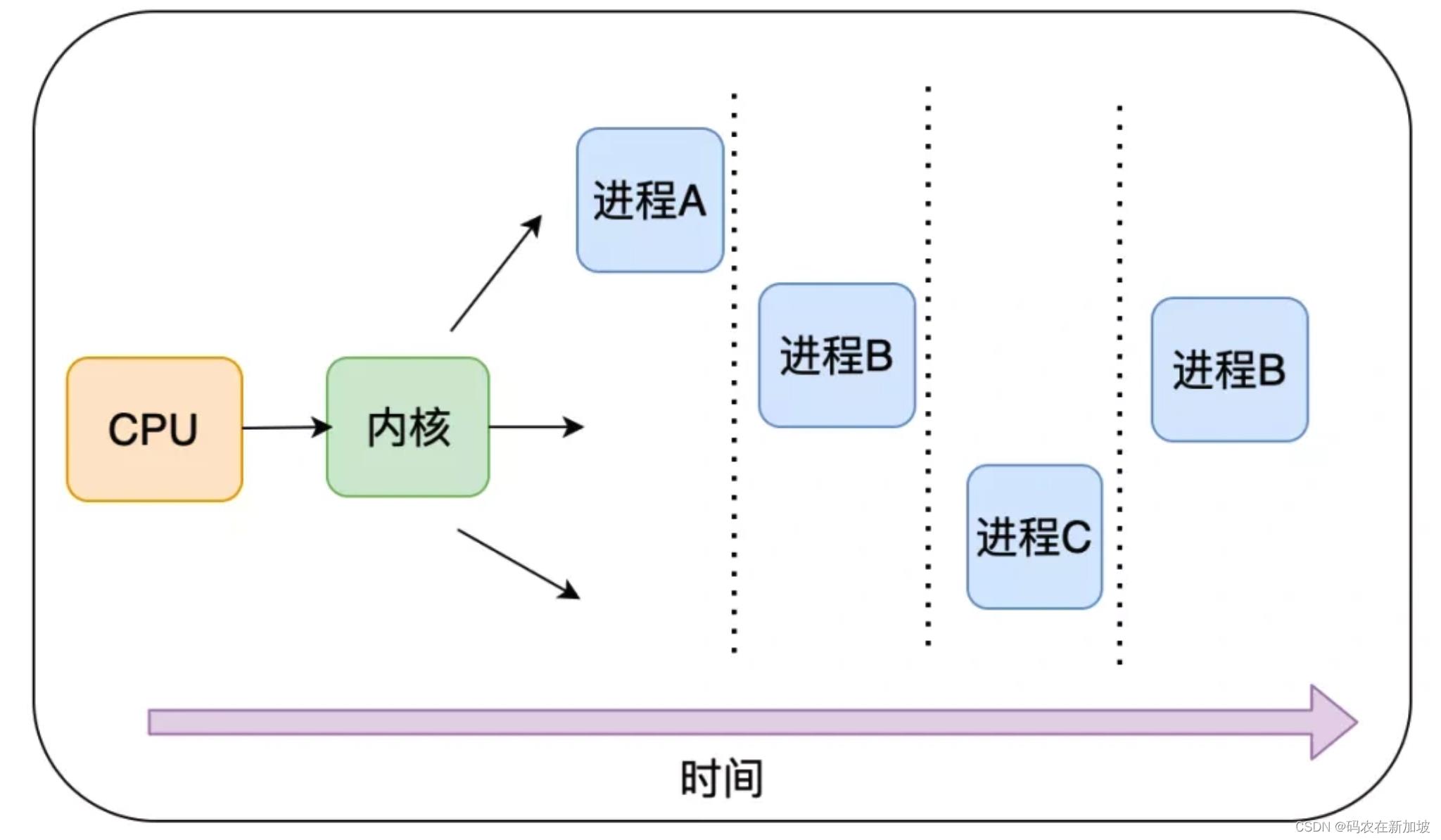
这样做有两个优点:
- 对于单个核可以并发执行多个进程,应用场景更加丰富,
- 当某个进程 IO 阻塞时,也能保证 CPU 的利用率。
但是随着时代的发展,CPU 通过进程来进行调度的缺点也越发的明显。
进程切换需要:
- 切换页目录以使用新的地址空间
- 切换内核栈和硬件上下文
因为进程拥有太多资源,在创建、切换和销毁的时候,都会占用很长的时间,CPU虽然利用起来了,但CPU有很大的一部分都被用来进行进程调度了。
怎么才能提高CPU的利用率呢?
多线程时代
所以,轻量级的进程:线程诞生了。线程运行所需要的资源比进程少多了。
对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
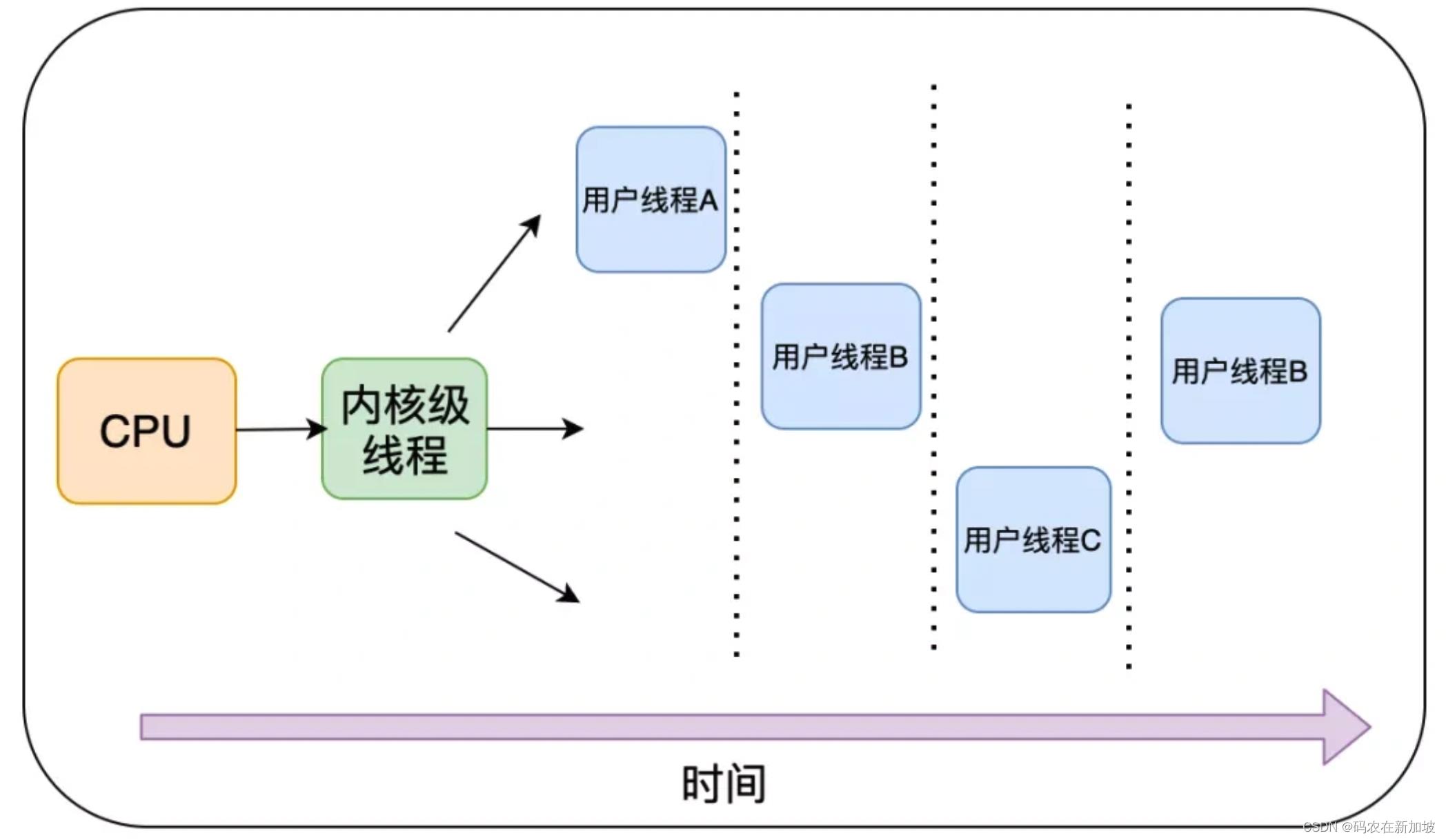
线程是CPU调度的最小单位, 进程是资源分配的最小单位。
- 进程:进程是资源分配的最小单位,进程在执行过程中拥有独立的内存单元。
- 线程:线程是CPU调度的最小单位,线程切换只须保存和设置少量寄存器的内容。
虽然线程比较轻量,但是在调度时也有比较大的额外开销。每个线程会都占用 1M 以上的内存空间,在切换线程时不止会消耗较多的内存,恢复寄存器中的内容还需要向操作系统申请或者销毁资源。
多进程、多线程已经提高了系统的并发能力,但是在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,因为每个线程需要有自己的栈空间,大量的线程需要占用大量的内存空间,同时线程的数量还受系统参数threads-max等参数的限制。
有没有更轻量级的线程来支持当今互联网的高并发场景呢。如何才能充分利用CPU、内存等资源的情况下,实现更高的并发?
协程时代
协程作为用户态线程,也是轻量级的线程,用来解决高并发场景下线程切换的资源开销。
你可能知道:线程分为内核态线程和用户态线程,用户态线程需要绑定内核态线程,CPU并不能感知用户态线程的存在,它只知道它在运行1个线程,这个线程实际是内核态线程。
用户态线程实际有个名字叫协程(co-routine),为了容易区分,我们使用协程指用户态线程,使用线程指内核态线程。
协程跟线程是有区别的
- 线程/进程是内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法)
- 协程 对内核是透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行 协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
协程的调度
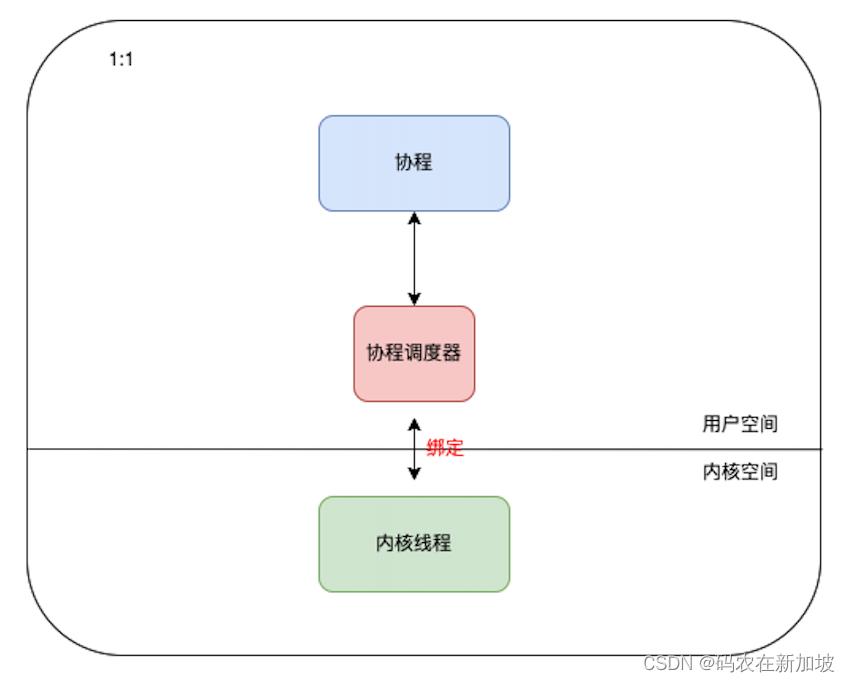
1:1 调度
1个协程绑定1个线程,这种最容易实现。协程的调度都由CPU完成了,但有一个缺点是协程的创建、删除和切换的代价都由CPU完成,上下文切换很慢,同等于线程切换。
N:1 调度
N个协程绑定1个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1个进程的所有协程都绑定在1个线程上,一是某个程序用不了硬件的多核加速能力,二是一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。

M:N 调度
M个协程绑定N个线程,是N:1和1:1类型的结合,克服了以上2种模型的缺点,但实现起来最为复杂。

go语言协程调度
Go runtime的调度器
Go 语言的调度器通过使用与 CPU 数量相等的线程减少线程频繁切换的内存开销,同时在每一个线程上执行额外开销更低的 Goroutine 来降低操作系统和硬件的负载。
而每个goroutine非常轻量级,只占几KB的内存,这就能在有限的内存空间内支持大量goroutine,支持了更多的并发。虽然一个goroutine的栈只占几KB,但实际是可伸缩的,如果需要更多内容,runtime会自动为goroutine分配。
goroutine建立在操作系统线程基础之上,它与操作系统线程之间实现了一个多对多(M:N)的两级线程模型。
这里的 M:N 是指M个goroutine运行在N个内核线程之上,内核负责对这N个操作系统线程进行调度,而这N个系统线程又通过goroutine调度器负责对这M个goroutine进行调度和运行。
G-M模型
Go1.0的协程是G-M模型
- G指Goroutine,本质上是轻量级线程,包括了调用栈,重要的调度信息,例如channel
- M指Machine,一个M关联一个内核OS线程,由操作系统管理。

M(内核线程)想要执行、放回G都必须访问全局G队列,并且M有多个,即多线程访问同一资源需要加锁进行保证互斥/同步,所以全局G队列是有互斥锁进行保护的。
这个调度器有几个缺点:
- 存在单一全局互斥锁和集中状态。全局锁保护所有 goroutine 相关操作(如:创建、完成、重新调度等),导致锁竞争问题严重;
- goroutine 传递问题:经常在 M 之间传递“可运行”的 goroutine,这导致调度延迟增大;
- 每个线程 M 都需要做内存缓存(M.mcache),导致内存占用过高,且数据局部性较差;
- 系统调用频繁地阻塞和解除阻塞正在运行的线程,导致额外的性能损耗。
G-P-M模型
新的协程调度器引入了P(Processor),成为了完善的GPM模型。Processor,它包含了运行goroutine的资源,如果线程想运行goroutine,必须先获取P,P中还包含了可运行的G队列。

上图中各个模块的作用如下:
- 全局队列:存放等待运行G
- P的本地队列:和全局队列类似,存放的也是等待运行的G,存放数量上限256个。新建G时,
G优先加入到P的本地队列,如果队列满了,则会把本地队列中的一半G移动到全局队列 - P列表:所有的P都在程序启动时创建,保存在数组中,最多有GOMAXPROCS个,可通过runtime.GOMAXPROCS(N)修改,N表示设置的个数。
- M:每个M代表一个内核线程,操作系统调度器负责把内核线程分配到CPU的核心上执行。
简单的来说,一个G的执行需要M和P的支持。一个M在与一个P关联之后形成了一个有效的G运行环境【内核线程 + 上下文环境】。每个P都会包含一个可运行的G的队列 (runq )。
| 数据结构 | 数量 | 意义 | |
|---|---|---|---|
| G Goroutine | runtime.g 运行的函数指针,stack,寄存器等。 | 每次go func都代表一个G,无限制 | 代表一个用户代码执行流 |
| P Processor | runtime.p 运行G的上下文,调度器,包括mcache,runq和free g等。 | 默认为机器核数,可通过 GOMAXPROCS 环境变量调整。 | 表示执行所需的资源 |
| M Machine | runtime.m 对应一个内核线程 | 比P多,M的最大数量可以进行设置,这个初始值是10000 | 代表执行者,底层线程 |
调度策略:
调度器核心思想是尽可能避免频繁的创建、销毁线程,对线程进行复用以提高效率。
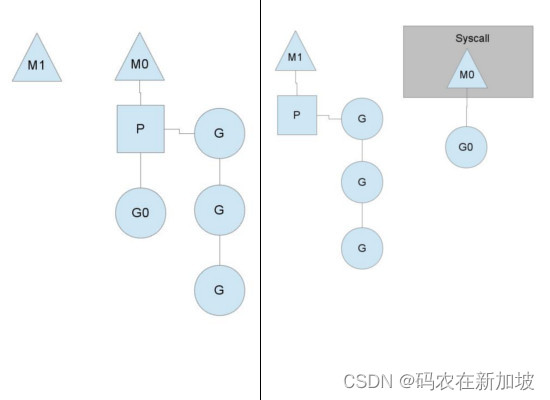
- work stealing机制(窃取式)
当本线程无G可运行时,从其他线程绑定的P窃取G,而不是直接销毁线程。

- hand off机制
当本线程M1因为G进行的系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的M0执行。
抢占
一个goroutine最多占用CPU 10ms,防止其他goroutine等待太久得不到执行被“饿死”。
全局G队列
全局G队列是有互斥锁保护的,访问需要竞争锁,新的调度器将其功能弱化了,当M执行work stealing从其他P窃取不到G时,才会去全局G队列获取G。
总结
本文只是从历史和宏观角度解释了Goroutine的设计原理,当然具体的代码实现远比这个复杂。后续会继续更新Go语言协程的源码到底是怎么实现的。
P的作用是什么?
对比我们可以发现:
- G-M模型 起初的Go并发性能并不十分亮眼,协程和系统线程的调度比较粗暴,导致很多性能问题,如全局资源锁、M的内存过高等造成许多性能损耗。
- G-P-M模型 加入P的设计之后实现了一个通过 work stealing 的调度算法:由P来维护Goroutine队列并选择一个适当的M绑定。P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P的数量决定了系统内最大可并行的G的数量。
goroutine存在的意义是什么?
goroutine 的存在必然是为了换个方式解决操作系统线程的一些弊端
- 创建和切换太重 操作系统线程的创建和切换都需要进入内核,而进入内核所消耗的性能代价比较高,开销较大;
- 内存使用太重 内核在创建操作系统线程时默认会为其分配一个较大的栈内存,内核在创建操作系统线程时默认会为其分配一个较大的栈内存,同时会有溢出的风险;
goroutine的优势也就是 开销小
- goroutine是用户态线程,其创建和切换都在用户代码中完成而无需进入操作系统内核,所以其开销要远远小于系统线程的创建和切换;
- goroutine启动时默认栈大小只有2k,这在多数情况下已经够用了,即使不够用,goroutine的栈也会自动扩大,同时,如果栈太大了过于浪费它还能自动收缩,这样既没有栈溢出的风险,也不会造成栈内存空间的大量浪费。
其他语言的协程
协程是个好东西,不少语言支持了协程,比如:Lua、Erlang,就算语言不支持,也有库支持协程,比如C语言的coroutine、Java的coroutines、C++的libco和libgo、Kotlin的kotlinx.coroutines、Python的gevent。
<全文完>
欢迎关注我的微信公众号:【码农在新加坡】,有更多好的技术分享。
个人博客网站:一文看懂Go语言协程的设计与原理
以上是关于一文看懂Go语言协程的设计与原理的主要内容,如果未能解决你的问题,请参考以下文章